首页 > Python资料 博客日记
2024版蒲公英平台采集软件,批量爬取小红书优质博主!
2024-06-22 08:30:03Python资料围观212次
这篇文章介绍了2024版蒲公英平台采集软件,批量爬取小红书优质博主!,分享给大家做个参考,收藏Python资料网收获更多编程知识
一、背景介绍
1.0 爬取目标

众所周知,蒲公英是小红书推出的优质创作者商业合作服务平台,致力于为品牌和博主提供内容合作服务,可以高效的为品牌匹配出最符合的优质博主。
蒲公英平台,需要有一定权限的企业资质账号才能申请开通。开通之后,进入【寻找博主】页面,即可根据一定的筛选条件过滤出满足的博主列表,如下:
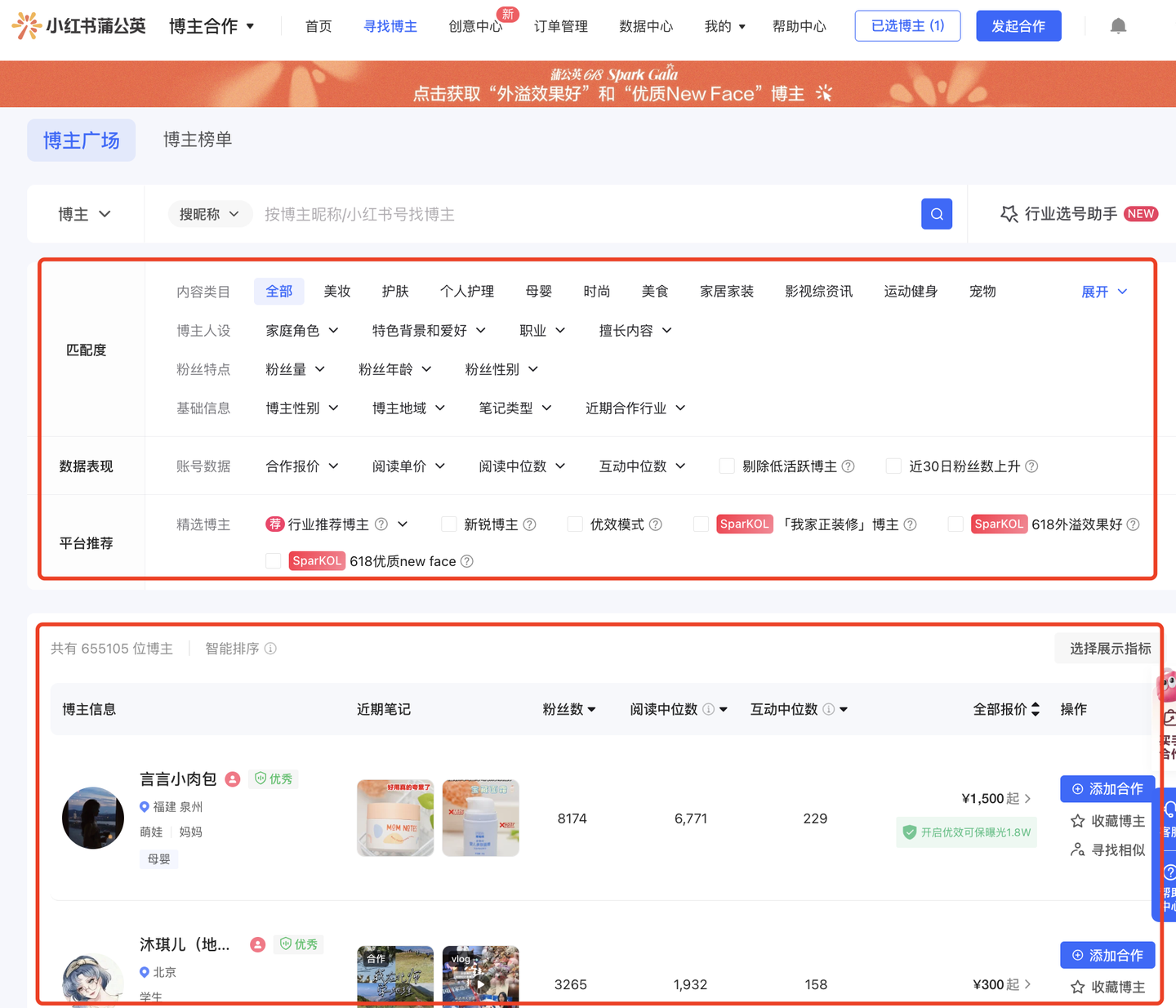
