首页 > Python资料 博客日记
【Python特征工程系列】利用SHAP进行特征重要性分析-决策树模型为例(案例+源码)
2024-06-24 11:00:03Python资料围观691次
这是我的第290篇原创文章。
一、引言
SHAP 属于模型事后解释的方法,它的核心思想是计算特征对模型输出的边际贡献,再从全局和局部两个层面对“黑盒模型”进行解释。SHAP构建一个加性的解释模型,所有的特征都视为“贡献者”。
对于每个预测样本,模型都产生一个预测值,SHAP value就是该样本中每个特征所分配到的数值。
基本思想:计算一个特征加入到模型时的边际贡献,然后考虑到该特征在所有的特征序列的情况下不同的边际贡献,取均值,即某该特征的SHAP baseline value
SHAP值就是一种帮助我们理解机器学习模型是如何做出预测的工具,它通过分析每个特征对预测结果的影响,让我们能够更清楚地看到模型是如何“思考”的。
通过计算SHAP值,我们可以:
-
解释单个预测:了解每个特征如何影响单个样本的模型预测。
-
全局解释:通过平均多个样本的SHAP值,了解特征对模型预测的总体影响。
-
特征选择:识别对模型预测最重要的特征。
本文展示了如何使用条形图和蜂群图来可视化全局特征重要性。
二、实现过程
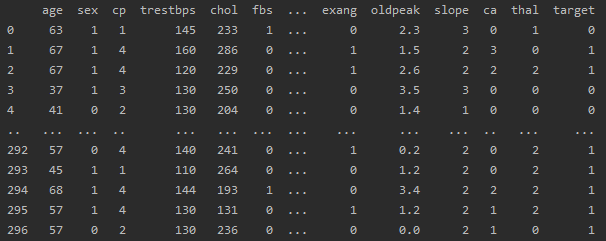
2.1 准备数据
# 准备数据
data = pd.read_csv(r'dataset.csv')
df = pd.DataFrame(data)
# 提取目标变量和特征变量
target = 'target'
features = df.columns.drop(target)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(df[features], df[target], test_size=0.2, random_state=0)df:
2.2 模型训练
# 模型的构建与训练
model = DecisionTreeClassifier()
model.fit(X_train, y_train)2.3 创建SHAP解释器
# 创建Explainer
explainer = shap.TreeExplainer(model, X_test)
# 以numpy数组的形式输出SHAP值
shap_values = explainer.shap_values(X_test)
print(shap_values) # shap_values = shap_obj.values
# # 以SHAP的Explanation对象形式输出SHAP值
shap_obj = explainer(X_test)
print(shap_obj.values)shap_values是一个三维数组(60, 13, 2),60样本,13特征,2个类别的shap值,
shap_values[0]是一个二维数组(13,2)是第1个样本13特征,2个类别的shap值,shap_values[1]是一个二维数组(13,2)是第2个样本13特征,2个类别的shap值,
shap_values[0][0]是一个一维数组(2,)是第1个样本第1个特征,2个类别的shap值,shap_values[1][0]是一个一维数组(13,2)是第2个样本第一个特征,2个类别的shap值,
shap_values[0][0][0]是一个数值(),表示第1个样本第1个特征第1类别的shap值,shap_values[0][0][1]是一个数值,表示第1个样本第1个特征,第2个类别的shap值。
