首页 > Python资料 博客日记
Ubuntu系统下部署大语言模型:Ollama和OpenWebUI实现各大模型的人工智能自由
2024-08-20 15:00:10Python资料围观217次
之前在window下安装过 Ollama和OpenWebUI搭建本地的人工智能web项目(可以看我之前写的文章),无奈电脑硬件配置太低,用qwen32b就很卡,卡出PPT了,于是又找了一台机器安装linux系统,在linux系统下测试一下速度能否可以快一些。
系统硬件介绍
Ubuntu 22.04.4 LTS
CPU: i5-10400F
内存:32G
硬盘: 512G SSD
显卡: NVIDIA GeForce GTX 1060 6GB
内网IP: 192.168.1.21

下载 Ollama
访问下载: https://ollama.com/
安装Ollama
方法1、命令行下载安装(耗时长)
安装命令:
$ sudo apt install curl
$ curl -fsSL https://ollama.com/install.sh | sh

缺点: 国内网络环境要等很久
方法2 , 手动下载安装
1、手动下载 https://ollama.com/install.sh 这个文件
$ sudo mkdir ollama
cd ollama
$ sudo wget https://ollama.com/install.sh
2、注释掉下载部分 curl xxxx 手动下载ollama-linux-{ARCH}
$ sudo vim install.sh
修改文件:
status "Downloading ollama..."
#curl --fail --show-error --location --progress-bar -o $TEMP_DIR/ollama "https://ollama.com/download/ollama-linux-${ARCH}${VER_PARAM}"
我电脑intel/amd cpu 所以 {ARCH} = amd64
浏览器下载 https://ollama.com/download/ollama-linux-amd64 当然科学上网速度更快哟。 放在 install.sh 同目录下
3、注释掉 #$SUDO install -o0 -g0 -m755 $TEMP_DIR/ollama $BINDIR/ollama
改为下面一行:
$ sudo vim install.sh
修改文件:
status "Installing ollama to $BINDIR..."
