首页 > Python资料 博客日记
基于大数据爬虫+Python+数据可视化大屏的旅游数据分析推荐与可视化平台(源码+论文+PPT+部署文档教程等)
2024-09-25 19:00:05Python资料围观185次
博主介绍:✌全网粉丝50W+,csdn特邀作者、博客专家、CSDN新星计划导师、Java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和学生毕业项目实战,高校老师/讲师/同行前辈交流✌
技术范围:SpringBoot、Vue、SSM、HLMT、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、小程序、安卓app、大数据、物联网、机器学习等设计与开发。
主要内容:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码编写、论文编写和辅导、论文降重、长期答辩答疑辅导、腾讯会议一对一专业讲解辅导答辩、模拟答辩演练、和理解代码逻辑思路。
🍅文末获取源码联系🍅
👇🏻 精彩专栏推荐订阅👇🏻 不然下次找不到哟
2022-2024年最全的计算机软件毕业设计选题大全:1000个热门选题推荐✅
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人

系统介绍:
在信息化时代,数据已成为洞悉行业趋势、指导决策的重要资源。广东省,作为中国的经济大省和旅游大省,拥有丰富的旅游资源和庞大的旅游市场。近年来,随着国内外旅游需求的持续增长,广东旅游业呈现出多元化和个性化的发展趋势。面对海量而杂乱的网络数据,如何有效地进行信息的提取、处理与分析,成为了提升旅游服务质量和市场竞争力的关键。Python作为一种强大的编程语言,以其简洁的语法和丰富的数据分析库,成为进行旅游数据分析的理想工具。通过Python实现的自动化数据收集和分析流程,能够为广东旅游业提供科学的决策支持,同时为游客提供个性化的旅游推荐。

基于Python的广东旅游数据分析不仅具有理论研究价值,更具备实践应用的重要性。从理论层面来看,该分析可以丰富旅游学科的研究方法,将数据科学与旅游管理相结合,开辟新的跨学科研究领域。从实践层面来讲,通过对广东旅游数据的深入分析,能够帮助政府和企业掌握旅游市场的实时动态,优化资源配置,提高经营效率;对于游客而言,可以根据分析结果获得更为精准的旅游信息,规划出更加合适的旅行计划。此外,该分析还能够预测旅游市场的潜在风险,为旅游安全管理提供参考依据。总体而言,基于Python的广东旅游数据分析项目对于推动广东乃至全国的旅游产业发展,提升旅游体验质量,具有深远的社会和经济意义。

网络爬虫
网络爬虫原理
网络爬虫最常用于各个搜索引擎,一般作为搜索引擎的核心模块[23],主要提供信息获取功能。通常情况下,网络爬虫是一段用于抓取 HTML 文档数据,并对下载的网页整理、建索引的程序或脚本。网络爬虫主要包含页面采集、页面解析、链接处理几个子模块。图 2-4 展示了网络爬虫的结构。

