首页 > Python资料 博客日记
基于python的Selenium webdriver环境搭建(笔记)
2024-10-02 04:00:06Python资料围观73次
一、PyCharm安装配置Selenium环境
本文使用环境:windows11、Python 3.8.1、PyCharm 2019.3.3、Selenium 3.141.0
测试开发环境搭建综述
- 安装python和pycharm
- 安装浏览器
- 安装selenium
- 安装浏览器驱动
- 测试环境是否正确
这里我们直接从第三步开始
1.1 Seleium安装
在PyCharm终端或window命令窗口输入以下命令
#查看已安装的Python包(可跳过)
pip list
#安装Selenium 3.141.0
pip install selenium==3.141.0
#卸载Selenium命令
pip uninstall selenium
1.2 安装浏览器驱动
下载浏览器驱动,这里给出各浏览器(Chrome、Firefox、Edge等)的驱动,自行下载所需浏览器驱动。
Firefox(火狐)浏览器驱动
下载地址:Releases · mozilla/geckodriver · GitHub
Chrome(google)浏览器驱动
下载地址:http://chromedriver.storage.googleapis.com/index.html
Microsoft Edge (EdgeHTML)浏览器驱动
下载地址:Microsoft Edge WebDriver | Microsoft Edge Developer
将下载好的浏览器驱动放置在Python安装目录下,这里我们以火狐为例
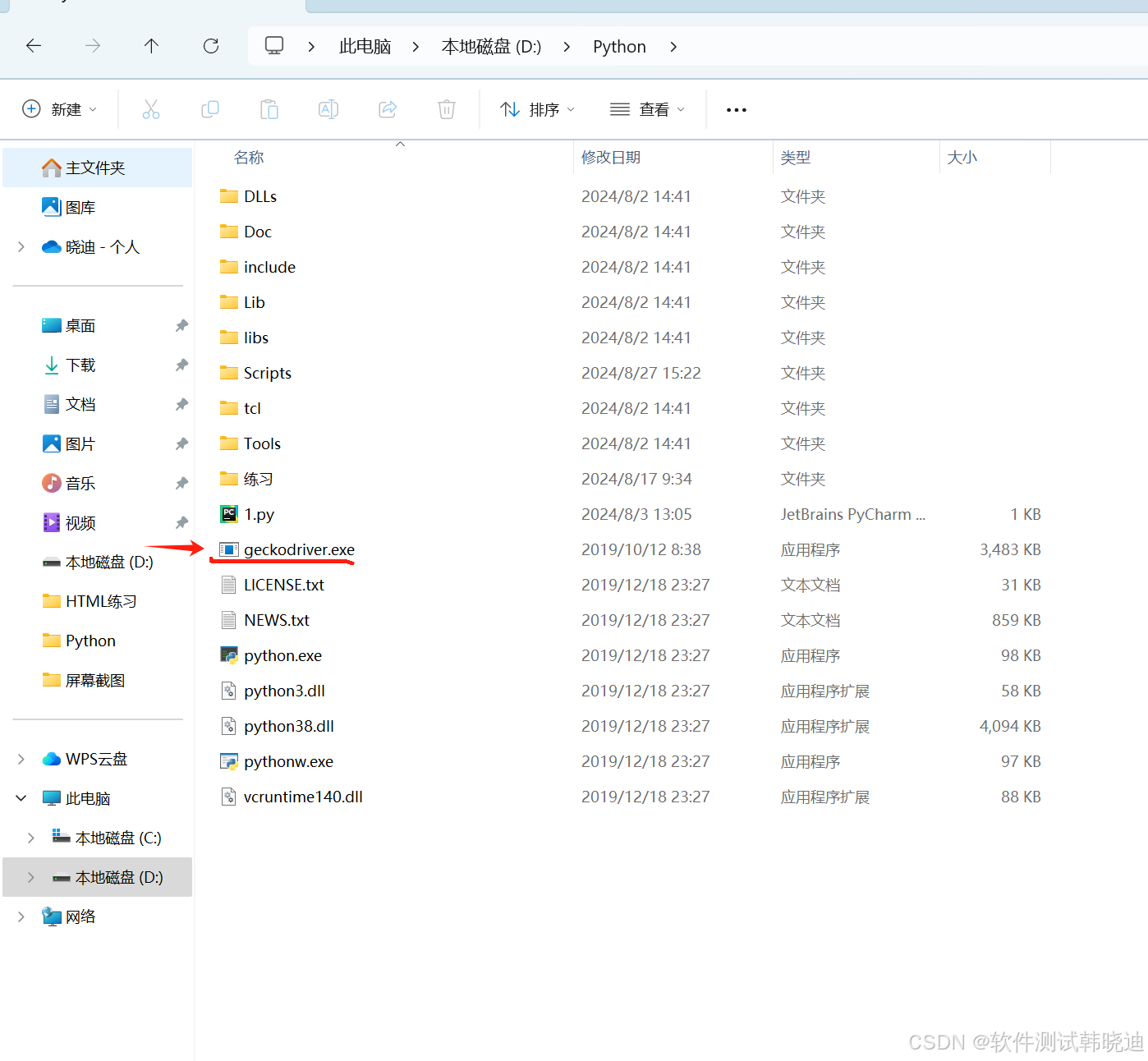
1.3 验证环境是否搭建成功
新建一个python文件,输入代码
WebDriver初步
- 导入webdriver(模块):from selenium import webdriver
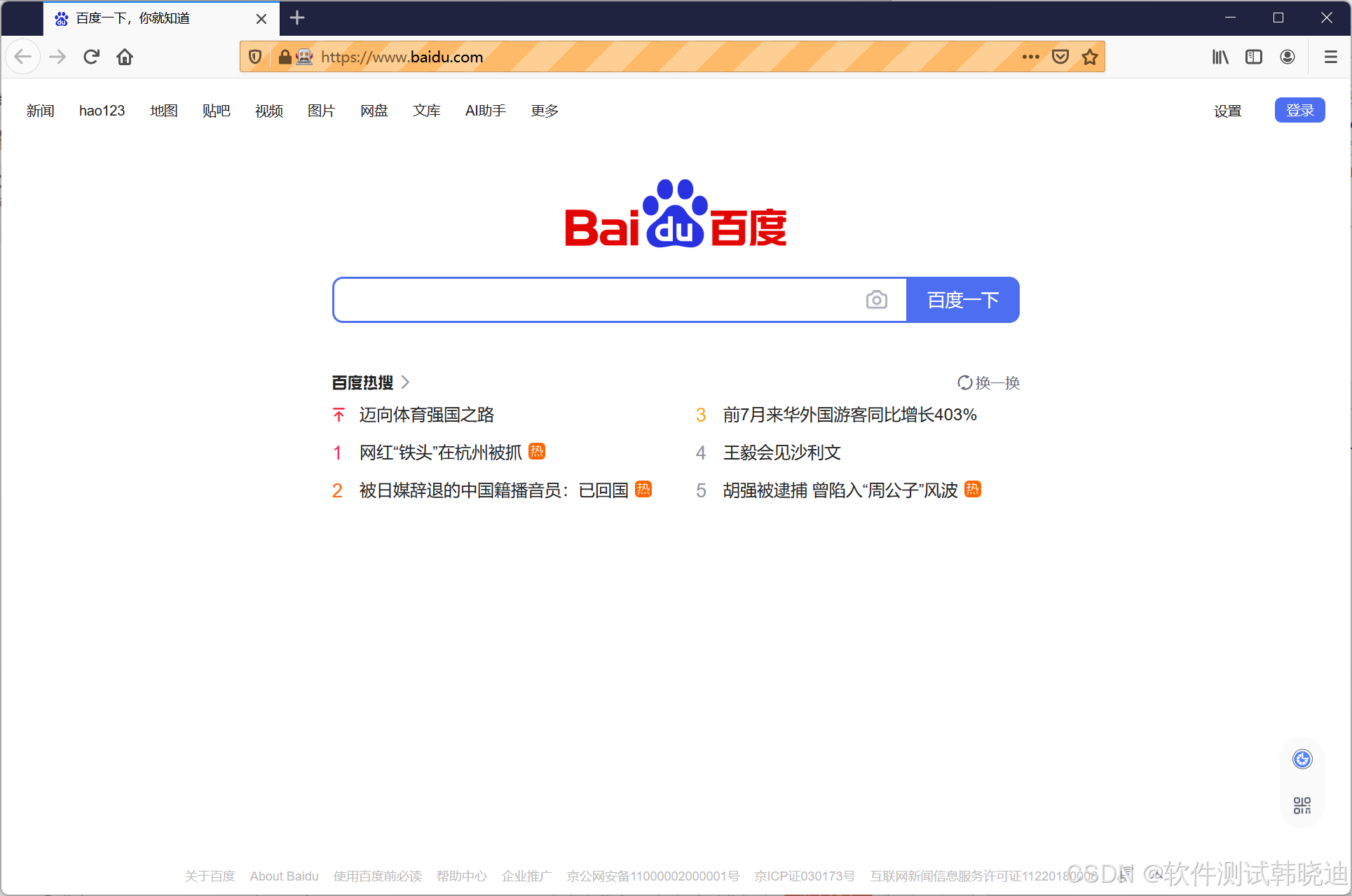
- 获得Firefox浏览器的驱动(实例化Firefox类):driver=webdriver.Firefox()
- 打开被测试页面:base_url="https://www.baidu.com"
- driver.get(base_url)
执行代码,火狐浏览器打开,环境搭建成功
二、Selenium WebDriver使用
定位元素方法概述