$SUDO install -o0 -g0 -m755 -d $BINDIR
#$SUDO install -o0 -g0 -m755 $TEMP_DIR/ollama $BINDIR/ollama
$SUDO install -o0 -g0 -m755 ./ollama-linux-amd64 $BINDIR/ollama
4 运行 install.sh ,安装
sh ./install.sh
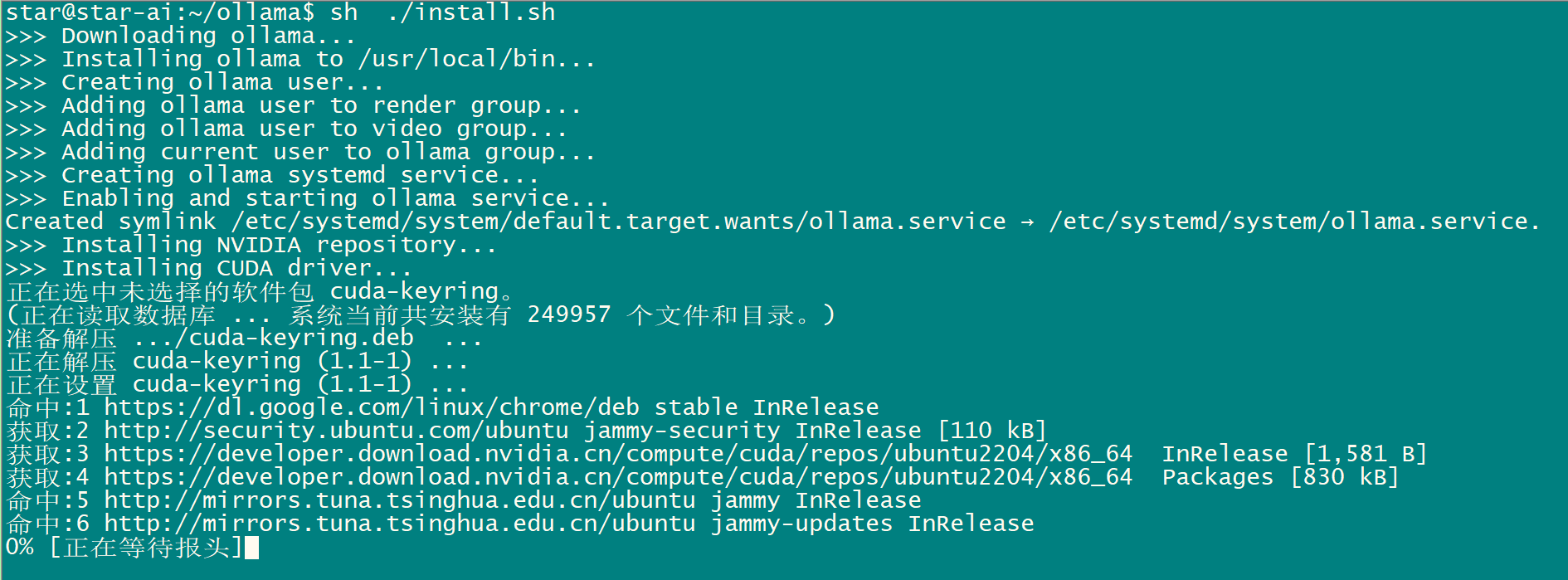
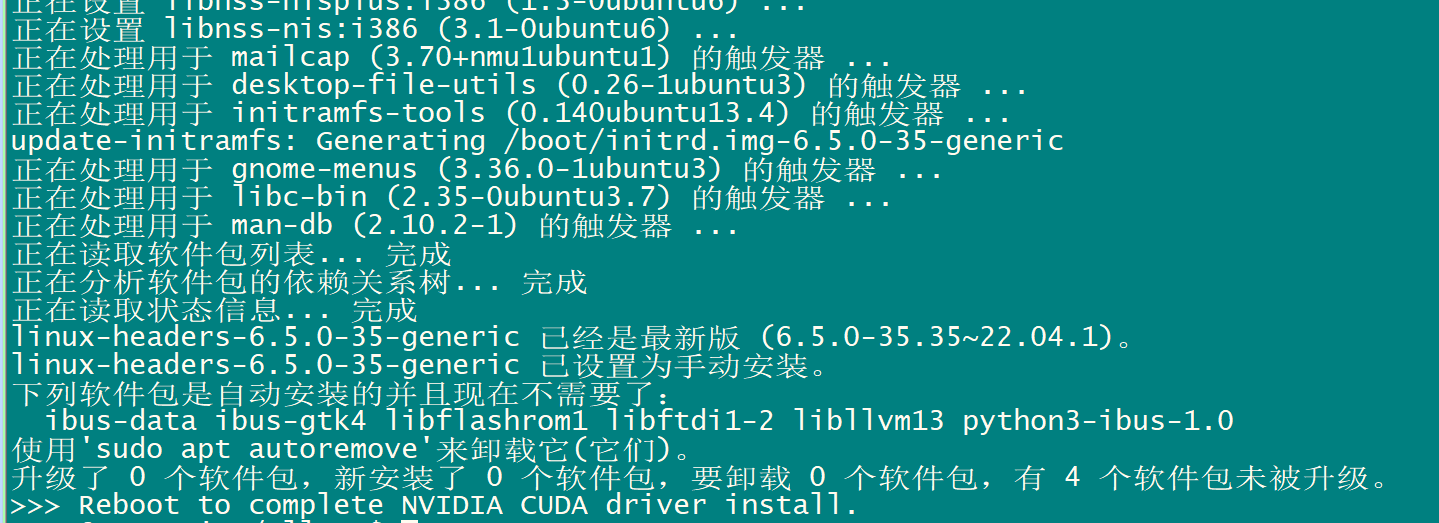
重启电脑
配置模型下载路径
cd
sudo vim .bashrc
sudo mkdir -p /home/star/ollama/ollama_cache
然后添加一行 配置 OLLAMA_MODELS 环境变量自定义路径
### ollama model dir 改为自己的路径
# export OLLAMA_MODELS=/path/ollama_cache
export OLLAMA_MODELS=/home/star/ollama/ollama_cache
如果开始没配置OLLAMA_MODELS ,默认路径是/usr/share/ollama/.ollama/models
启动ollama服务
# ollama --help
Large language model runner
Usage:
ollama [flags]
ollama [command]
Available Commands:
serve Start ollama
create Create a model from a Modelfile
show Show information for a model
run Run a model
pull Pull a model from a registry
push Push a model to a registry
list List models
ps List running models
cp Copy a model
rm Remove a model
help Help about any command
Flags:
-h, --help help for ollama
-v, --version Show version information
Use "ollama [command] --help" for more information about a command.