上面是筛选条件,下面是筛选结果。
爬虫功能分为2大类模块:第一是根据筛选条件爬取博主列表,第二是根据爬取到的博主id进入详情页面爬取详细数据,详情页如下:
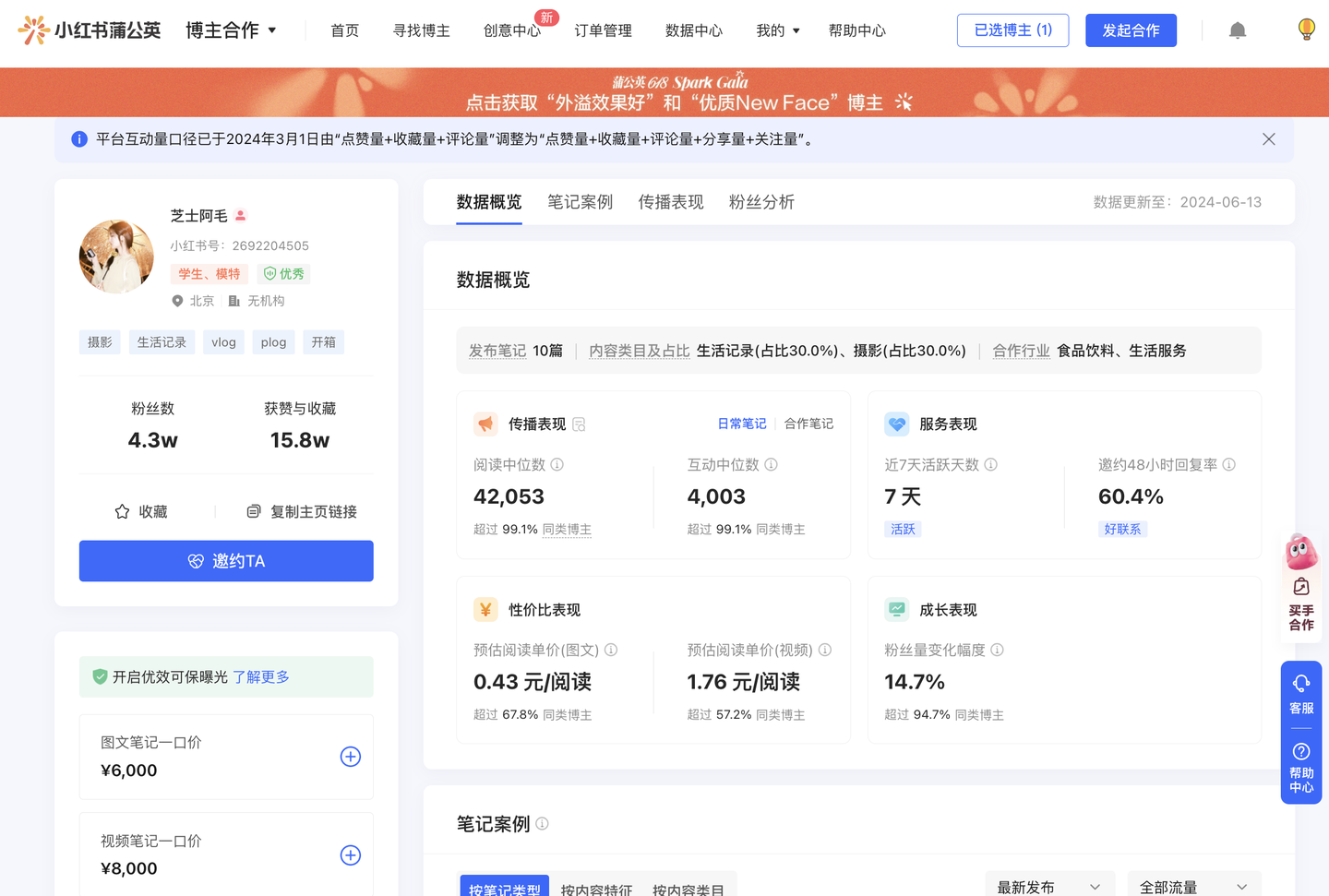
通过分析网页接口,开发出了爬虫GUI软件,界面如下:
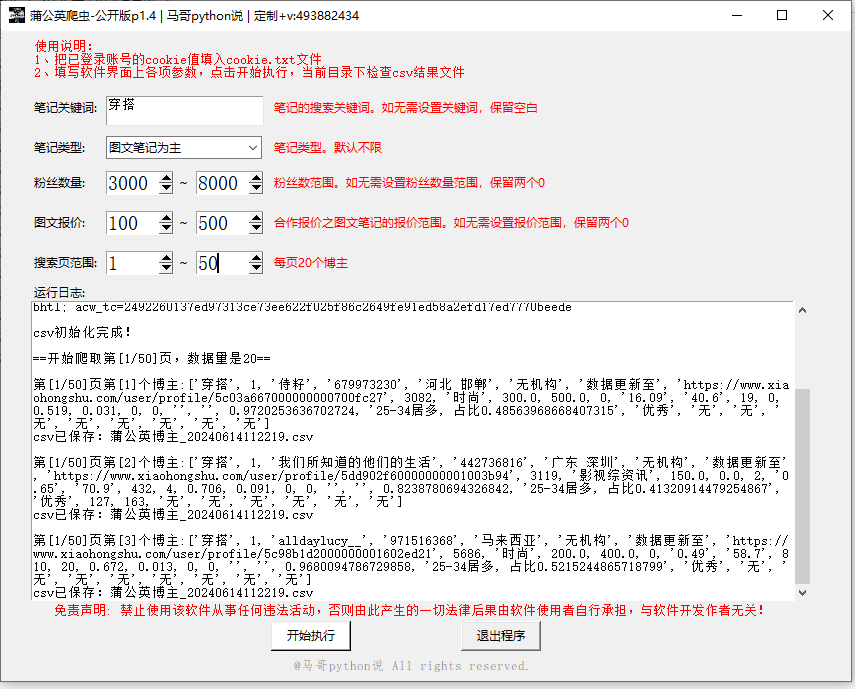
共爬取到34个字段,字段如下:
1 关键词
2 页码
3 小红书昵称
4 小红书号
5 地址
6 机构
7 数据更新至
8 小红书链接
9 粉丝数
10 账号类型
11 图文报价
12 视频报价
13 合作笔记数
14 预估阅读单价_图文
15 图文3秒阅读
16 日常_阅读中位数
17 日常_互动中位数
18 日常_阅读来源发现页占比
19 日常_阅读来源搜索页占比
20 合作_阅读中位数
21 合作_互动中位数
22 合作_阅读来源发现页占比
23 合作_阅读来源搜索页占比
24 女性粉丝占比
25 年龄占比最多的
26 账号评估
27 合作笔记1阅读数
28 合作笔记2阅读数
29 合作笔记3阅读数
30 合作笔记4阅读数
31 合作笔记5阅读数
32 合作笔记6阅读数
33 合作笔记7阅读数
34 合作笔记8阅读数
详细演示数据:(看《蒲公英》这个sheet页)
1.1 演示视频
软件操作演示视频:见原文
1.2 软件说明
重要说明,请详读:
- Windows用户可直接双击打开使用,无需Python运行环境,非常方便!