- 准确无误的找到页面中要操作的页面元素是自动化测试的第一步,页面元素由大量的超级链接、图片、文本框、按钮、下拉列表等组成,这些页面元素在HTML中对应各种标记和相应的标记属性,webdriver正是通过这些标记及标记属性来对页面元素进行识别定位的
- WebDriver提供了八种定位元素方式,并提供对应的方法:

- 针对八种定位方法,WebDriver还提供了另一套写法,即统一调用find_element()方法,通过类By来声明定位方法,并且闯入对应方法的定位参数
- 函数:find_element(定位类型,定位具体信息)
- 需要导入类By: from selenium.webdriver.common.by import By
- 另外八种定位方式及对应的方法:

2.1 id定位
- HTML规定id属性在HTML文档中必须是唯一的
如;
<input type=text id=username size=15>
<input type=password id=password size=15>
- WebDriver提供的id定位方法就是通过元素的id属性来查找定位元素
方法:
(1)find_element_by_ id("id属性值”)
(2)find_element(By.ID."id属性值”)
如:
driver=webdriver.Firefox()
(1)myname=driver.find element by id(“username”)
(2)myname=driver.find element(By.lD,“username”)
- 核心知识点
1.使用id定位元素



2.在文本框中输入:

3.单击按钮:


4.关闭浏览器
5.控制运行速度

id定位的eg:
2.2 name定位
- HTML规定name属性来指定元素的名称,在当前页面中可以不唯一
如:<input type=text id=count name=count>
- WebDriver提供的name定位方法就是通过元素的name属性来查找定位元素
方法:
find_element_by_name('name属性值')
find_element(By.NAME,'name属性值')
如:
driver=webdirver.Firefox()
mycount=driver.find_element_by_name('count')
mycount=driver.find_element(By.NAME,'count')
name定位的eg: 
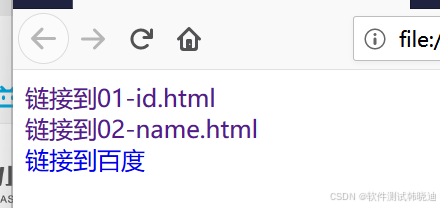
2.3 linktext定位
- WebDriver提供的linktext定位方法专门用于定位文本链接
