首页 > Python资料 博客日记
python 爬取携程全国旅游景点信息-2024.4.13
2024-07-07 16:00:05Python资料围观215次
Python资料网推荐python 爬取携程全国旅游景点信息-2024.4.13这篇文章给大家,欢迎收藏Python资料网享受知识的乐趣
1. 概述
携程网是中国领先的在线旅行服务公司,提供酒店预订、机票预订、旅游度假、商旅管理等服务。携程网上有大量的旅游景点和酒店信息,这些信息对于旅行者和旅游业者都有很大的价值。通过爬虫技术,我们可以从携程网上获取这些信息,并进行数据清洗、数据分析、数据可视化等操作,从而得到有用的洞察和建议。
2. 安装requests 库
在开始之前,请确保你已经安装了以下 Python 库:
requests:用于发送 HTTP 请求并获取网页内容。
你可以使用 pip 来安装这些库:
pip install requests 3. 爬取携程旅游网站数据
首先,我们需要确定要爬取的页面。 假设我们想要获取携程旅游网站上某个目的地的旅游信息。如下例如北京。
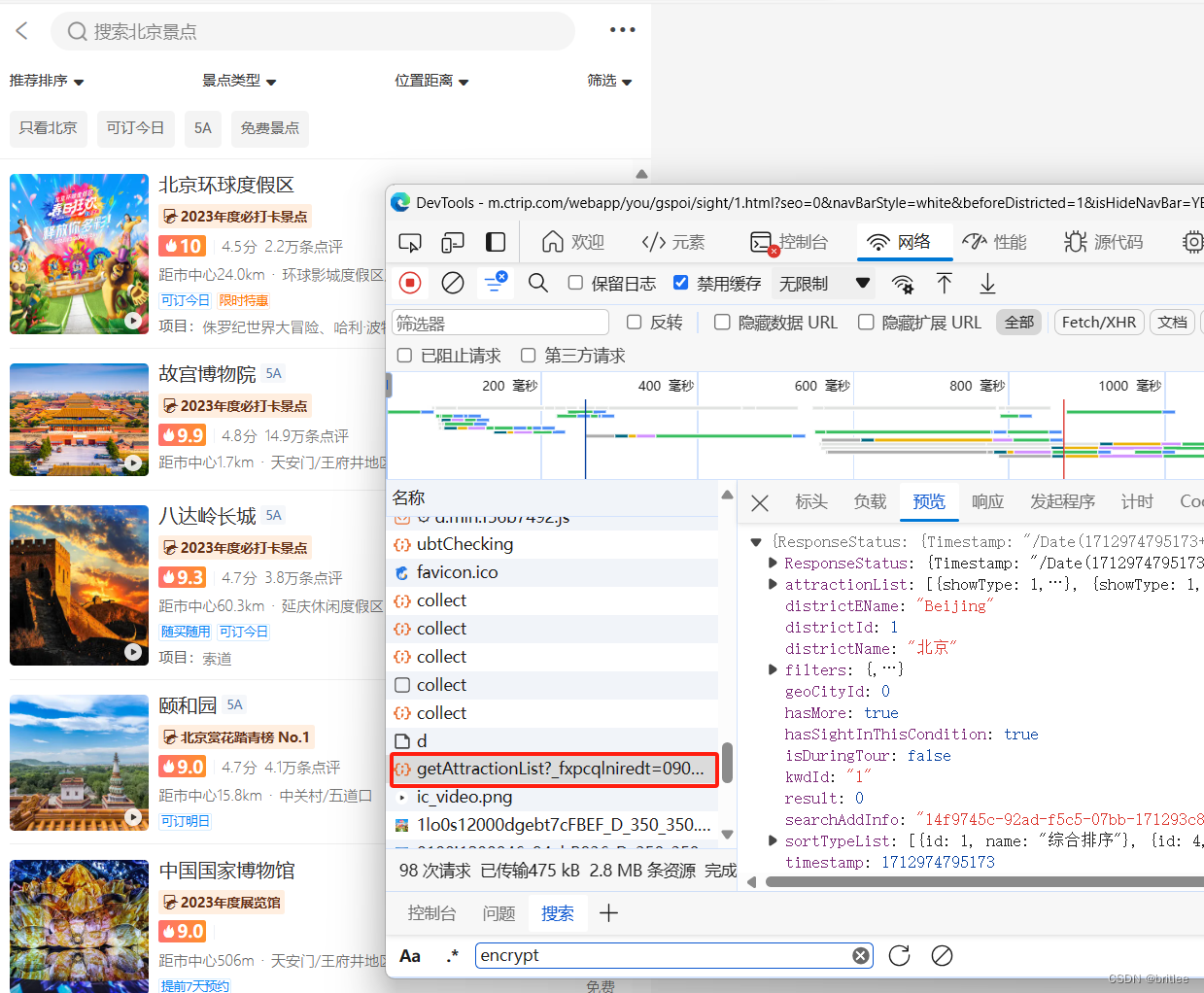
当前接口 链接 和 post 参数
url = 'https://m.ctrip.com/restapi/soa2/18109/json/getAttractionList?_fxpcqlniredt=09031015313388236487&x-traceID=09031015313388236487-1712974794650-8267936'
data = {"index":1,"count":10,"sortType":1,"isShowAggregation":true,"districtId":1,"scene":"DISTRICT","pageId":"214062","traceId":"14f9745c-92ad-f5c5-07bb-171293c80647","extension":[{"name":"osVersion","value":"10"},{"name":"deviceType","value":"windows"}],"filter":{"filterItems":[]},"crnVersion":"2020-09-01 22:00:45","isInitialState":true,"head":{"cid":"09031015313388236487","ctok":"","cver":"1.0","lang":"01","sid":"8888","syscode":"09","auth":"","xsid":"","extension":[]}}
4. 开始正式代码
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36 Edg/123.0.0.0',
'Cookie': 你的cookies
}
html = requests.post(url, headers=headers, json=data).json()
attractionList = html['attractionList']
for attraction in attractionList:
data = attraction['card']
commentCount = data['commentCount']
commentScore = data['commentScore']
coordinate = [data['coordinate']['latitude'], data['coordinate']['longitude']]
coverImageUrl = data.get('coverImageUrl','')
# 距离
distanceStr = data.get('distanceStr','')
# 地点
displayField = data.get('displayField', None)
heatScore = data.get('heatScore','')