提示
star@star-ai:~$ ollama serve
Couldn't find '/home/star/.ollama/id_ed25519'. Generating new private key.
Your new public key is:
ssh-ed25519 AAAAC3NzaC1lZDI1NTE5AAAAIPmYsSi6aIsyhC4EHEsCdBtSOqnfKmNVSf0Ofz9sVzyB
Error: listen tcp 127.0.0.1:11434: bind: address already in use
说明已经运行
修改ollama端口
vim /etc/systemd/system/ollama.service
在 [Service] 下添加 Environment="OLLAMA_HOST=0.0.0.0"
cat /etc/systemd/system/ollama.service
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
ExecStart=/usr/local/bin/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3
Environment="PATH=/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:/root/bin"
Environment="OLLAMA_HOST=0.0.0.0"
[Install]
WantedBy=default.target
重新加载配置,重启ollama
systemctl daemon-reload
systemctl restart ollama
关闭服务
systemctl stop ollama
启动服务
systemctl start ollama
运行qwen大模型
ollama run qwen
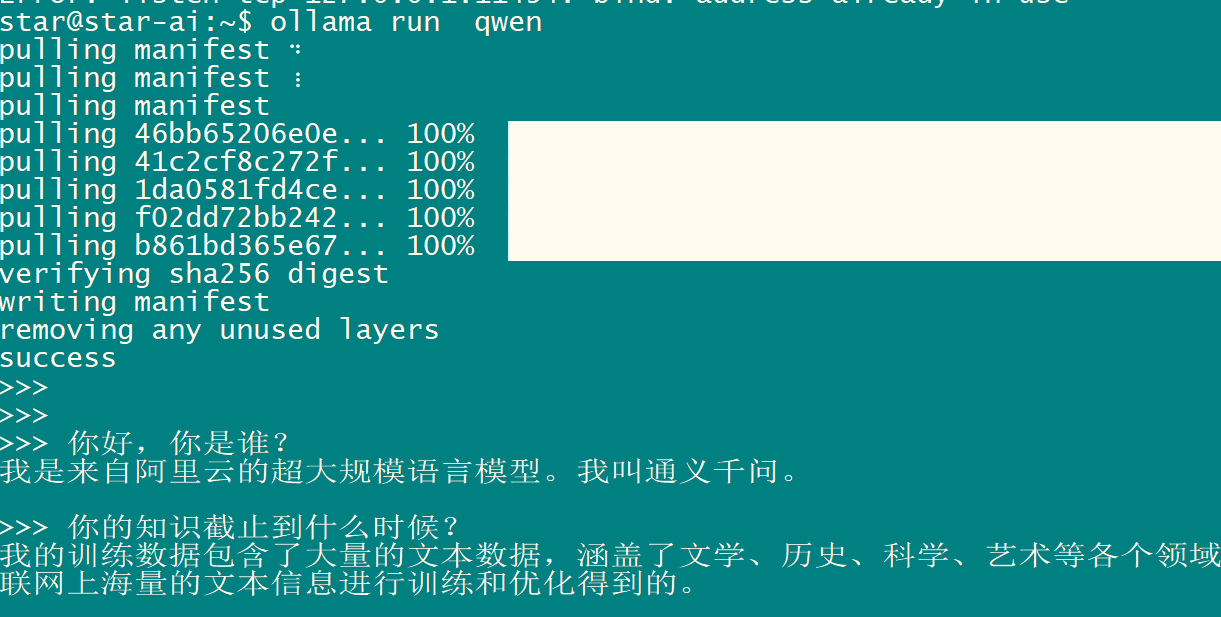
安装docker
一键安装脚本
sudo curl -sSL https://get.docker.com/ | sh
安装完成之后
star@star-ai:~$ sudo docker --version
Docker version 26.1.3, build b72abbb
安装Open WebUI
Open WebUI是一个用于在本地运行大型语言模型(LLM)的开源Web界面。
参考: https://docs.openwebui.com/getting-started/#quick-start-with-docker-
docker安装open-webui
$ sudo docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
要运行支持 Nvidia GPU 的 Open WebUI,请使用以下命令:
$ sudo docker run -d -p 3000:8080 --gpus all --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:cuda
改国内的地址
$ sudo docker run -d -p 3000:8080 --gpus all --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always registry.cn-shenzhen.aliyuncs.com/funet8/open-webui:cuda
报错:
sudo docker run -d -p 3000:8080 --gpus all --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always registry.cn-shenzhen.aliyuncs.com/funet8/open-webui:cuda
254b47e7994b2f0087ce0058918621523b39cf9b0e89018777c0cf98943ba2d1
docker: Error response from daemon: could not select device driver "" with capabilities: [[gpu]].
