首页 > Python资料 博客日记
全网最适合入门的面向对象编程教程:53 Python 字符串与序列化-字符串与字符编码
2024-09-28 01:00:03Python资料围观81次
全网最适合入门的面向对象编程教程:53 Python 字符串与序列化-字符串与字符编码
摘要:
在 Python 中,字符串是文本的表示,默认使用 Unicode 编码,这允许你处理各种字符集,字符编码是将字符转换为字节的规则,常见的编码包括UTF-8、UTF-16和ASCII。
原文链接:
往期推荐:
全网最适合入门的面向对象编程教程:00 面向对象设计方法导论
全网最适合入门的面向对象编程教程:01 面向对象编程的基本概念
全网最适合入门的面向对象编程教程:02 类和对象的 Python 实现-使用 Python 创建类
全网最适合入门的面向对象编程教程:03 类和对象的 Python 实现-为自定义类添加属性
全网最适合入门的面向对象编程教程:04 类和对象的Python实现-为自定义类添加方法
全网最适合入门的面向对象编程教程:05 类和对象的Python实现-PyCharm代码标签
全网最适合入门的面向对象编程教程:06 类和对象的Python实现-自定义类的数据封装
全网最适合入门的面向对象编程教程:07 类和对象的Python实现-类型注解
全网最适合入门的面向对象编程教程:08 类和对象的Python实现-@property装饰器
全网最适合入门的面向对象编程教程:09 类和对象的Python实现-类之间的关系
全网最适合入门的面向对象编程教程:10 类和对象的Python实现-类的继承和里氏替换原则
全网最适合入门的面向对象编程教程:11 类和对象的Python实现-子类调用父类方法
全网最适合入门的面向对象编程教程:12 类和对象的Python实现-Python使用logging模块输出程序运行日志
全网最适合入门的面向对象编程教程:13 类和对象的Python实现-可视化阅读代码神器Sourcetrail的安装使用
全网最适合入门的面向对象编程教程:全网最适合入门的面向对象编程教程:14 类和对象的Python实现-类的静态方法和类方法
全网最适合入门的面向对象编程教程:15 类和对象的 Python 实现-__slots__魔法方法
全网最适合入门的面向对象编程教程:16 类和对象的Python实现-多态、方法重写与开闭原则
全网最适合入门的面向对象编程教程:17 类和对象的Python实现-鸭子类型与“file-like object“
全网最适合入门的面向对象编程教程:18 类和对象的Python实现-多重继承与PyQtGraph串口数据绘制曲线图
全网最适合入门的面向对象编程教程:19 类和对象的 Python 实现-使用 PyCharm 自动生成文件注释和函数注释
全网最适合入门的面向对象编程教程:20 类和对象的Python实现-组合关系的实现与CSV文件保存
全网最适合入门的面向对象编程教程:21 类和对象的Python实现-多文件的组织:模块module和包package
全网最适合入门的面向对象编程教程:22 类和对象的Python实现-异常和语法错误
全网最适合入门的面向对象编程教程:23 类和对象的Python实现-抛出异常
全网最适合入门的面向对象编程教程:24 类和对象的Python实现-异常的捕获与处理
全网最适合入门的面向对象编程教程:25 类和对象的Python实现-Python判断输入数据类型
全网最适合入门的面向对象编程教程:26 类和对象的Python实现-上下文管理器和with语句
全网最适合入门的面向对象编程教程:27 类和对象的Python实现-Python中异常层级与自定义异常类的实现
全网最适合入门的面向对象编程教程:28 类和对象的Python实现-Python编程原则、哲学和规范大汇总
全网最适合入门的面向对象编程教程:29 类和对象的Python实现-断言与防御性编程和help函数的使用
全网最适合入门的面向对象编程教程:30 Python的内置数据类型-object根类
全网最适合入门的面向对象编程教程:31 Python的内置数据类型-对象Object和类型Type
全网最适合入门的面向对象编程教程:32 Python的内置数据类型-类Class和实例Instance
全网最适合入门的面向对象编程教程:33 Python的内置数据类型-对象Object和类型Type的关系
全网最适合入门的面向对象编程教程:34 Python的内置数据类型-Python常用复合数据类型:元组和命名元组
全网最适合入门的面向对象编程教程:35 Python的内置数据类型-文档字符串和__doc__属性