- 需要在cookie.txt中填入cookie值,持久存储,方便长期使用
- 支持筛选笔记搜索关键词、笔记类型(不限/图文笔记为主/视频笔记为主)、粉丝数量、图文报价、搜索页范围。其他个性化筛选条件,可以和我沟通定制
- 爬取过程中,有log文件详细记录运行过程,方便回溯
- 爬取过程中,自动保存结果到csv文件(每爬一条存一次,防止数据丢失)
- 可爬34个关键字段,含:关键词,页码,小红书昵称,小红书号,地址,机构,数据更新至,小红书链接,粉丝数,账号类型,图文报价,视频报价,合作笔记数,预估阅读单价_图文,图文3秒阅读,日常_阅读中位数,日常_互动中位数,日常_阅读来源发现页占比,日常_阅读来源搜索页占比,合作_阅读中位数,合作_互动中位数,合作_阅读来源发现页占比,合作_阅读来源搜索页占比,女性粉丝占比,年龄占比最多的,账号评估,合作笔记1阅读数,合作笔记2阅读数,合作笔记3阅读数,合作笔记4阅读数,合作笔记5阅读数,合作笔记6阅读数,合作笔记7阅读数,合作笔记8阅读数。
- 以上爬取字段已经包含,如无法满足个性化要求,可定制开发(接口已调通)
以上。
二、代码讲解
2.0 关于接口
由于采集字段较多,开发者模式中分析接口不止一个,采集程序整合多个接口开发而成,归纳如下:
- 博主列表接口
- 日常笔记接口
- 合作笔记接口
- 粉丝数接口
- 阅读单价接口
- 合作笔记阅读数接口
- 所属机构接口
以上。
2.1 爬虫采集模块
此软件开发成本较高,代码量大、实现逻辑复杂,为保护个人知识版权,防止恶意盗版软件,不展示爬虫核心代码。
2.2 cookie获取
运行软件之前,需要填写cookie值到txt配置文件中,获取方法如下:
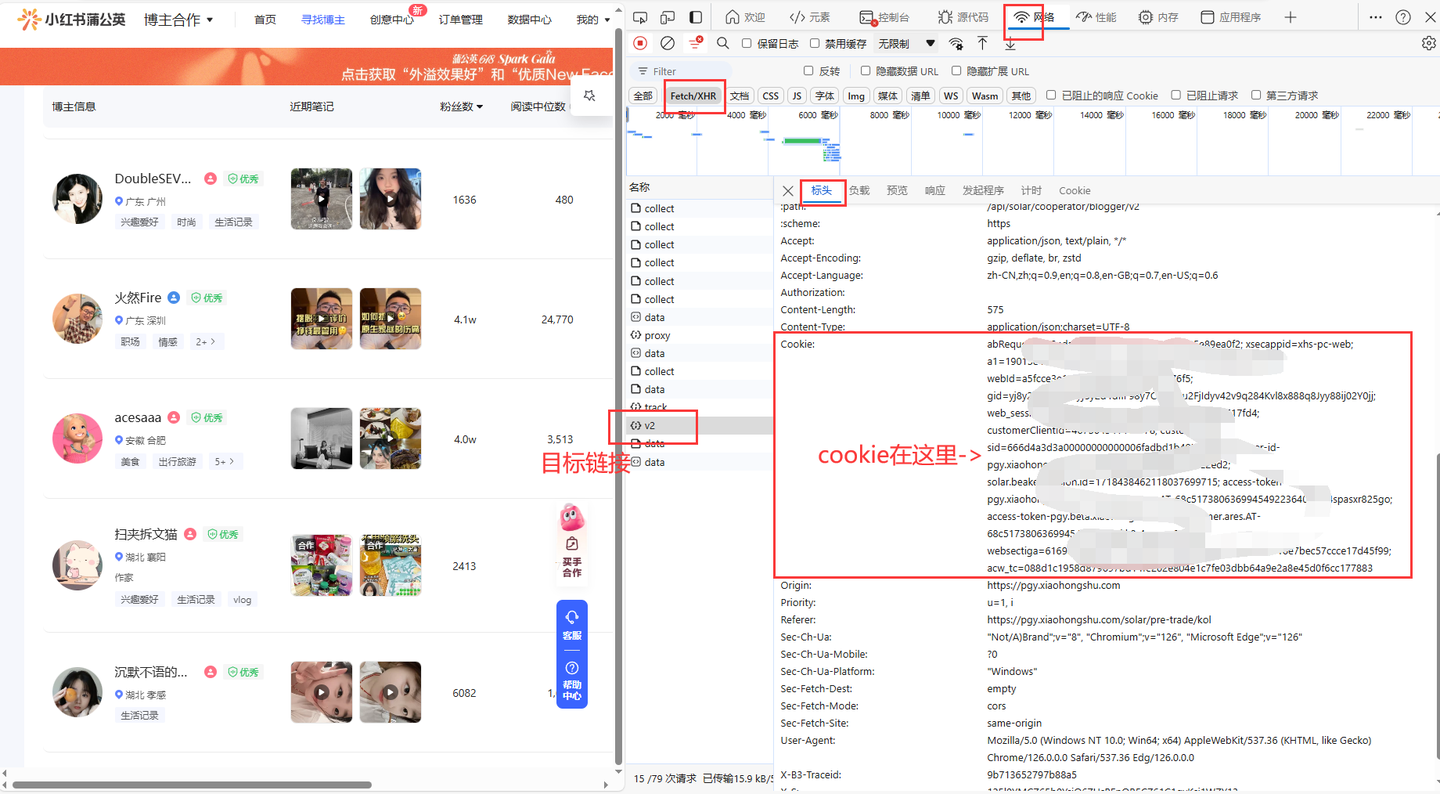
2.3 软件界面模块
主窗口部分:
# 创建主窗口
root = tk.Tk()
root.title('蒲公英爬虫-公开版p1.4 | 马哥python说 | 定制')
# 设置窗口大小
root.minsize(width=850, height=650)
部分界面控件:
# 笔记关键词
tk.Label(root, justify='left', text='笔记关键词:').place(x=30, y=65)
entry_kw = tk.Text(root, bg='#ffffff', width=22, height=2, )
entry_kw.place(x=105, y=65, anchor='nw') # 摆放位置
日志输出控件:
# 运行日志
tk.Label(root, justify='left', text='运行日志:').place(x=30, y=250)
show_list_Frame = tk.Frame(width=780, height=300) # 创建<消息列表分区>
show_list_Frame.pack_propagate(0)
show_list_Frame.place(x=30, y=270, anchor='nw') # 摆放位置
2.4 日志模块
好的日志功能,方便软件运行出问题后快速定位原因,修复bug。
核心代码:
def get_logger(self):
self.logger = logging.getLogger(__name__)