方法:
find_element_by_link_text('链接文字')
find_element(By.LINK_TEXT,'链接文字')
如:

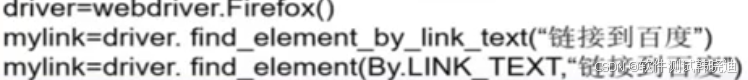
- 核心知识点:
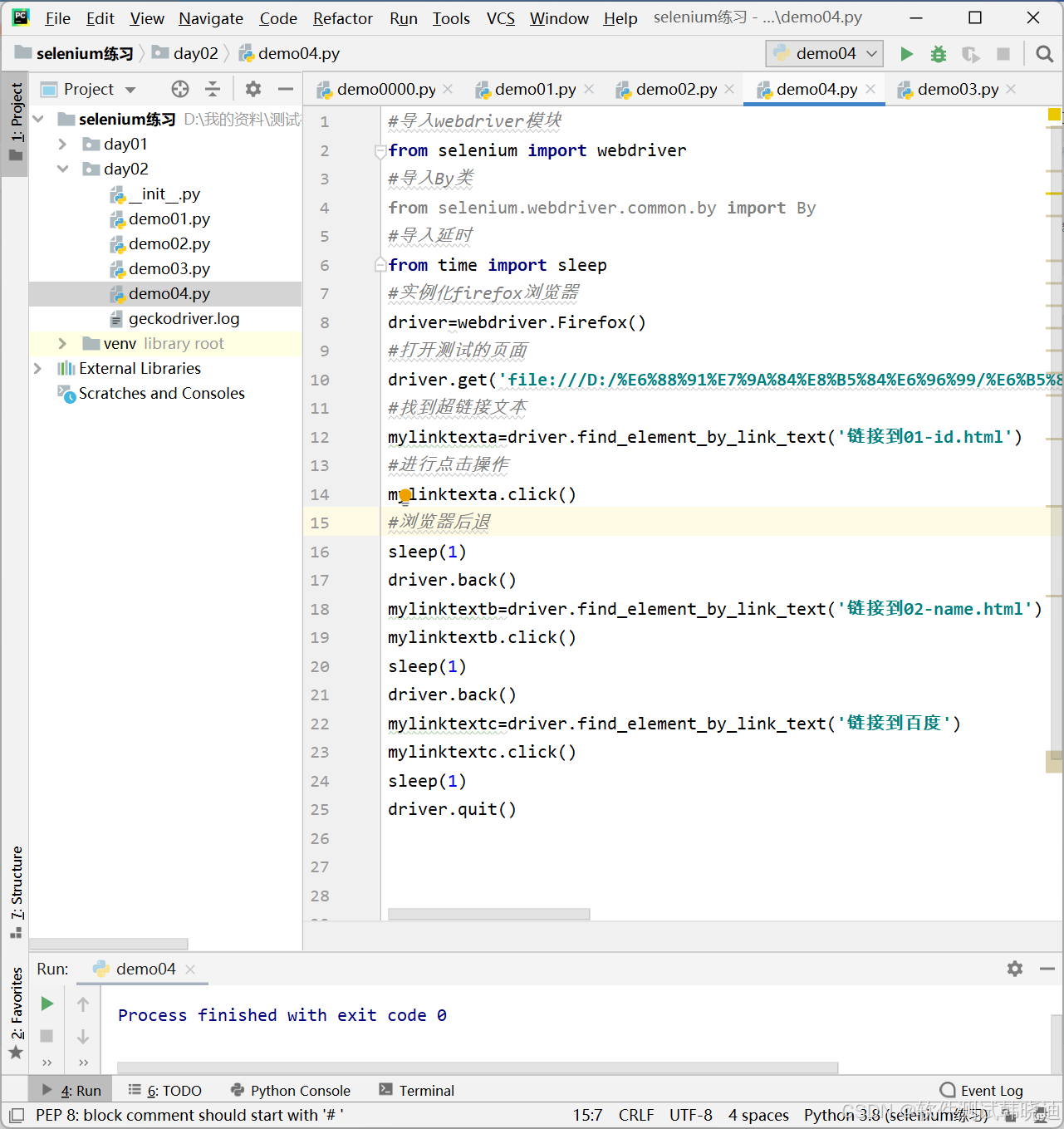
1.使用linktext定位元素
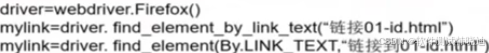
2.浏览器后退
linktext定位的eg:
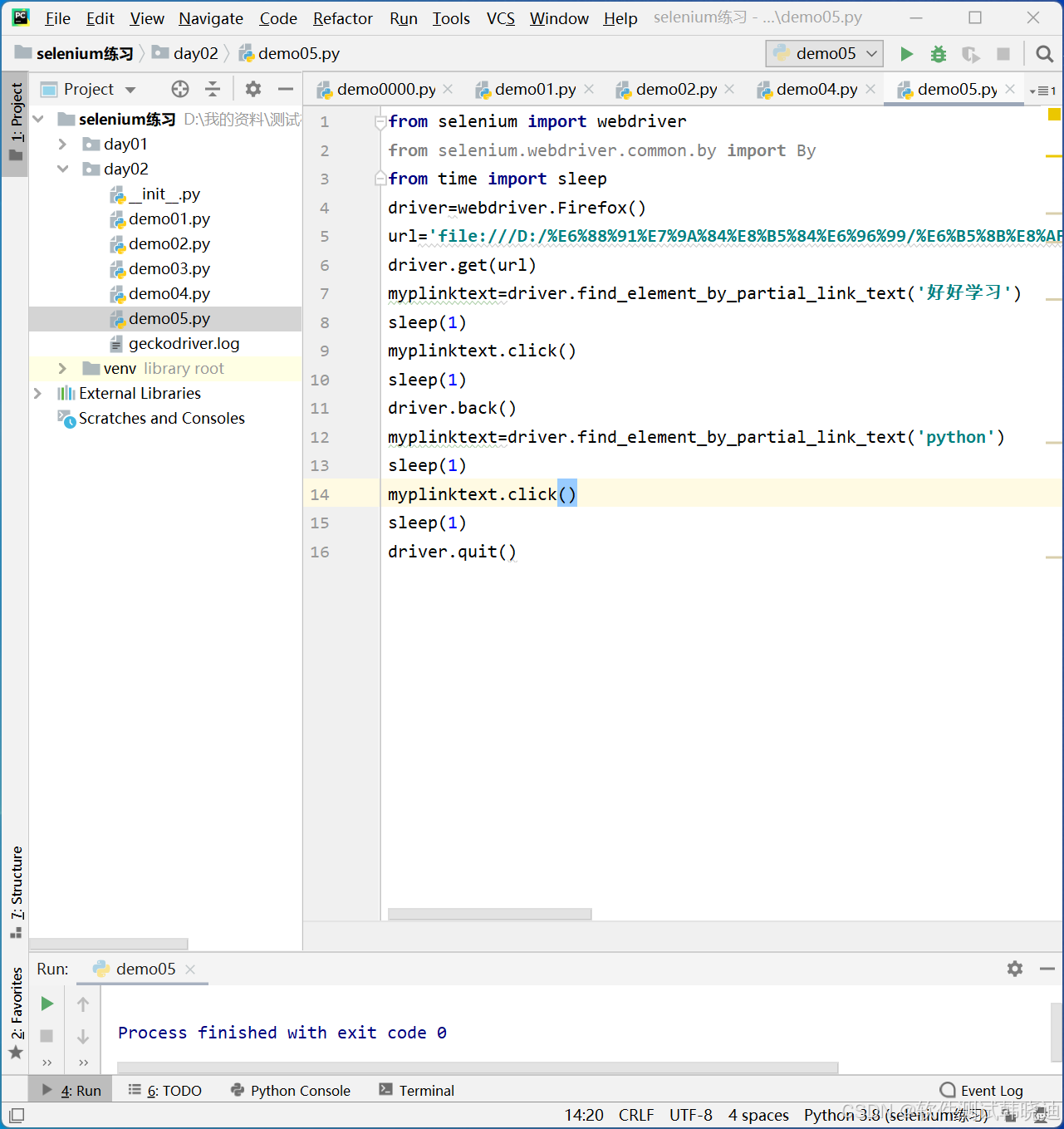
2.4 partial link text定位
- WebDriver提供的partial link text定位方法也是专门用于定位文本链接,作为link text方法的补充,适合于文本链接比较长的情况
方法:
find_element_by_partial_link_text('部分链接文字')
find_element(By.PARTIAL_LINK_TEXT,‘部分链接文字’)
如:

partial link text 定位的例子:
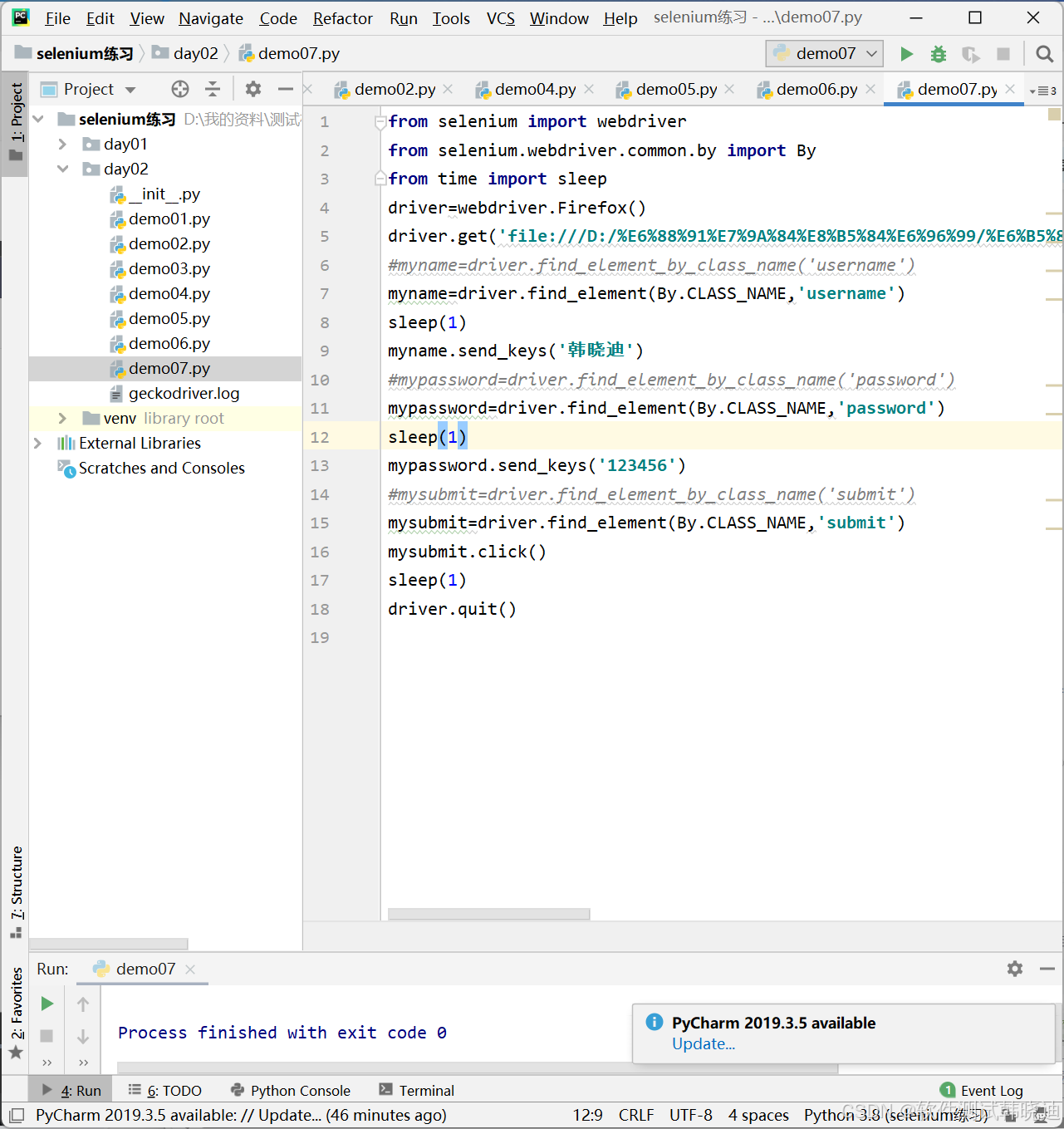