全网最适合入门的面向对象编程教程:36 Python的内置数据类型-字典
全网最适合入门的面向对象编程教程:37 Python常用复合数据类型-列表和列表推导式
全网最适合入门的面向对象编程教程:38 Python常用复合数据类型-使用列表实现堆栈、队列和双端队列
全网最适合入门的面向对象编程教程:39 Python常用复合数据类型-集合
全网最适合入门的面向对象编程教程:40 Python常用复合数据类型-枚举和enum模块的使用
全网最适合入门的面向对象编程教程:41 Python常用复合数据类型-队列(FIFO、LIFO、优先级队列、双端队列和环形队列)
全网最适合入门的面向对象编程教程:42 Python常用复合数据类型-collections容器数据类型
全网最适合入门的面向对象编程教程:43 Python常用复合数据类型-扩展内置数据类型
全网最适合入门的面向对象编程教程:44 Python内置函数与魔法方法-重写内置类型的魔法方法
全网最适合入门的面向对象编程教程:45 Python实现常见数据结构-链表、树、哈希表、图和堆
全网最适合入门的面向对象编程教程:46 Python函数方法与接口-函数与事件驱动框架
全网最适合入门的面向对象编程教程:47 Python函数方法与接口-回调函数Callback
全网最适合入门的面向对象编程教程:48 Python函数方法与接口-位置参数、默认参数、可变参数和关键字参数
全网最适合入门的面向对象编程教程:49 Python函数方法与接口-函数与方法的区别和lamda匿名函数
全网最适合入门的面向对象编程教程:50 Python函数方法与接口-接口和抽象基类
全网最适合入门的面向对象编程教程:51 Python函数方法与接口-使用Zope实现接口
全网最适合入门的面向对象编程教程:52 Python函数方法与接口-Protocol协议与接口
更多精彩内容可看:
给你的 Python 加加速:一文速通 Python 并行计算
一个MicroPython的开源项目集锦:awesome-micropython,包含各个方面的Micropython工具库
SenseCraft 部署模型到Grove Vision AI V2图像处理模块
文档和代码获取:
可访问如下链接进行对文档下载:
https://github.com/leezisheng/Doc

本文档主要介绍如何使用 Python 进行面向对象编程,需要读者对 Python 语法和单片机开发具有基本了解。相比其他讲解 Python 面向对象编程的博客或书籍而言,本文档更加详细、侧重于嵌入式上位机应用,以上位机和下位机的常见串口数据收发、数据处理、动态图绘制等为应用实例,同时使用 Sourcetrail 代码软件对代码进行可视化阅读便于读者理解。
相关示例代码获取链接如下:https://github.com/leezisheng/Python-OOP-Demo
正文
字符串与字符编码
字符串是 Python 中的基本类型,它所代表的是一组不可变的字符(即无法直接修改字符串的某一索引对应的字符,需要转换为列表处理),某种程度上可以认为字符串是特殊的元组类型。
Python 中的字符串都是通过 Unicode 表示的,Unicode 是一个字符编码标准,那么什么是字符编码标准呢?实际上,在计算机科学中,数据的处理与存储均基于二进制系统。对于文本信息的处理,需先将其转化为数字形式以适应计算机的运算逻辑。在计算机体系结构中,早期的设计以 8 位二进制数,即一字节,作为基本单位。数字形式以适应计算机的运算逻辑。在计算机体系结构中,早期的设计以 8 位二进制数,即一字节,作为基本单位。因此,一个字节所能表示的最大整数值为 255,这是由二进制数 11111111 转化为十进制数得出的结果。对于更大整数的表示,则需通过增加字节数来实现。例如,两个字节可表示的最大整数值为 65535,而四个字节则可表示的最大整数值高达 4294967295。
鉴于计算机技术的发源地是美国,早期的字符编码主要基于 ASCII 标准,仅涵盖 127 个字符,包括大小写英文字母、数字和一些常用符号。然而,对于非英文字符,如中文,单个字节的编码方式显然不足以满足需求。为此,中国制定了 GB2312 编码标准,采用至少两个字节的编码方式来表示中文字符,并确保与 ASCII 编码的兼容性。在全球范围内,不同的语言和文化背景导致了多样化的编码标准,如日本的 Shift_JIS 和韩国的 Euc-kr。这些不同的编码标准在多语言混合的文本环境中可能导致显示乱码的问题。Unicode 又被称为统一码、万国码;它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。****从这个角度来讲,我们可以把字符串看作一个不可变的 Unicode 字符序列。
