首页 > Python资料 博客日记
一篇教你python网页自动化
2024-08-22 19:00:06Python资料围观106次
一篇教你python网页自动化
前言
在当今的快速发展的数字时代,自动化技术已成为提高效率、减少重复性工作和优化数据管理过程的关键工具。网页自动化尤其在多个行业中表现出巨大的潜力,包括电子商务、数据分析、市场研究等领域。通过自动化脚本,用户可以模拟网页上的各种操作,如填写表单、抓取数据、自动测试以及定期检查内容更新。
Python,作为一种简单易学的编程语言,配合强大的库如Selenium,提供了一个强大的平台用于开发和实现网页自动化任务。本教程将指导您通过Python使用Selenium库进行基本的网页自动化,覆盖从环境设置到实际脚本编写的各个步骤。
提示:以下是本篇文章正文内容,下面案例可供参考
一、安装Python?
确保你的计算机上安装了Python。可以从Python官方网站下载并安装。
我这里已经下载好了!
二、安装Selenium库:
打开你的命令行工具(如cmd、Terminal等),输入以下命令来安装Selenium:
pip install selenium
1.下载WebDriver:
Selenium 需要与浏览器驱动(WebDriver)一起使用,你需要下载与你使用的浏览器相对应的驱动。例如,如果你使用Chrome浏览器,可以从ChromeDriver下载页面获取最新的驱动。
2.第二部分:基本网页操作
from selenium import webdriver
指定ChromeDriver的路径:
driver = webdriver.Chrome(executable_path=‘path_to_chromedriver’)
或者不需要指定
三、元素定位与操作:
使用Selenium的定位功能来找到页面元素并与之交互。
- 定位元素:
from selenium.webdriver.common.by import By search_box = driver.find_element(By.NAME, 'q') - 输入文字
往表单输入框输入文字这个就很简单了search_box.send_keys('Python') - 点击按钮
search_button = driver.find_element(By.NAME, 'btnK') search_button.click() - 获取数据
results = driver.find_element(By.ID, 'results') print(results.text)
``
图文演示获取选择器
也可以直接使用选择器:
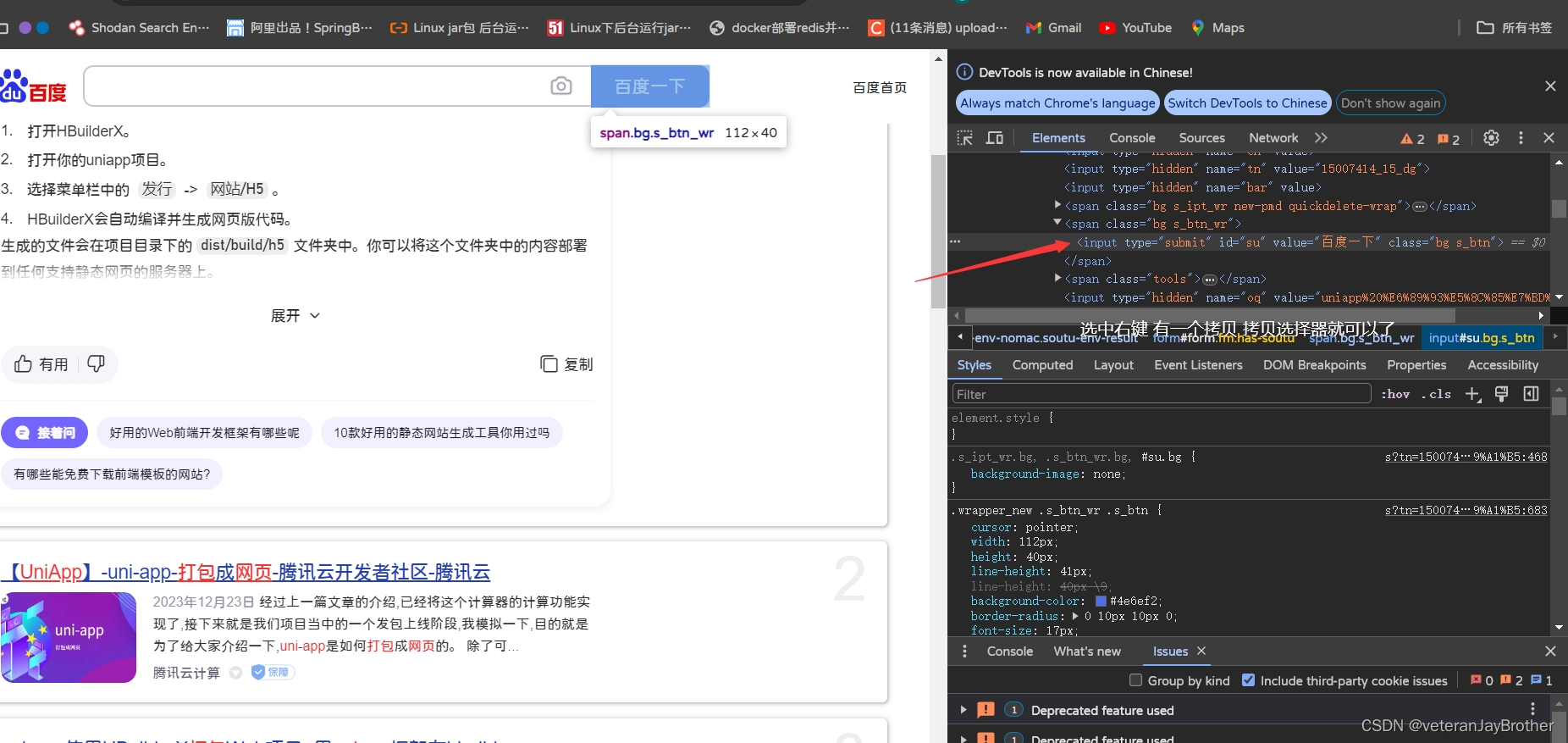 这里刚刚复制到的是:#su 操作都是一样的
这里刚刚复制到的是:#su 操作都是一样的
写的一个案例:
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import pandas as pd
class CredentialManager:
def __init__(self, filename):
self.credentials = pd.read_excel(filename)
def get_credentials(self, index):
if index < len(self.credentials):
username = self.credentials['用户名'].iloc[index]
password = self.credentials['密码'].iloc[index]
return username, password
else:
raise IndexError("Index out of range for credentials.")
def get_from_product(self, index):
if index < len(self.credentials):
product_name = self.credentials['产品名称'].iloc[index]
product_des = self.credentials['产品描述'].iloc[index]
mp4 = self.credentials['产品视频'].iloc[index]
img = self.credentials['视频封面'].iloc[index]
return product_name, product_des, mp4, img
else:
raise IndexError("没有拿到表单")
