首页 > Python资料 博客日记
difflib 标准库详解:Python 文本对比的利器
2024-06-26 14:00:04Python资料围观317次
这篇文章介绍了difflib 标准库详解:Python 文本对比的利器,分享给大家做个参考,收藏Python资料网收获更多编程知识
🍀 前言
博客地址:
👋 简介
difflib模块是Python标准库中的一个模块,用于比较文本之间的差异。它提供了一些函数和类,可以帮助你找到两个字符串或列表之间的相似性和差异性。
📖 正文
1 匹配最大相似内容
语法:difflib.get_close_matches(word, possibilities, n=3, cutoff=0.6)
参数说明:
word:要匹配的目标字符串;possibilities:包含可能匹配项的列表;n:可选参数,指定返回的最大匹配项数,默认为 3;cutoff:可选参数,表示匹配度的阈值,只返回匹配度大于等于该阈值的项,默认为 0.6。
函数会返回一个列表,其中包含了与目标字符串最相似的项。它会基于 difflib 库中的模糊匹配算法,找到给定字符串在候选列表中的可能匹配项。
import difflib
colors = ['red', 'blue', 'green', 'yellow', 'black', 'white']
wrong_color = "grren"
result = difflib.get_close_matches(wrong_color, colors)
print(result)
# ['green']
2 两个文本之间的差异
2.1 context_diff
语法:difflib.context_diff(a, b, fromfile='', tofile='', fromfiledate='', tofiledate='', n=3, lineterm='\n')
参数说明:
a:第一个文本内容(通常为列表形式,每行作为一个元素);b:第二个文本内容(同样通常为列表形式);fromfile:可选参数,用于指定第一个文件名;tofile:可选参数,用于指定第二个文件名;fromfiledate:可选参数,用于指定第一个文件的日期;tofiledate:可选参数,用于指定第二个文件的日期;n:可选参数,用于指定上下文的行数;lineterm:可选参数,用于指定行终止符,默认为\n。
函数会返回一个生成器,可以逐行输出表示差异的文本。该差异文本遵循标准的 Unix 上下文 diff 格式,显示出两个文本之间的差异以及周围的上下文信息。
import difflib
text1 = ['Hello', 'World', 'Python']
text2 = ['Hello', 'There', 'Python']
diff = difflib.context_diff(text1, text2, fromfile='file1.txt', tofile='file2.txt')
for line in diff:
print(line)
# *** file1.txt
# --- file2.txt
# ***************
# *** 1,3 ****
# Hello
# ! World
# Python
# --- 1,3 ----
# Hello
# ! There
# Python
2.2 nidff
语法:difflib.ndiff(a, b)
参数说明:
a:第一个文本内容(通常为列表形式,每行作为一个元素);b:第二个文本内容(同样通常为列表形式)。
这个函数会返回一个生成器,可以逐行输出表示差异的文本。相比较 context_diff,ndiff 会以更加紧凑的格式展示每行文本的差异,使用特定的标记符号来表示新增、删除和修改等操作。
import difflib
text1 = ['Hello', 'World', 'Python']
text2 = ['Hello', 'There', 'Python']
diff = difflib.ndiff(text1, text2)
for line in diff:
print(line)
# Hello
# - World
# + There
# Python
在使用difflib.ndiff进行对比,结果中的符号意义如下:
| 符号 | 含义 |
|---|---|
| ‘-’ | 包含在第一个系列行中,但不包含第二个。 |
| ‘+’ | 包含在第二个系列行中,但不包含第一个。 |
| ’ ’ | 两个系列行一致。 |
| ‘?’ | 存在增量差异。 |
| ‘^’ | 存在差异字符。 |
3 生成html对比结果
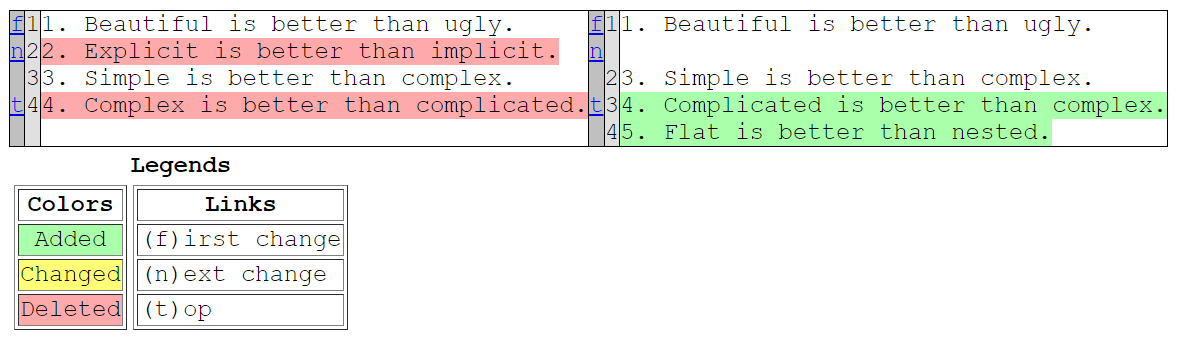
通过difflib.HtmlDiff()实现将对比结果生成html页面进行展示。
import difflib
text1 = '''1. Beautiful is better than ugly.