Unicode 标准详细阐释了字符如何以码位(code point)的形式进行表达。码位的取值范围限定在 0 至 0x10FFFF 的整数范围内,理论上涵盖了大约 110 万个可能的值,但实际分配的数字并未达到这一规模。在 Unicode 标准以及本文的论述中,码位采用 U+265E 的表述方式,用以指代值为 0x265e 的字符,其十进制表示为 9822。
此外,Unicode 标准汇编了众多表格,这些表格详尽地列出了众多字符及其对应的码位信息。
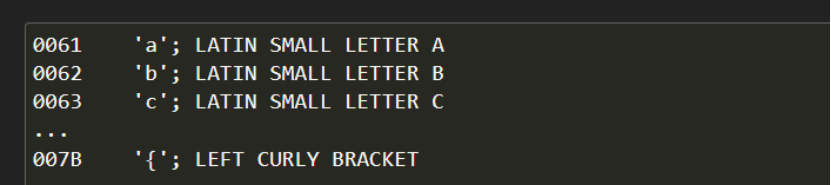
上一段可以归结为:一个 Unicode 字符串是一系列码位(从 0 到 0x10FFFF 或者说十进制的 1,114,111 的数字)组成的序列。这一序列在内存中需被表示为一组码元(code unit),码元会映射成包含八个二进制位的字节。将 Unicode 字符串翻译成字节序列的规则称为字符编码,或者编码。
大家首先会想到的编码可能是用 32 位的整数作为代码位,然后采用 CPU 对 32 位整数的表示法。字符串“Python”用这种表示法可能会如下所示:

这种表示法非常直白,但也存在一些问题:
- (1)不具可移植性;不同的处理器的字节序不同;
- (2)非常浪费空间:在大多数文本中,大部分码位都小于 127 或 255,因此字节 0x00 占用了大量空间。相较于 ASCII 表示法所需的 6 个字节,以上字符串需要占用 24 个字节;
- (3)与现有的 C 函数(如 strlen())不兼容,因此需要采用一套新的宽字符串函数。
因此这种编码用得不多,人们转而选择其他更高效、更方便的编码,比如 UTF-8。UTF-8 是最常用的编码之一,Python 往往默认会采用它。UTF 代表“Unicode Transformation Format”,'8'表示编码采用 8 位数。
UTF-8 编码把一个 Unicode 字符根据不同的数字大小编码成 1-6 个字节,常用的英文字母被编码成 1 个字节,汉字通常是 3 个字节,只有很生僻的字符才会被编码成 4-6 个字节。如果你要传输的文本包含大量英文字符,用 UTF-8 编码就能节省空间。UTF-8 编码还有一个额外的好处,就是 ASCII 编码实际上可以被看成是 UTF-8 编码的一部分,所以,大量只支持 ASCII 编码的历史遗留软件可以在 UTF-8 编码下继续工作。
实际上,Unicode 可使用下列任何一种字符编码方案来编码:
- (1)UTF-8 :UTF-8 是 Unicode 的一种可变长度编码形式,它透明地保留了 ASCII 字符代码值。该形式在 Solaris Unicode 语言环境中用作文件代码。
- (2)UTF-16:UTF-16 是 Unicode 的一种 16 位编码形式。在 UTF-16 中,多达 65,535 个字符被编码为单个 16 位值。映射在 65,535 到 1,114,111 的字符被编码为成对的 16 位值(代理)。
- (3)UTF-32:UTF-32 是 Unicode 的一种固定长度的 21 位编码形式,通常用在 32 位容器或数据类型中。该形式在 Solaris Unicode 语言环境中用作进程代码(宽字符代码)。
字符串常见操作
从 Python 3.0 开始,str 类型包含了 Unicode 字符,这意味着用"unicode rocks!"、'unicode rocks!' 或三重引号字符串语法创建的任何字符串都会存储为 Unicode。
需要注意的是,Python 不支持单字符类型,单字符在 Python 中也是作为一个字符串使用。
str 类拥有大量的方法,使得字符串的操作更加简单。通过 Python 解释器中的 dir 和 help 指令可以得知所有方法的用法。
print(help(str))
这里对于字符串的基本方法应用和运算不做赘述,仅在下文中总结一个文档。本章重点在于帮助大家了解字符编码、序列化对象及应用正则表达式解析字符串并匹配任意模式。下表中我们列出来 str 类的常见方法和作用。
| 方法 | 作用 |
|---|---|
| lower\upper | 返回 S 字符串的小写、大写格式。对于以下背景为蓝色、红色的这些方法,需要注意输入的字符串是不会被改变的,而是返回一个全新的 str 实例。 |
| title\capital | 前者返回 S 字符串中所有单词首字母大写且其他字母小写的格式,后者返回首字母大写、其他字母全部小写的新字符串。 |
| swapcase | swapcase()对 S 中的所有字符串做大小写转换(大写--> 小写,小写--> 大写)。 |