class LoginAutomation:
def __init__(self):
self.driver = webdriver.Chrome()
self.url = "地址"
self.credential_manager = CredentialManager('ge.xlsx')
def login(self, username, password):
# 登录到网站
self.driver.get(self.url)
time.sleep(2) # 等待页面加载
try:
# 输入用户名和密码,然后点击登录
username_input = self.driver.find_element(By.XPATH, '//input[@placeholder="用户名"]')
username_input.send_keys(username)
password_input = self.driver.find_element(By.XPATH, '//input[@placeholder="密码"]')
password_input.send_keys(password)
self.driver.find_element(By.CSS_SELECTOR, "#app > div > div:nth-child(3) > div > "
"div.page-login--content-main > div > div > div > form > "
"button").click()
time.sleep(4) # 等待登录完成
except Exception as e:
print("在填写表单时遇到错误:", e)
def run(self):
# 尝试使用所有凭据进行登录
for i in range(len(self.credential_manager.credentials)):
username, password = self.credential_manager.get_credentials(i)
print(f"Attempting to login with user {username}")
self.login(username, password)
def close_browser(self):
self.driver.quit()
if __name__ == '__main__':
login_automation = LoginAutomation()
login_automation.run()
login_automation.close_browser()
这里我是从表格中读取要的数据 只是参考
总结:
本教程提供了使用Python和Selenium进行基本网页自动化的入门级指南。通过学习如何自动化网页任务,您可以节省时间、增加效率,并为更复杂的自动化脚本开发打下基础。
来一起解放双手!
标签:
相关文章
最新发布
- 光流法结合深度学习神经网络的原理及应用(完整代码都有Python opencv)
- Python 图像处理进阶:特征提取与图像分类
- 大数据可视化分析-基于python的电影数据分析及可视化系统_9532dr50
- 【Python】入门(运算、输出、数据类型)
- 【Python】第一弹---解锁编程新世界:深入理解计算机基础与Python入门指南
- 华为OD机试E卷 --第k个排列 --24年OD统一考试(Java & JS & Python & C & C++)
- Python已安装包在import时报错未找到的解决方法
- 【Python】自动化神器PyAutoGUI —告别手动操作,一键模拟鼠标键盘,玩转微信及各种软件自动化
- Pycharm连接SQL Sever(详细教程)
- Python编程练习题及解析(49题)
点击排行
- 版本匹配指南:Numpy版本和Python版本的对应关系
- 版本匹配指南:PyTorch版本、torchvision 版本和Python版本的对应关系
- Python 可视化 web 神器:streamlit、Gradio、dash、nicegui;低代码 Python Web 框架:PyWebIO
- 相关性分析——Pearson相关系数+热力图(附data和Python完整代码)
- Anaconda版本和Python版本对应关系(持续更新...)
- Python与PyTorch的版本对应
- Windows上安装 Python 环境并配置环境变量 (超详细教程)
- Python pyinstaller打包exe最完整教程
本站推荐