# 日志格式
formatter = '[%(asctime)s-%(filename)s][%(funcName)s-%(lineno)d]--%(message)s'
# 日志级别
self.logger.setLevel(logging.DEBUG)
# 控制台日志
sh = logging.StreamHandler()
log_formatter = logging.Formatter(formatter, datefmt='%Y-%m-%d %H:%M:%S')
# info日志文件名
info_file_name = time.strftime("%Y-%m-%d") + '.log'
# 将其保存到特定目录
case_dir = r'./logs/'
info_handler = TimedRotatingFileHandler(filename=case_dir + info_file_name,
when='MIDNIGHT',
interval=1,
backupCount=7,
encoding='utf-8')
软件运行过程中生成的日志文件:
三、转载声明
转载已获原作者@马哥python说授权:
博客园原文链接: 【GUI软件】小红书蒲公英数据批量爬取!高效筛选优质博主,助力品牌商!
版权声明:本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若内容造成侵权/违法违规/事实不符,请联系邮箱:jacktools123@163.com进行投诉反馈,一经查实,立即删除!
标签:
相关文章
最新发布
- 光流法结合深度学习神经网络的原理及应用(完整代码都有Python opencv)
- Python 图像处理进阶:特征提取与图像分类
- 大数据可视化分析-基于python的电影数据分析及可视化系统_9532dr50
- 【Python】入门(运算、输出、数据类型)
- 【Python】第一弹---解锁编程新世界:深入理解计算机基础与Python入门指南
- 华为OD机试E卷 --第k个排列 --24年OD统一考试(Java & JS & Python & C & C++)
- Python已安装包在import时报错未找到的解决方法
- 【Python】自动化神器PyAutoGUI —告别手动操作,一键模拟鼠标键盘,玩转微信及各种软件自动化
- Pycharm连接SQL Sever(详细教程)
- Python编程练习题及解析(49题)
点击排行
- 版本匹配指南:Numpy版本和Python版本的对应关系
- 版本匹配指南:PyTorch版本、torchvision 版本和Python版本的对应关系
- Python 可视化 web 神器:streamlit、Gradio、dash、nicegui;低代码 Python Web 框架:PyWebIO
- 相关性分析——Pearson相关系数+热力图(附data和Python完整代码)
- Anaconda版本和Python版本对应关系(持续更新...)
- Python与PyTorch的版本对应
- Windows上安装 Python 环境并配置环境变量 (超详细教程)
- Python pyinstaller打包exe最完整教程
本站推荐