| istitle | 注意它并不会严格执行英语语法定义中的标题格式,例如,Leigh Hunt 的诗 The Glove and the Lions 应该是一个合法的标题,尽管它并不是所有单词的首字母都大写了。Robert Service 的 The Gremation of Sam McGee 也是一个合法的标题,尽管最后一个单词中间含有大写字母。 |
| isdecimal | 检查字符串是否只包含十进制字符。字符串中若只包含十进制字符返回 True,否则返回 False。该方法只存在于 unicode 对象中。注意:定义一个十进制字符串,只需要在字符串前添加前缀 'u' 即可。 |
| isdigit | 检测字符串是否只由数字组成,字符串中至少有一个字符且所有字符都是数字则返回 True,否则返回 False。 |
| Isnumeric | 检测字符串是否只由数字组成。这种方法是只适用于 unicode 对象。字符串中只包含数字字符,则返回 True,否则返回 False。在使用 isdigit、isdecimal 和 isnumeric 方法时要注意许多 Unicode 字符也被认为是数字,而不仅仅是我们习惯使用的 10 个阿拉伯数字。更糟的是,我们用小数点组成的浮点数在字符串中并不会被认为是小数,因此对于'45.2'来说,isdecimal()返回的是 False。真正的小数点字符 Unicode 中的值是 0660,因此 45.2 应该是 45\u06602。再者,这些方法不会验证字符串是否是合法的数字,对于"127.0.0.1"来说这 3 个方法都会返回 True。 |
| isalnum | 检测字符串是否由字母和数字组成。str 中至少有一个字符且所有字符都是字母或数字则返回 True,否则返回 False。 |
| isalpha | 检测字符串是否只由字母组成。字符串中至少有一个字符且所有字符都是字母则返回 True,否则返回 False。 |
| Center(width[, fillchar]) | 将字符串居中,左右两边使用 fillchar 进行填充,使得整个字符串的长度为 width。fillchar 默认为空格。如果 width 小于字符串的长度,则无法填充直接返回字符串本身(不会创建新字符串对象)。 |
| ljust/rjust | ljust()使用 fillchar 填充在字符串 S 的右边,使得整体长度为 width。rjust()则是填充在左边。如果不指定 fillchar,则默认使用空格填充。如果 width 小于或等于字符串 S 的长度,则无法填充,直接返回字符串 S(不会创建新字符串对象)。 |
| zfill | 用 0 填充在字符串 S 的左边使其长度为 width。如果 S 前右正负号 +/- ,则 0 填充在这两个符号的后面,且符号也算入长度。如果 width 小于或等于 S 的长度,则无法填充,直接返回 S 本身(不会创建新字符串对象)。 |
| Count(sub[, start[, end]]) | 返回字符串 S 中子串 sub 出现的次数,可以指定从哪里开始计算(start)以及计算到哪里结束(end),索引从 0 开始计算,不包括 end 边界。 |
| endswith/startswith | endswith() 检查字符串 S 是否已 suffix 结尾,返回布尔值的 True 和 False。suffix 可以是一个元组(tuple)。可以指定起始 start 和结尾 end 的搜索边界。同理 startswith()用来判断字符串 S 是否是以 prefix 开头。 |
| find\rfind\index\rindex | find()搜索字符串 S 中是否包含子串 sub,如果包含,则返回 sub 的索引位置,否则返回"-1"。可以指定起始 start 和结束 end 的搜索位置。index()和 find()一样,唯一不同点在于当找不到子串时,抛出 ValueError 错误。rfind()则是返回搜索到的最右边子串的位置,如果只搜索到一个或没有搜索到子串,则和 find()是等价的。 |
| Translate\maketrans | str.maketrans()生成一个字符一一映射的 table,然后使用 translate(table)对字符串 S 中的每个字符进行映射。可以用该方法实现字符串的简单加密。注意,maketrans(x[, y[, z]]) 中的 x 和 y 都是字符串,且长度必须相等。 |