网络爬虫的工作流程
图 2-4 网络爬虫结构

图 2-5 网络爬虫工作流程
- 网络爬虫的队列

程序上交给用户进行使用时,需要提供程序的操作流程图,这样便于用户容易理解程序的具体工作步骤,现如今程序的操作流程都有一个大致的标准,即先通过登录页面提交登录数据,通过程序验证正确之后,用户才能在程序功能操作区页面操作对应的功能。
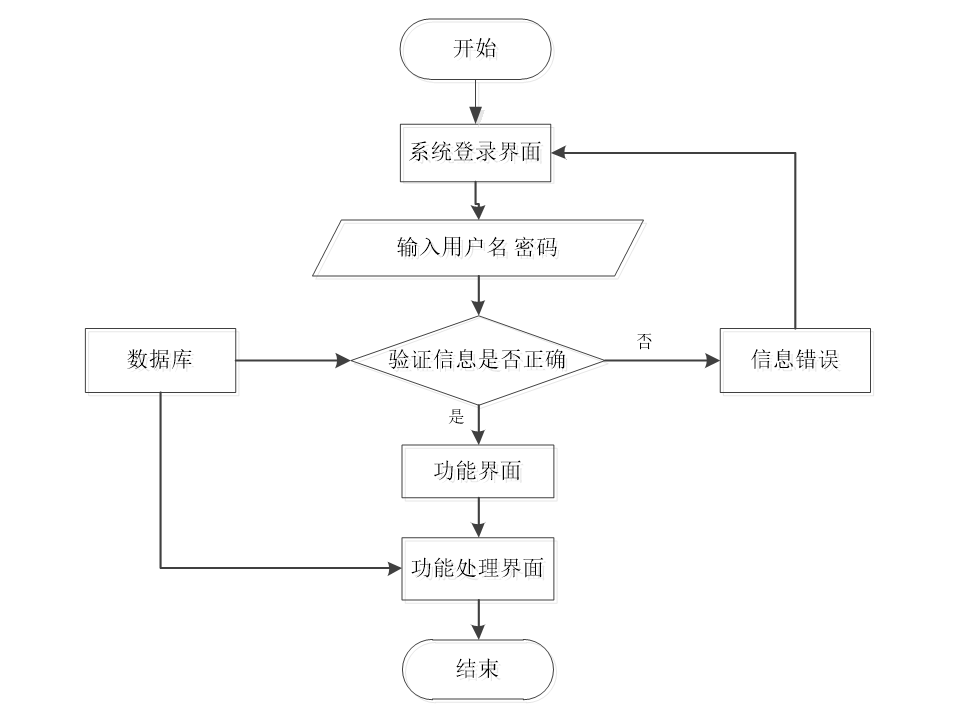
程序操作流程图
首先前端通过Vue和axios发送HTTP请求到后端的登录接口。在后端接收登录请求的Controller会使用`@RequestParam Map<String, Object> params`来接收前端传递的用户参数,用户名和密码。然后后端根据接收到的参数创建一个查询条件封装对象MyBatis的EntityWrapper用于构建查询条件。接着在业务层,调用相应的service方法来查询数据库中是否存在匹配的用户信息。这个查询方法Login()会将前端传递的对象参数传递到后台的DAO层,进行数据库的交互操作。如果存在符合条件的用户,则会返回相关的用户信息。最后在后端控制器中将查询结果封装成响应体,通过`return R.ok().put("data", userService.selecView(ew))`将用户信息返回给前端。前端收到响应后,可以通过调用Vue、ElementUI等组件来渲染登录结果,例如显示用户信息或者跳转到相应的页面。
系统架构设计
系统架构设计是软件开发过程中至关重要的一环。首先是模型层(Model),模型层通常对应着数据库或者其他数据源,它负责与数据库进行交互,执行各种数据操作,并将处理后的数据传递给控制器层。模型层的设计应该简洁清晰,尽可能减少与视图和控制器的耦合,以提高代码的可维护性和可重用性。
其次是视图层(View)通常是通过网页、移动应用界面或者其他用户界面来展示数据。视图层与用户交互,接受用户的输入,并将输入传递给控制器层进行处理。在MVC三层架构中,视图层应该尽量保持简单,只负责数据的展示和用户交互,不涉及业务逻辑的处理,以保持视图层的清晰度和可复用性,最后是控制器层(Controller),每个层都有特定的职责和功能,通过分层架构设计,实现代码模块化,为软件开发提供了一种有效的架构模式。系统架构如图4-1所示。