ubuntu识别不了我的显卡
$ sudo nvidia-smi
Fri May 17 18:37:15 2024
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 550.54.15 Driver Version: 550.54.15 CUDA Version: 12.4 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce GTX 1060 6GB Off | 00000000:01:00.0 Off | N/A |
| 40% 33C P8 6W / 120W | 65MiB / 6144MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| 0 N/A N/A 1030 G /usr/lib/xorg/Xorg 56MiB |
| 0 N/A N/A 1109 G /usr/bin/gnome-shell 4MiB |
+-----------------------------------------------------------------------------------------+
安装nvidia-container-toolkit:
确保你已经安装了nvidia-container-toolkit,并配置Docker以使用该工具包:
sudo apt-get update
sudo apt-get install -y nvidia-container-toolkit
sudo systemctl restart docker
检查Docker默认运行时配置:
确保Docker的默认运行时设置为nvidia。编辑Docker的配置文件(通常位于/etc/docker/daemon.json),并添加或修改如下内容:
sudo vim /etc/docker/daemon.json
添加:
{
"default-runtime": "nvidia",
"runtimes": {
"nvidia": {
"path": "nvidia-container-runtime",
"runtimeArgs": []
}
}
}
编辑完文件后,重启Docker服务:
sudo systemctl restart docker
检查NVIDIA Container Runtime兼容性:
确保你的NVIDIA Container Runtime版本与Docker版本兼容。可以通过以下命令查看版本:
sudo docker version