| partition(sep)/rpartition(sep) | 搜索字符串 S 中的子串 sep,并从 sep 处对 S 进行分割,最后返回一个包含 3 元素的元组:sep 左边的部分是元组的第一个元素,sep 自身是元组的二个元素,sep 右边是元组的第三个元素。partition(sep) 从左边第一个 sep 进行分割, rpartition(sep) 从右边第一个 sep 进行分割。如果搜索不到 sep,则返回的 3 元素元组中,有两个元素为空。partition()是后两个元素为空,rpartition()是前两个元素为空。以下几个字符串方法返回或作用于字符串。 |
| Split(sep=None,maxsplit=-1)Rsplit(sep=None,maxsplit=-1)Splitlines([keepends]) | 都是用来分割字符串,并生成一个列表。split()根据 sep 对 S 进行分割,maxsplit 用于指定分割次数,如果不指定 maxsplit 或者给定值为"-1",则会从做向右搜索并且每遇到 sep 一次就分割直到搜索完字符串。如果不指定 sep 或者指定为 None,则改变分割算法:以空格为分隔符,且将连续的空白压缩为一个空格。rsplit()和 split() 是一样的,只不过是从右边向左边搜索。splitlines()用来专门用来分割换行符。可以指定各种换行符,常见的是\n、\r、\r\n 。如果指定 keepends 为 True,则保留所有的换行符。 |
| join(iterable) | 将可迭代对象(iterable)中的字符串使用 S 连接起来。注意,iterable 中必须全部是字符串类型,否则报错。它接受一个字符串列表作为参数,并返回列表中所有字符串通过原始字符串连接起来之后的字符串。 |
| strip\lstrip\rstrip | 分别是移除左右两边、左边、右边的字符 char。如果不指定 chars 或者指定为 None,则默认移除空白(空格、制表符、换行符)。唯一需要注意的是,chars 可以是多个字符序列。在移除时,只要是这个序列中的字符,都会被移除。 |
| replace(old, new, count) | 把 str 中的 old 替换成 new,如果 count 指定,则替换不超过 count 次.。 |
| expandtabs(N) | 将字符串 S 中的\t 替换为一定数量的空格。默认 N=8。注意, expandtabs(8)不是将\t 直接替换为 8 个空格。例如 'xyz\tab'.expandtabs() 会将\t 替换为 5 个空格,因为"xyz"占用了 3 个字符位。另外,它不会替换换行符( \n 或 \r )时。 |
关于这些方法具体使用,可以看以下链接:
https://pythonhowto.readthedocs.io/zh-cn/latest/string.html#
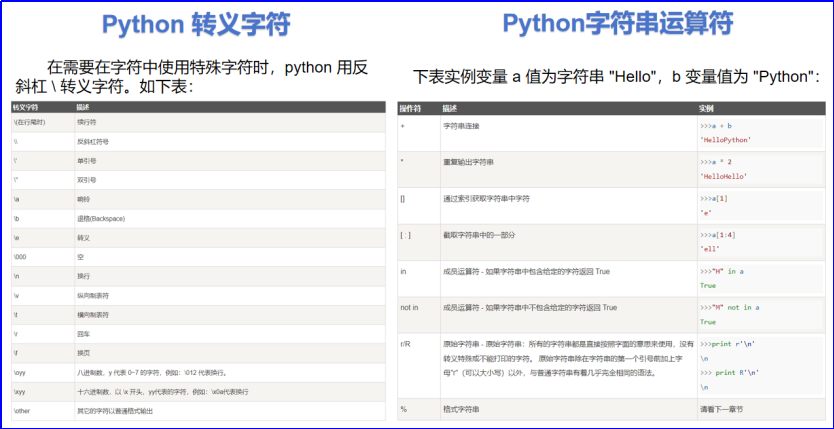
同时,这里我们回顾一下字符串的转义字符和运算符,参考菜鸟教程即可:

标签:
相关文章
最新发布
- 光流法结合深度学习神经网络的原理及应用(完整代码都有Python opencv)
- Python 图像处理进阶:特征提取与图像分类
- 大数据可视化分析-基于python的电影数据分析及可视化系统_9532dr50
- 【Python】入门(运算、输出、数据类型)
- 【Python】第一弹---解锁编程新世界:深入理解计算机基础与Python入门指南
- 华为OD机试E卷 --第k个排列 --24年OD统一考试(Java & JS & Python & C & C++)
- Python已安装包在import时报错未找到的解决方法
- 【Python】自动化神器PyAutoGUI —告别手动操作,一键模拟鼠标键盘,玩转微信及各种软件自动化
- Pycharm连接SQL Sever(详细教程)
- Python编程练习题及解析(49题)
点击排行
- 版本匹配指南:Numpy版本和Python版本的对应关系
- 版本匹配指南:PyTorch版本、torchvision 版本和Python版本的对应关系
- Python 可视化 web 神器:streamlit、Gradio、dash、nicegui;低代码 Python Web 框架:PyWebIO
- Anaconda版本和Python版本对应关系(持续更新...)
- 相关性分析——Pearson相关系数+热力图(附data和Python完整代码)
- Python与PyTorch的版本对应
- Windows上安装 Python 环境并配置环境变量 (超详细教程)
- Python pyinstaller打包exe最完整教程
本站推荐