详细视频演示
请文末卡片dd我获取更详细的演示视频

功能截图:
在系统前台首页,调用`$route(newValue)`方法监听路由变化,根据当前的路由地址来确定活动菜单的索引,并且根据路由的哈希部分(即URL的`#`后面的部分)来判断是否需要滚动页面到顶部或者某个特定元素的位置。如果不是首页,会将页面滚动到指定元素处,否则滚动到页面顶部。另外通过`headportrait()`方法用于更新组件渲染点前用户头像。在用户登录后,后端返回了新的用户信息,需要及时更新页面上的用户头像信息。
按照软件工程的流程来说,在系统的详细设计与实现阶段,要把模块、视图、模板进行相应的组合完成一个个所需的功能,此章将会把设计中模块一一说明如何设计和实现的。
5.1前台功能实现
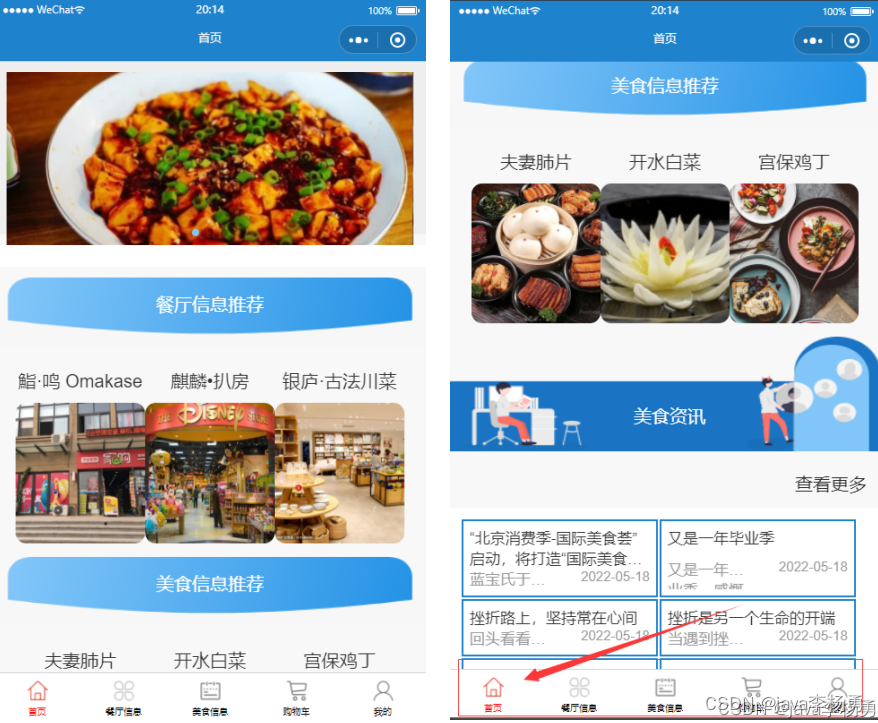
当人们打开系统的网址后,首先看到的就是首页界面。在这里,人们能够看到系统的导航条,通过导航条导航进入各功能展示页面进行操作。系统首页界面如图5-1所示:

图5-1 系统首页界面
在注册流程中,用户在Vue前端填写必要信息(如用户名、密码等)并提交。前端将这些信息通过HTTP请求发送到Python后端。后端处理这些信息,检查用户名是否唯一,并将新用户数据存入MySQL数据库。完成后,后端向前端发送注册成功的确认,前端随后通知用户完成注册。这个过程实现了新用户的数据收集、验证和存储。系统注册页面如图5-2所示:

图5-2系统注册详细页面
广东景点:在广东景点页面的输入栏中输入标题和地址进行查询,可以查看到广东景点详细信息,并进行评论或收藏操作;广东景点页面如图5-3所示:

图5-3广东景点详细页面
在个人中心页面可以对个人中心、修改密码、我的收藏进行详细操作;如图5-4所示:

图5-4个人中心界面
5.2管理员功能实现
在登录流程中,用户首先在Vue前端界面输入用户名和密码。这些信息通过HTTP请求发送到Python后端。后端接收请求,通过与MySQL数据库交互验证用户凭证。如果认证成功,后端会返回给前端,允许用户访问系统。这个过程涵盖了从用户输入到系统验证和响应的全过程。如图5-5所示。


图5-5 管理员登录界面
管理员进入主页面,主要功能包括对系统首页、用户、广东景点、系统管理、个人资料等进行操作。管理员主页面如图5-6所示:

图5-6管理员主界面
用户功能实现是在Django后端部分,您需要创建一个新的应用,然后在该应用下创建一个模型(models.py)来定义用户的数据结构,使用Django的ORM来处理与MySQL数据库的交互,包括用户信息的查询、添加或删除等操作。接着,在views.py中编写视图逻辑来处理前端请求,使用Django的URL路由(urls.py)将请求映射到相应的视图函数。对于数据的验证和序列化,可以使用Django的表单或序列化器来实现。在前端Vue.js部分,将创建相应的Vue组件,在这些组件中使用axios或其他HTTP库与Django后端的API进行交互,实现用户信息的查看,修改或删除等功能。状态管理可以通过Vuex来维护,比如在store目录下定义用户模块的状态、突变、动作和获取器。如图5-7所示:

图5-7用户界面
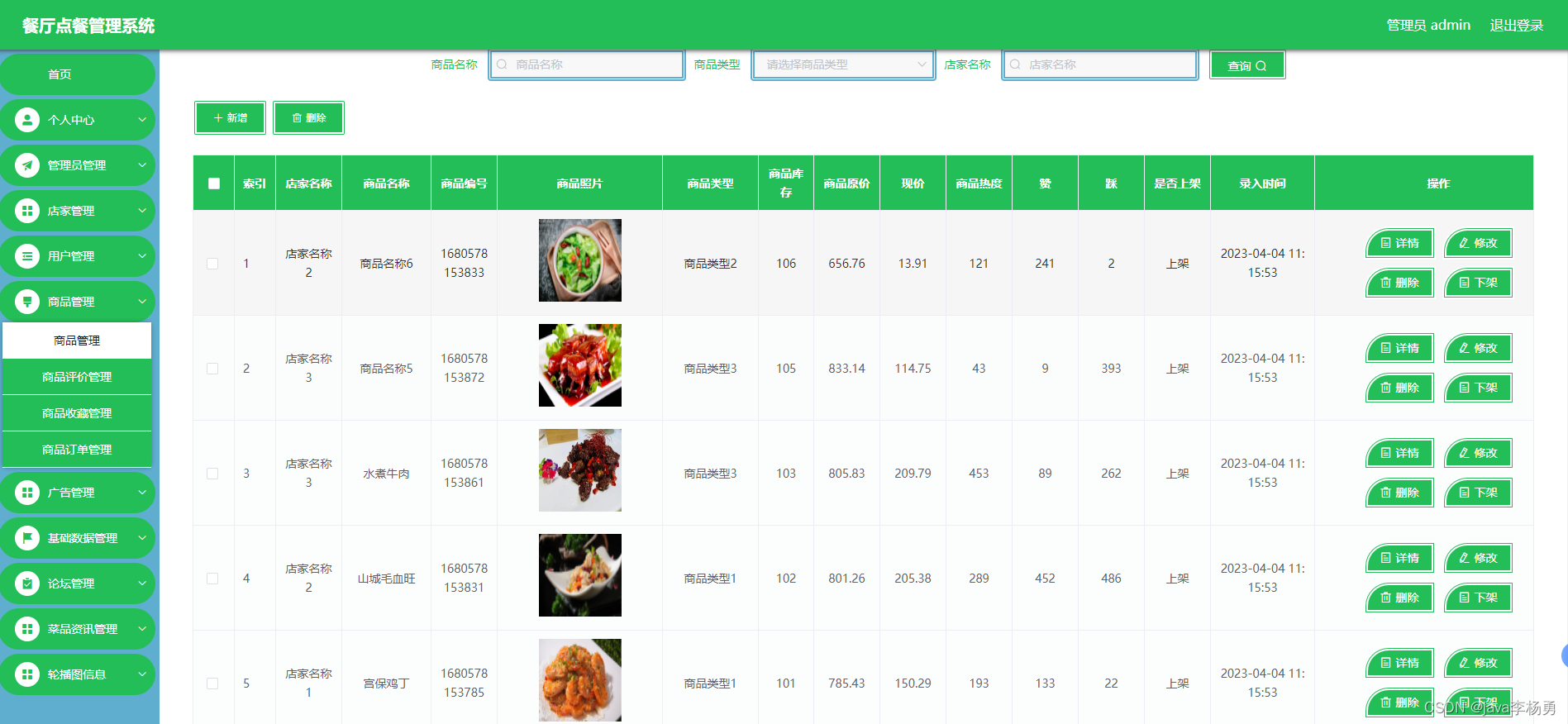
广东景点功能实现是在Django后端部分,您需要创建一个新的应用,然后在该应用下创建一个模型(models.py)来定义广东景点的数据结构,使用Django的ORM来处理与MySQL数据库的交互,包括广东景点信息的查询、添加、删除或爬取数据等操作。接着,在views.py中编写视图逻辑来处理前端请求,使用Django的URL路由(urls.py)将请求映射到相应的视图函数。对于数据的验证和序列化,可以使用Django的表单或序列化器来实现。在前端Vue.js部分,将创建相应的Vue组件,在这些组件中使用axios或其他HTTP库与Django后端的API进行交互,实现广东景点信息的查看、修改、查看评论或删除等功能。状态管理可以通过Vuex来维护,比如在store目录下定义广东景点模块的状态、突变、动作和获取器。如图5-8所示:

图5-8广东景点管理界面
管理员点击系统管理,在系统公告页面输入标题可以查询,添加或删除系统公告列表,并对系统公告进行查看、修改和删除等操作;还可以对系统公告分类、关于我们、系统简介、轮播图管理进行详细操作。如图5-9所示:

图5-9系统管理界面
5.3数据采集
本程序数据爬取使用经典的requests、urllib包进行数据爬取,爬取的网站为广东省旅游信息,广东省旅游信息有较强的反爬机制,采用cookie的形式进行封装,再进行数据获取。
定义一个Scrapy爬虫类`guangdonglvyouSpider`,用于爬取指定网站的旅游信息。`name`定义了爬虫的名称,`spiderUrl`指定了目标网站的URL,`start_urls`将目标网站的URL按分号拆分成一个列表,作为爬取的起始URL。`protocol`和`hostname`用于定义协议和主机名,暂时为空。`realtime`用于指定是否实时获取数据,初始化为False。
代码如下所示。
| # 广东景点 class GuangdongSpider(scrapy.Spider): name = 'guangdongSpider' spiderUrl = 'https://you.ctrip.com/sight/guangzhou152/s0-p{}.html;https://you.ctrip.com/sight/shenzhen26/s0-p{}.html;https://you.ctrip.com/sight/zhuhai27/s0-p{}.html;https://you.ctrip.com/sight/foshan207/s0-p{}.html;https://you.ctrip.com/sight/dongguan212/s0-p{}.html;https://you.ctrip.com/sight/shantou215/s0-p{}.html' start_urls = spiderUrl.split(";") protocol = '' hostname = '' realtime = False headers = { "Cookie":"输入自己的cookie" } realtime = False |
使用parse方法中进行一些初始化操作和判断条件。首先,通过urlparse函数解析self.spiderUrl得到URL的协议和主机名,并将其分别赋值给self.protocol和self.hostname。 然后,通过platform.system().lower()获取当前操作系统的名称,并将其转换为小写字母,保存在plat变量中。 接着,判断条件如果不是实时爬取(self.realtime为False)并且当前操作系统是Linux或Windows,建立数据库连接,并将连接对象赋值给connect变量。获取数据库的游标对象,并将其赋值给cursor变量,调用table_exists函数检查数据库中是否存在名为'5nw5u40i_guangdonglvyou '的表,如果存在就执行关闭游标和连接,调用temp_data函数,最后返回。代码如下所示。
| def parse(self, response): |
使用Scrapy爬虫的回调函数,进行解析详情页面,从response的meta中获取字段对象fileds,最后对其进行赋值和处理。代码如下所示。
| def detail_parse(self, response): |
5.4数据处理
在基于Python的广东省人口流动数据分析平台开发中,数据集处理是至关重要的环节。以下是我详细的数据集处理流程:
首先通过多种途径获取人口信息数据集,或者包括爬取招聘网站的数据。其次,一旦获得了数据集,接下来需要进行数据清洗和预处理。数据清洗是为了确保数据的质量和完整性,包括去除重复项、处理缺失值、纠正错误数据等。预处理则包括数据格式化、标准化、转换等,以便后续的分析和应用。数据清洗使用的是pandas库进行分析,结合Scrapy框架进行数据爬取和清洗,确保数据的准确性和可用性。数据存储采用了MySQL,确保数据的安全和可扩展性。
创建一个MySQL数据库的连接引擎,使用root用户和密码为123456来连接名为spider5nw5u40i的数据库,使用pandas的read_sql函数从数据库中读取数据。代码如下所示。
| def pandas_filter(self): |