nvidia-container-runtime --version
完成上述步骤后,再次尝试运行你的Docker命令。如果问题仍然存在,请提供更多的系统信息和日志,以便进一步诊断问题。
sudo docker start open-webui

登录open-webui
用IP+端口访问
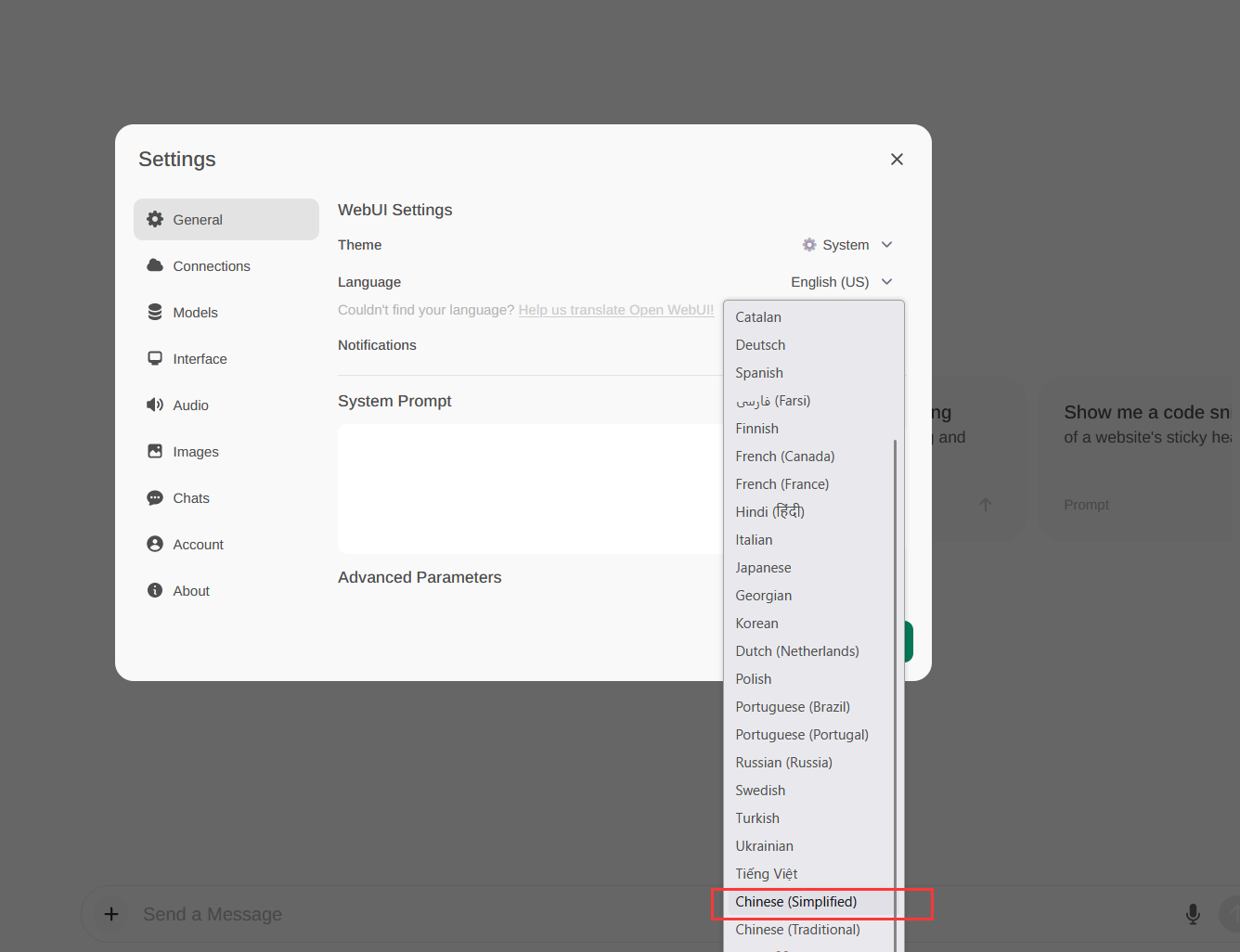
修改语言为中文
OpenWebUI默认是英文的,所以修改语言为简体中文。
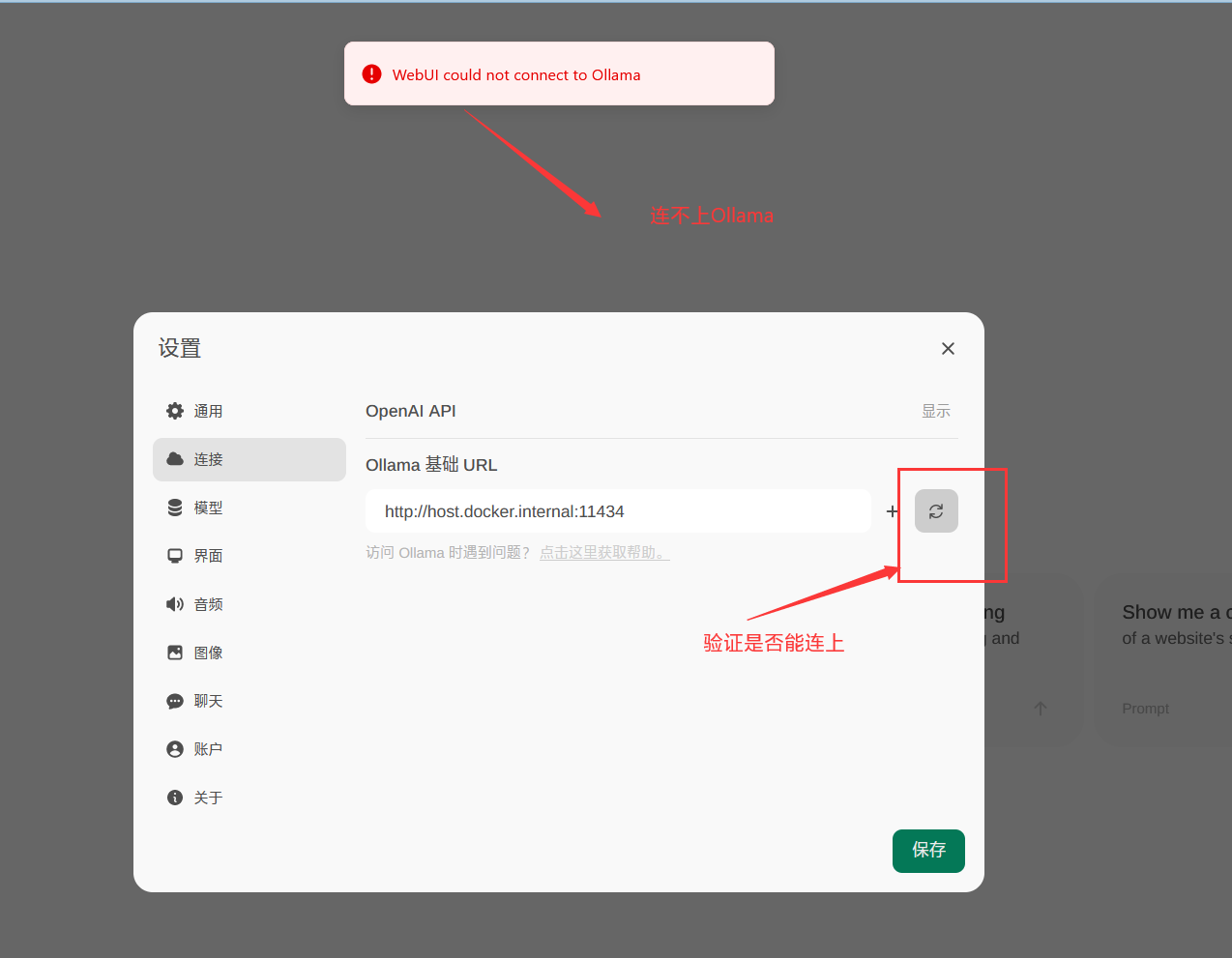
OpenWebUI不能连接Ollama
报错:WebUI could not connect to ollama
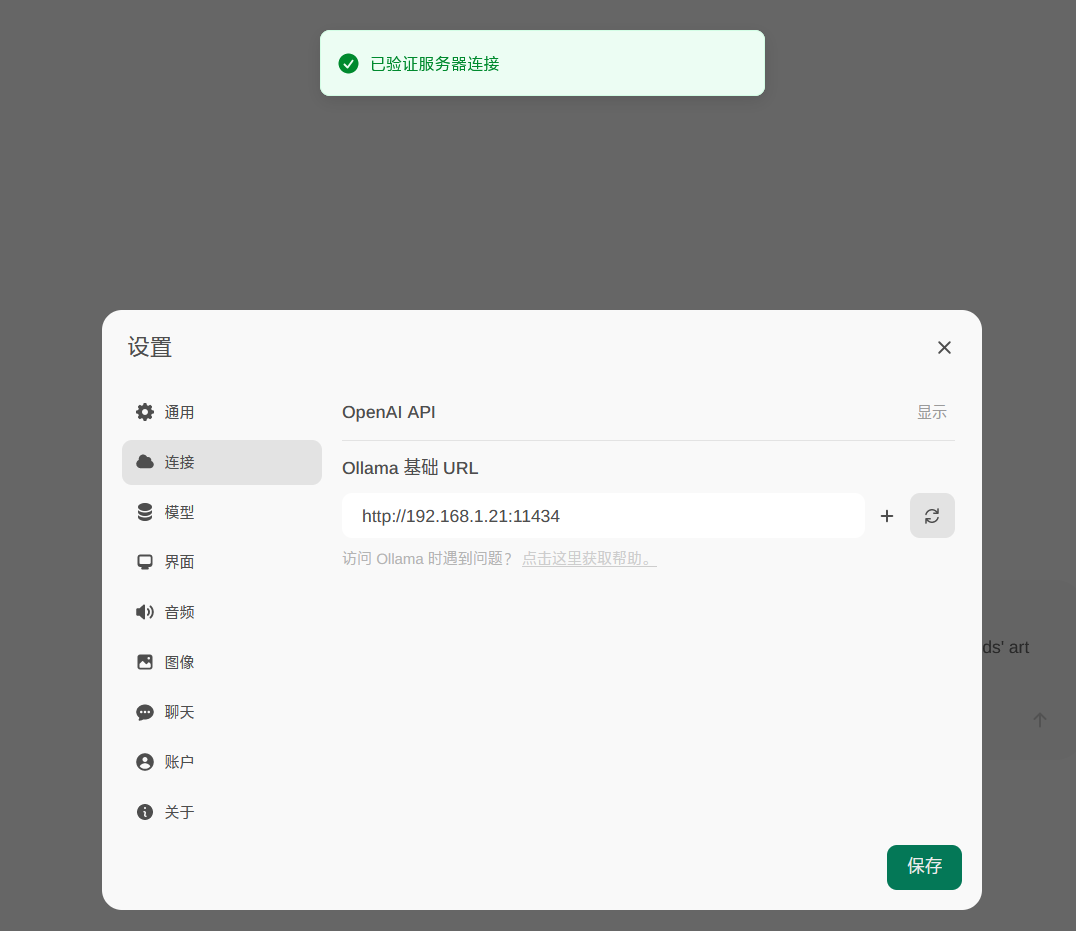
修改地址:http://192.168.1.21:11434
再下载千问的模型 qwen
下载大模型
ollama官方的模型仓库参见这里:https://ollama.com/library
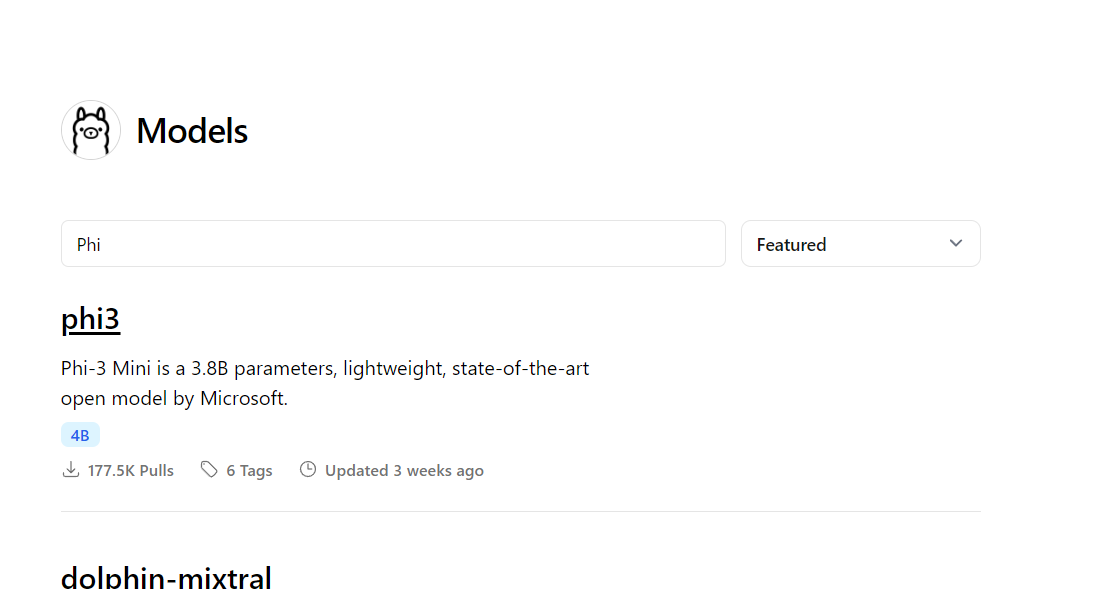
根据自己的CPU和GPU选择合适的大模型,否则会很卡。
比如测试用的1060使用qwen:72b就很卡,问一个问题要等很久,几乎是不能用的状态。
阿里巴巴的大模型:
ollama run qwen
ollama run qwen:14b
ollama run qwen:32b
ollama run qwen:72b
ollama run qwen:110b # 110b 表示该模型包含了 1100 亿(110 billion)个参数
脸书大模型:
ollama run llama2
ollama run llama3
ollama run llama3:8b
谷歌的大模型:
ollama run gemma
微软的大模型
ollama run phi3
删除模型
显示所有模型
# ollama list
删除模型
# ollama rm llama3:latest
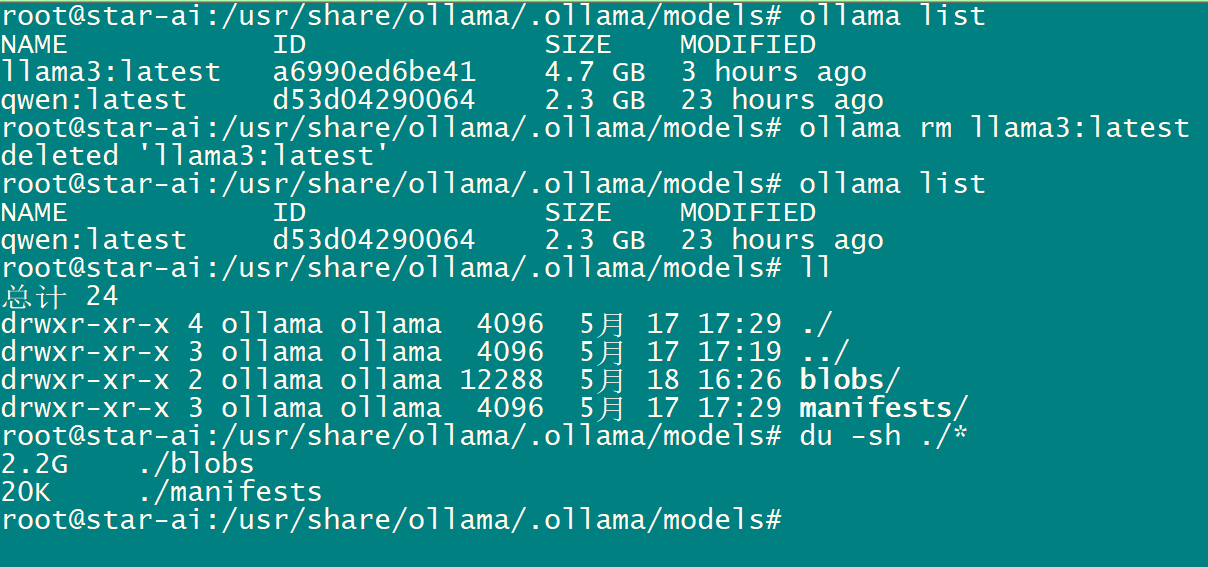
ubuntu查看GPU负载
nvidia-smi
确实在ubuntu20.04系统下确实比window10系统使用Ollama更加流畅。
标签:
相关文章
最新发布
- 光流法结合深度学习神经网络的原理及应用(完整代码都有Python opencv)
- Python 图像处理进阶:特征提取与图像分类
- 大数据可视化分析-基于python的电影数据分析及可视化系统_9532dr50
- 【Python】入门(运算、输出、数据类型)
- 【Python】第一弹---解锁编程新世界:深入理解计算机基础与Python入门指南
- 华为OD机试E卷 --第k个排列 --24年OD统一考试(Java & JS & Python & C & C++)
- Python已安装包在import时报错未找到的解决方法
- 【Python】自动化神器PyAutoGUI —告别手动操作,一键模拟鼠标键盘,玩转微信及各种软件自动化
- Pycharm连接SQL Sever(详细教程)
- Python编程练习题及解析(49题)
点击排行
- 版本匹配指南:Numpy版本和Python版本的对应关系
- 版本匹配指南:PyTorch版本、torchvision 版本和Python版本的对应关系
- Python 可视化 web 神器:streamlit、Gradio、dash、nicegui;低代码 Python Web 框架:PyWebIO
- 相关性分析——Pearson相关系数+热力图(附data和Python完整代码)
- Anaconda版本和Python版本对应关系(持续更新...)
- Python与PyTorch的版本对应
- Windows上安装 Python 环境并配置环境变量 (超详细教程)
- Python pyinstaller打包exe最完整教程
本站推荐