# 景点名
poiName = data['poiName']
isFree = data['isFree']
if isFree:
price = 0
# 原价
marketPrice = 0
else:
price = data.get('price',0)
# 原价
marketPrice = data.get('marketPrice',0)
# 类别信息
sightCategoryInfo = data.get('sightCategoryInfo','')
# 标签
tagNameList = data.get('tagNameList','')
# 5a
sightLevelStr = data.get('sightLevelStr', None)5. 保存到csv
f = open('csv/全国各景点全.csv', 'w', encoding="utf-8", newline='')
csvwrite = csv.writer(f)
csvwrite.writerow(['城市', '景点名', '地点', '距离', '坐标', '评论数','评论分','热评分','封面','是否免费','价格','原价','类别信息','标签','是否5A'])
csvwrite.writerow([city,poiName,displayField,distanceStr,coordinate,commentCount,commentScore,heatScore,coverImageUrl,isFree,price,marketPrice,sightCategoryInfo,tagNameList,sightLevelStr])
6 .通过获取全国 city id,可请求全国景点数据并保存
 全国景点数据csv 地址 https://download.csdn.net/download/britlee/89115745
全国景点数据csv 地址 https://download.csdn.net/download/britlee/89115745
版权声明:本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若内容造成侵权/违法违规/事实不符,请联系邮箱:jacktools123@163.com进行投诉反馈,一经查实,立即删除!
标签:
相关文章
最新发布
- 光流法结合深度学习神经网络的原理及应用(完整代码都有Python opencv)
- Python 图像处理进阶:特征提取与图像分类
- 大数据可视化分析-基于python的电影数据分析及可视化系统_9532dr50
- 【Python】入门(运算、输出、数据类型)
- 【Python】第一弹---解锁编程新世界:深入理解计算机基础与Python入门指南
- 华为OD机试E卷 --第k个排列 --24年OD统一考试(Java & JS & Python & C & C++)
- Python已安装包在import时报错未找到的解决方法
- 【Python】自动化神器PyAutoGUI —告别手动操作,一键模拟鼠标键盘,玩转微信及各种软件自动化
- Pycharm连接SQL Sever(详细教程)
- Python编程练习题及解析(49题)
点击排行
- 版本匹配指南:Numpy版本和Python版本的对应关系
- 版本匹配指南:PyTorch版本、torchvision 版本和Python版本的对应关系
- Python 可视化 web 神器:streamlit、Gradio、dash、nicegui;低代码 Python Web 框架:PyWebIO
- 相关性分析——Pearson相关系数+热力图(附data和Python完整代码)
- Anaconda版本和Python版本对应关系(持续更新...)
- Python与PyTorch的版本对应
- Windows上安装 Python 环境并配置环境变量 (超详细教程)
- Python pyinstaller打包exe最完整教程
本站推荐