首先,检查DataFrame对象df是否存在重复的行,使用'df.drop_duplicates()'函数删除对象中重复行。调用'df.isnull()'函数检测对象df'中的缺失值。随后调用'df.dropna()'函数删除具有缺失值的行。'df.fillna(value='暂无')'函数将对象df中的缺失值替换为指定的值'暂无'。代码如下所示。
| df.duplicated() |
生成一个包含200个介于0到1000之间的随机整数的数组a,然后定义了一个布尔条件cond,用于筛选满足a在100到800之间的元素。生成一个包含10万个符合标准正态分布的随机数的数组b,定义一个布尔条件cond,用于筛选满足b的绝对值大于3的元素。
创建一个形状为10000行3列的DataFrame df2,其中的数据是符合标准正态分布的随机数。定义一个布尔条件cond,用于筛选在df2中任意一列的值大于三倍标准差的行。该行代码使用索引操作df2[cond].index,获取满足条件cond的行的索引。删除具有指定索引的行,并返回更新后的对象df2。代码如下所示。
| a = np.random.randint(0, 1000, size = 200) |
移除HTML标签,首先,检查html参数是否为None,如果是则返回空字符串。然后使用正则表达式模式匹配HTML标签的正则表达式(<[^>]+>),并通过re.sub函数将匹配到的HTML标签替换为空字符串。最后使用strip函数去除字符串两端的空白字符,并返回处理后的结果。代码如下所示。
| def remove_html(self, html): |
进行数据库连接,首先从设置中获取数据库的连接参数,包括数据库类型、主机地址、端口号、用户名和密码。如果没有指定数据库名称,则尝试从self.databaseName中获取。然后根据数据库类型选择相应的数据库连接方式,如果是MySQL,则使用pyMySQL库进行连接,否则使用pymssql库进行连接。最后返回连接对象connect。代码如下所示。
| def db_connect(self): |
将处理好的数据进行数据存储,定义一个包含插入语句的sql字符串,目标数据库表是guangdonglvyou,列名包括id、jobname、salary等,从表5nw5u40i_guangdonglvyou中选择符合条件的数据,将这些数据插入到目标表中。执行sql语句,将临时数据插入到目标表中,最后提交事务和关闭数据库连接。部分代码如下所示。
| plat = platform.system().lower() if not self.realtime and (plat == 'linux' or plat == 'windows'): connect = self.db_connect() cursor = connect.cursor() if self.table_exists(cursor, '3zot8a0f_guangdonglvyou') == 1: cursor.close() connect.close() self.temp_data() Return pageNum = 1 + 1 |
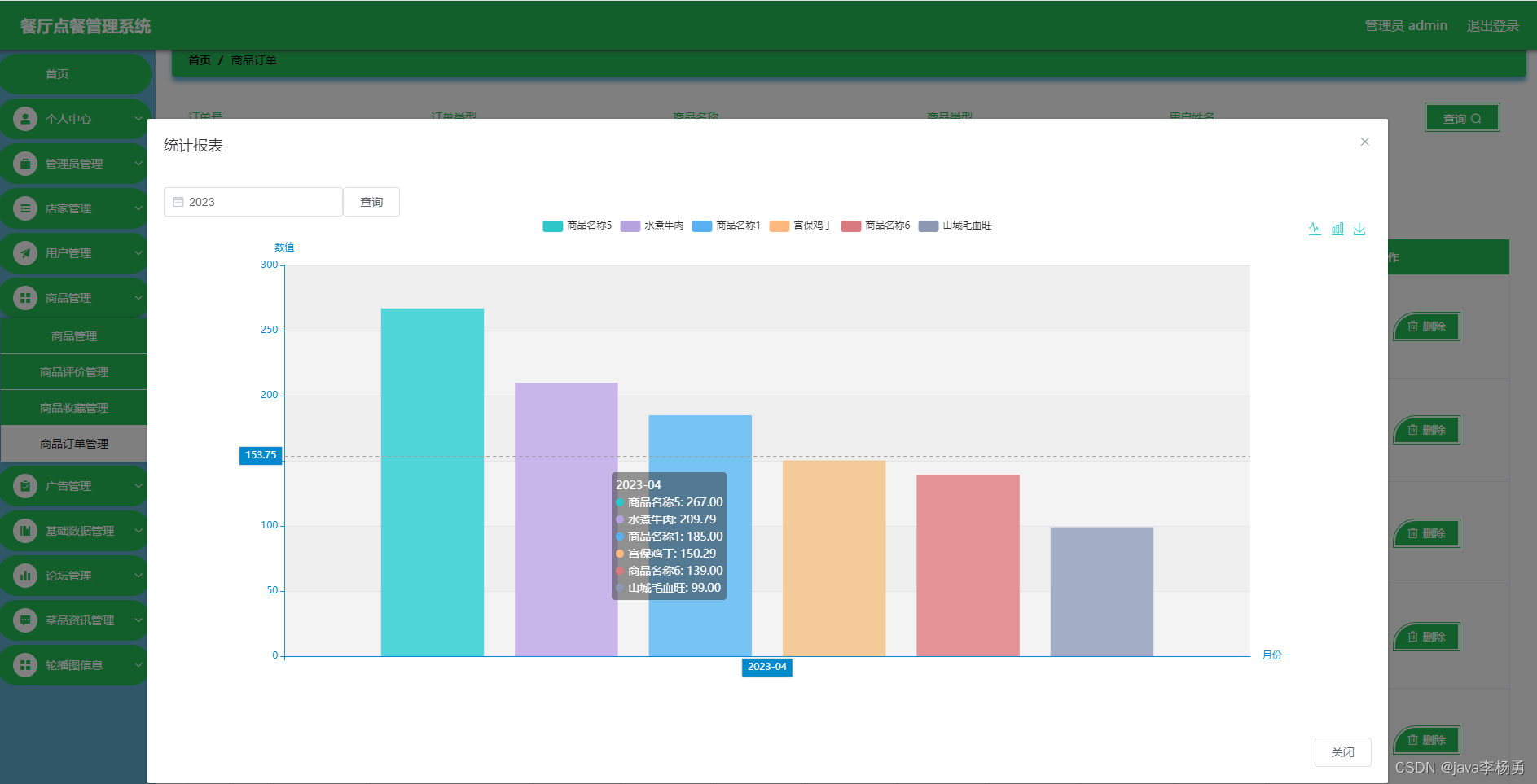
5.5数据可视化大屏
管理员进行爬取数据后可以在看板页面查看到系统简介、词云展示、人口数据分析、城市人口统计、年份人口总数统计、旅游信息总数、人口数据总数、旅游信息详情等实时的分析图进行可视化管理;看板大屏选择了Echart作为数据可视化工具,它是一个使用JavaScript实现的开源可视化库,能够无缝集成到Java Web应用中。Echart的强大之处在于其丰富的图表类型和高度的定制化能力,使得管理人员可以通过直观的图表清晰地把握人口数据的各项数据。为了实现对人口数据信息的自动化收集和更新,我们采用了Apache Spark作为爬虫技术的基础。Spark的分布式计算能力使得系统能够高效地处理大规模数据,无论是从互联网上抓取最新的人口数据信息,还是对内部数据进行ETL(提取、转换、加载)操作,都能够保证数据的实时性和准确性。
对收集到的大量数据进行存储和分析。看板页面如图5-10所示:
图5-10看板详细页面
论文参考:




代码实现:
/**
* 登录相关
*/
@RequestMapping("users")
@RestController
public class UserController{
@Autowired
private UserService userService;
@Autowired
private TokenService tokenService;
/**
* 登录
*/
@IgnoreAuth
@PostMapping(value = "/login")
public R login(String username, String password, String role, HttpServletRequest request) {
UserEntity user = userService.selectOne(new EntityWrapper<UserEntity>().eq("username", username));
if(user != null){
if(!user.getRole().equals(role)){
return R.error("权限不正常");
}
if(user==null || !user.getPassword().equals(password)) {
return R.error("账号或密码不正确");
}
String token = tokenService.generateToken(user.getId(),username, "users", user.getRole());
return R.ok().put("token", token);
}else{
return R.error("账号或密码或权限不对");
}
}
/**
* 注册
*/
@IgnoreAuth
@PostMapping(value = "/register")
public R register(@RequestBody UserEntity user){
// ValidatorUtils.validateEntity(user);
if(userService.selectOne(new EntityWrapper<UserEntity>().eq("username", user.getUsername())) !=null) {
return R.error("用户已存在");
}
userService.insert(user);
return R.ok();
}
/**
* 退出
*/
@GetMapping(value = "logout")
public R logout(HttpServletRequest request) {
request.getSession().invalidate();
return R.ok("退出成功");
}
/**
* 密码重置
*/
@IgnoreAuth
@RequestMapping(value = "/resetPass")
public R resetPass(String username, HttpServletRequest request){
UserEntity user = userService.selectOne(new EntityWrapper<UserEntity>().eq("username", username));
if(user==null) {
return R.error("账号不存在");
}
user.setPassword("123456");
userService.update(user,null);
return R.ok("密码已重置为:123456");
}
/**
* 列表
*/
@RequestMapping("/page")
public R page(@RequestParam Map<String, Object> params,UserEntity user){
EntityWrapper<UserEntity> ew = new EntityWrapper<UserEntity>();
PageUtils page = userService.queryPage(params, MPUtil.sort(MPUtil.between(MPUtil.allLike(ew, user), params), params));
return R.ok().put("data", page);
}
/**
* 信息
*/
@RequestMapping("/info/{id}")
public R info(@PathVariable("id") String id){
UserEntity user = userService.selectById(id);
return R.ok().put("data", user);
}
/**
* 获取用户的session用户信息
*/
@RequestMapping("/session")
public R getCurrUser(HttpServletRequest request){
Integer id = (Integer)request.getSession().getAttribute("userId");
UserEntity user = userService.selectById(id);
return R.ok().put("data", user);
}
/**
* 保存
*/
@PostMapping("/save")
public R save(@RequestBody UserEntity user){
// ValidatorUtils.validateEntity(user);
if(userService.selectOne(new EntityWrapper<UserEntity>().eq("username", user.getUsername())) !=null) {
return R.error("用户已存在");
}
userService.insert(user);
return R.ok();
}
/**
* 修改
*/
@RequestMapping("/update")
public R update(@RequestBody UserEntity user){
// ValidatorUtils.validateEntity(user);
userService.updateById(user);//全部更新
return R.ok();
}
/**
* 删除
*/
@RequestMapping("/delete")
public R delete(@RequestBody Integer[] ids){
userService.deleteBatchIds(Arrays.asList(ids));
return R.ok();
}
}推荐项目:
基于SpringBoot+数据可视化+大数据二手电子产品需求分析系统
基于SpringBoot+数据可视化+协同过滤算法的个性化视频推荐系统
基于SpringBoot+大数据+爬虫+数据可视化的的媒体社交与可视化平台
基于大数据+爬虫+数据可视化+SpringBoot+Vue的智能孕婴护理管理与可视化平台系统
基于大数据+爬虫+数据可视化+SpringBoot+Vue的虚拟证券交易平台
基于大数据爬虫+Hadoop+数据可视化+SpringBoo的电影数据分析与可视化平台
基于python+大数据爬虫技术+数据可视化+Spark的电力能耗数据分析与可视化平台
基于SpringBoot+Vue四川自驾游攻略管理系统设计和实现
基于SpringBoot+Vue+安卓APP计算机精品课程学习系统设计和实现
基于微信小程序+Springboot线上租房平台设计和实现-三端
基于Java+SpringBoot+Vue前后端分离手机销售商城系统设计和实现
基于Java+SpringBoot+Vue前后端分离仓库管理系统设计实现
基于SpringBoot+uniapp微信小程序校园点餐平台详细设计和实现
基于Java+SpringBoot+Vue+echarts健身房管理系统设计和实现
基于JavaSpringBoot+Vue+uniapp微信小程序实现鲜花商城购物系统
基于Java+SpringBoot+Vue前后端分离摄影分享网站平台系统
基于Java+SpringBoot+Vue前后端分离餐厅点餐管理系统设计和实现
项目案例:






为什么选择我
博主本身从事开发软件开发、有丰富的编程能力和水平、累积给上千名同学进行辅导、全网累积粉丝超过50W。是CSDN特邀作者、博客专家、新星计划导师、Java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和学生毕业项目实战,高校老师/讲师/同行前辈交流和合作。
源码获取:
大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻
精彩专栏推荐订阅:在下方专栏👇🏻
标签:
相关文章
最新发布
- 光流法结合深度学习神经网络的原理及应用(完整代码都有Python opencv)
- Python 图像处理进阶:特征提取与图像分类
- 大数据可视化分析-基于python的电影数据分析及可视化系统_9532dr50
- 【Python】入门(运算、输出、数据类型)
- 【Python】第一弹---解锁编程新世界:深入理解计算机基础与Python入门指南
- 华为OD机试E卷 --第k个排列 --24年OD统一考试(Java & JS & Python & C & C++)
- Python已安装包在import时报错未找到的解决方法
- 【Python】自动化神器PyAutoGUI —告别手动操作,一键模拟鼠标键盘,玩转微信及各种软件自动化
- Pycharm连接SQL Sever(详细教程)
- Python编程练习题及解析(49题)
点击排行
- 版本匹配指南:Numpy版本和Python版本的对应关系
- 版本匹配指南:PyTorch版本、torchvision 版本和Python版本的对应关系
- Python 可视化 web 神器:streamlit、Gradio、dash、nicegui;低代码 Python Web 框架:PyWebIO
- 相关性分析——Pearson相关系数+热力图(附data和Python完整代码)
- Anaconda版本和Python版本对应关系(持续更新...)
- Python与PyTorch的版本对应
- Windows上安装 Python 环境并配置环境变量 (超详细教程)
- Python pyinstaller打包exe最完整教程
本站推荐