shap_values[:,:,0]是一个二维数组(60,13),表示60个样本,13个特征第一个类别的shap值。
2.4 绘制全局条形图
SHAP提供了一种全局特征重要性图的方法,这种方法考虑了所有样本,并计算每个特征的平均绝对SHAP值:
shap.summary_plot(shap_values, X_test)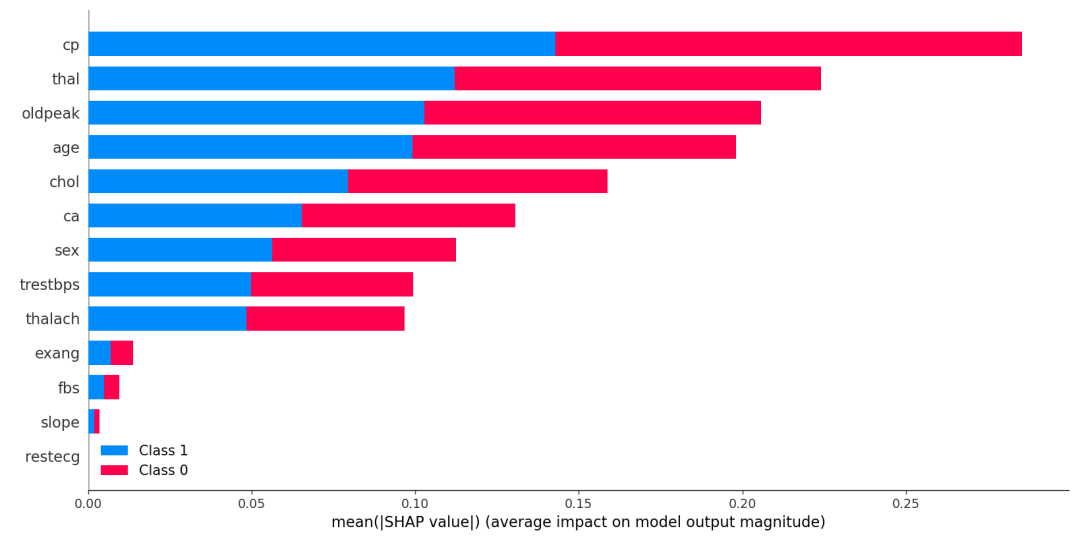
这个图在低版本的shap能够跑出来,在高版本的shap中可能报错,可以用下面的函数替代:
shap.plots.bar(shap_obj[:,:,0])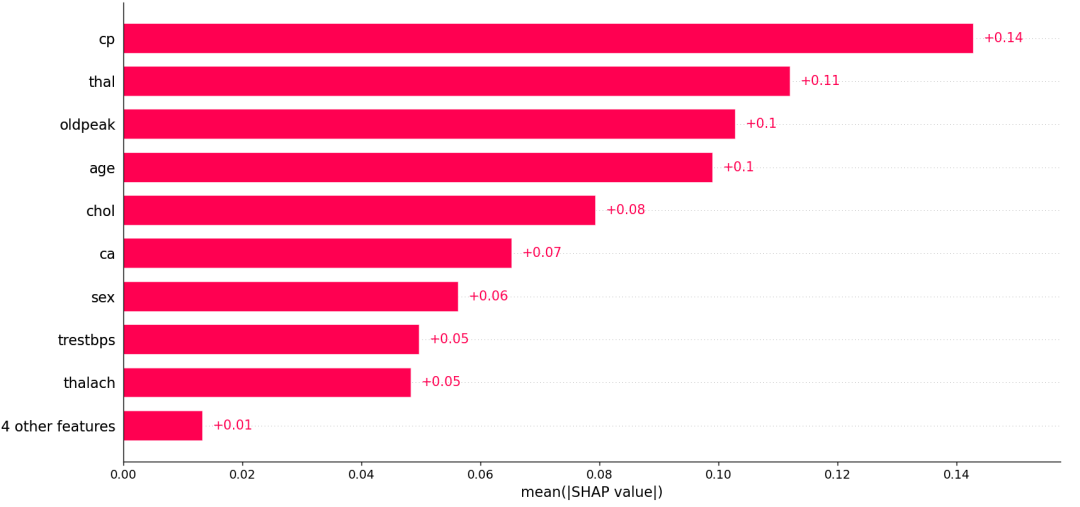
2.5 绘制全局蜂群图
蜂群图(Beeswarm Plot)是另一种可视化特征重要性和影响的方法。蜂群图旨在显示数据集中的TOP特征如何影响模型输出的信息密集摘要。
shap.plots.beeswarm(shap_obj[:,:,0], show=True) # 全局蜂群图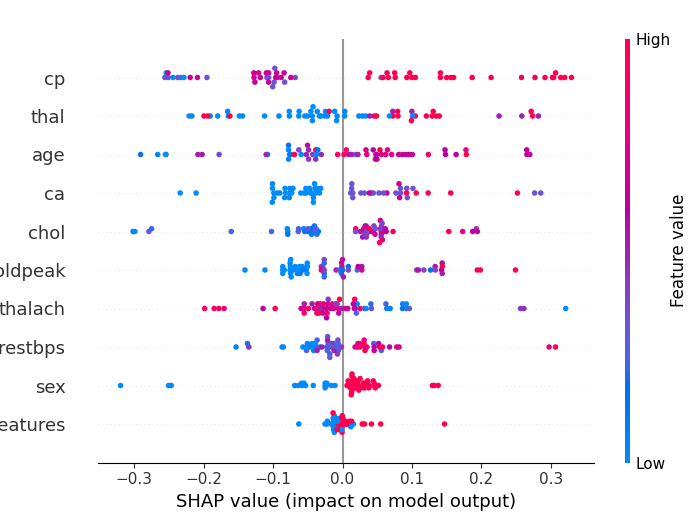
给定解释的每个实例由每个特征流上的一个点表示;点的 x 位置由该特征的 SHAP 值 ( shap_values.value[instance,feature]) 确定,并且点沿每个特征行“堆积”以显示密度;
条形图与蜂群图的对比,条形图就只是展示了蜂群图的平均值。
作者简介:
读研期间发表6篇SCI数据挖掘相关论文,现在某研究院从事数据算法相关科研工作,结合自身科研实践经历不定期分享关于Python、机器学习、深度学习、人工智能系列基础知识与应用案例。致力于只做原创,以最简单的方式理解和学习,关注我一起交流成长。需要数据集和源码的小伙伴可以关注底部公众号添加作者微信。
标签:
相关文章
最新发布
- 光流法结合深度学习神经网络的原理及应用(完整代码都有Python opencv)
- Python 图像处理进阶:特征提取与图像分类
- 大数据可视化分析-基于python的电影数据分析及可视化系统_9532dr50
- 【Python】入门(运算、输出、数据类型)
- 【Python】第一弹---解锁编程新世界:深入理解计算机基础与Python入门指南
- 华为OD机试E卷 --第k个排列 --24年OD统一考试(Java & JS & Python & C & C++)
- Python已安装包在import时报错未找到的解决方法
- 【Python】自动化神器PyAutoGUI —告别手动操作,一键模拟鼠标键盘,玩转微信及各种软件自动化
- Pycharm连接SQL Sever(详细教程)
- Python编程练习题及解析(49题)
点击排行
- 版本匹配指南:Numpy版本和Python版本的对应关系
- 版本匹配指南:PyTorch版本、torchvision 版本和Python版本的对应关系
- Python 可视化 web 神器:streamlit、Gradio、dash、nicegui;低代码 Python Web 框架:PyWebIO
- 相关性分析——Pearson相关系数+热力图(附data和Python完整代码)
- Anaconda版本和Python版本对应关系(持续更新...)
- Python与PyTorch的版本对应
- Windows上安装 Python 环境并配置环境变量 (超详细教程)
- Python pyinstaller打包exe最完整教程
本站推荐