2. Explicit is better than implicit.
3. Simple is better than complex.
4. Complex is better than complicated.
'''.splitlines(keepends=True)
text2 = '''1. Beautiful is better than ugly.
3. Simple is better than complex.
4. Complicated is better than complex.
5. Flat is better than nested.
'''.splitlines(keepends=True)
html_diff = difflib.HtmlDiff()
html_output = html_diff.make_file(text1, text2)
with open('diff_output.html', 'w') as f:
f.write(html_output)
4 工具类封装
import difflib
import os.path
import time
from typing import List
class DiffContent:
@classmethod
def _read_file(cls, file_path: str) -> List[str]:
"""
读取文件内容
:param file_path: 文件绝对路径
:return: 列表
"""
try:
with open(file_path, "rb") as f:
# 二进制方式读取文件内容,并转换为str类型
lines = f.read().decode('utf-8')
# 按行进行分割
text = lines.splitlines()
return text
except Exception as e:
print("ERROR: {}".format(str(e)))
@classmethod
def compare_diff_by_file(cls, file_1: str, file_2: str, save_path: str = '') -> None:
"""
对比文件内如差异,并输出html文件,文件名命名:compare_file1name_file2name.html
:param file_1:文件1
:param file_2:文件2
:param save_path:生成html文件路径(默认值为空,生成到当前目录)
:return:
"""
# 获取文件内容
file_1_content = cls._read_file(file_1)
file_2_content = cls._read_file(file_2)
# 创建比较器
compare = difflib.HtmlDiff()
res = compare.make_file(file_1_content, file_2_content)
# 获取输出html文件的绝对路径
file_1_name = os.path.basename(file_1).split('.')[0]
file_2_name = os.path.basename(file_2).split('.')[0]
if save_path:
out_file = '{}/compare_{}_{}.html'.format(save_path, file_1_name, file_2_name)
else:
out_file = 'compare_{}_{}.html'.format(file_1_name, file_2_name)
with open(out_file, 'w') as fp:
fp.writelines(res)
@classmethod
def compare_text(cls, src_text: str, target_text: str, save_path: str = '') -> None:
"""
比较给定的2个字符串,并输出html文件
:param src_text:
:param target_text:
:param save_path:生成html文件路径(默认值为空,生成到当前目录)
:return:
"""
compare = difflib.HtmlDiff()
compare_result = compare.make_file(src_text, target_text)
if save_path:
out_file = '{}/compare{}.html'.format(save_path, str(time.time()).split('.')[0])
else:
out_file = 'compare{}.html'.format(str(time.time()).split('.')[0])
with open(out_file, 'w') as f:
f.writelines(compare_result)
💖 欢迎关注我的公众号

版权声明:本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若内容造成侵权/违法违规/事实不符,请联系邮箱:jacktools123@163.com进行投诉反馈,一经查实,立即删除!
标签:
相关文章
最新发布
- 光流法结合深度学习神经网络的原理及应用(完整代码都有Python opencv)
- Python 图像处理进阶:特征提取与图像分类
- 大数据可视化分析-基于python的电影数据分析及可视化系统_9532dr50
- 【Python】入门(运算、输出、数据类型)
- 【Python】第一弹---解锁编程新世界:深入理解计算机基础与Python入门指南
- 华为OD机试E卷 --第k个排列 --24年OD统一考试(Java & JS & Python & C & C++)
- Python已安装包在import时报错未找到的解决方法
- 【Python】自动化神器PyAutoGUI —告别手动操作,一键模拟鼠标键盘,玩转微信及各种软件自动化
- Pycharm连接SQL Sever(详细教程)
- Python编程练习题及解析(49题)
点击排行
- 版本匹配指南:Numpy版本和Python版本的对应关系
- 版本匹配指南:PyTorch版本、torchvision 版本和Python版本的对应关系
- Python 可视化 web 神器:streamlit、Gradio、dash、nicegui;低代码 Python Web 框架:PyWebIO
- Anaconda版本和Python版本对应关系(持续更新...)
- 相关性分析——Pearson相关系数+热力图(附data和Python完整代码)
- Python与PyTorch的版本对应
- Windows上安装 Python 环境并配置环境变量 (超详细教程)
- Python pyinstaller打包exe最完整教程
本站推荐