2.5 class定位
- HTLM规定class属性来指定元素的类名
如:
<input type=text class=username>
- WebDriver提供的class name定位方法就是通过元素的class属性来查找定位元素
方法:
find_element_by_class_name('class属性值')
find_element(By.CLASS_NAME,'class属性值')
如:
driver=webdriver.Firefox()
mylink=driver.find_element_by_class_name('username')
mylink=driver.find_element(By.CLASS_NAME,'username')
class定位例子:


2.6 tag name定位(不常用)
(基本不用,在现实情况中极少出现只有一个标记,有相同标记时,定位后只会在第一个标记处进行操作)
- HTML本质就是通过tag(标记)来定义实现不同的功能,每个元素本质上就是一个tag
- WebDriver提供的tag name定位方法就是通过元素的tag来查找定位元素
find_element by_tag_name(“tag name")
find element(By.TAG NAME,"tag name")
如:
driver=webdriver.Firefox()
mylink=driver.find element by tag name(“a”)
mylink=driver. find element(By.TAG NAME,“a”)
2.7 Xpath定位(万能方法)
2.7.1 什么是XML?
- 是eXtensible Markup Language的缩写,称为可扩展标记语言
- 是对HTML的扩展,所有的标记和标记中的属性可以自己定义

2.7.2 什么是XPath?
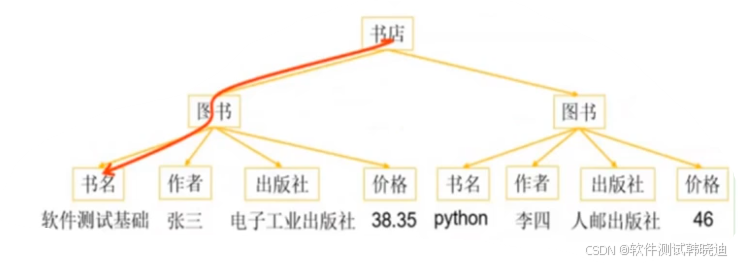
- XPath是XMLPath的缩写,称成XML路径语言
- XPath是在XML文档中查找信息的一种语言,可用来在XML文档中对元素和属性进行搜索
- XPath使用路径表达式来选取XML文档中的节点或节点集
- 如:/书店/图书[1]/书名
- 由于HTML文档本身就是一个标准的XML页面,所以可以使用XPath方法来定位页面元素
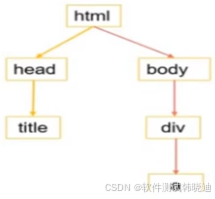
- HTML文档树型结构:

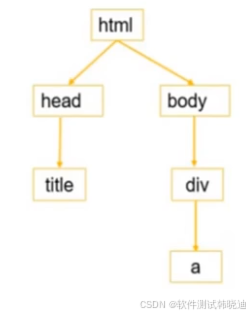
- Xpath路径表达式:
就是描述节点或节点集所在路径的表达式
如:
/html/body/div/a
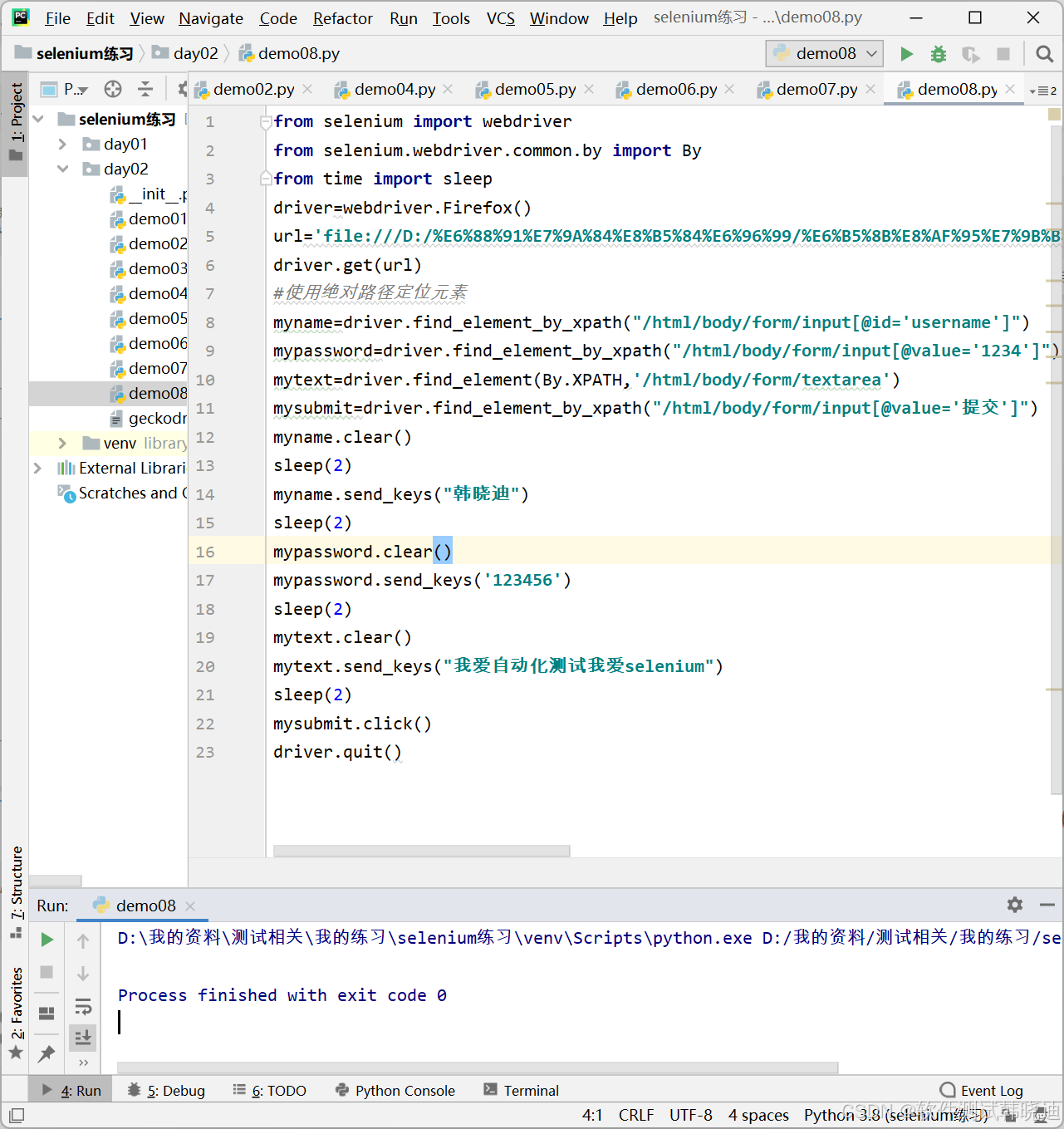
2.7.3 绝对路径XPath定位
绝对路径XPath表达式以斜线"/"开始,从HTML代码的最外层节点标记html开始,逐级描述节点的位置路径查找的时候,从根节点html开始,按照指定的路径逐级查找,直到找到想要的节点元素
示例:
1.选择根元素html
/html2.选择文本域textarea
/html/body/form/textarea
3.选择form下所有的input
/html/body/form/input
定位语句:
重点说明: /html/body/form/input[@value='姓名']
使用绝对路径查找以"/"开头
路径之间使用“/”进行分隔
为了精确定位,往往需要附加一些属性说明信息
- 属性说明使用方括号[]括起来
- 属性名称前使用@符号前缀
- 属性说明格式:节点名称[@属性名='属性值']
- 注意:属性值的引号,不要与外层的引号相同,外层用双,属性值用单,外层用单,属性值用双
优点:效率高
缺点:表达式较长,且可维护性不好
不推荐采用绝对定位方法,因为页面一旦发生变化,原有定位到XPath表达式就会失败
eg:

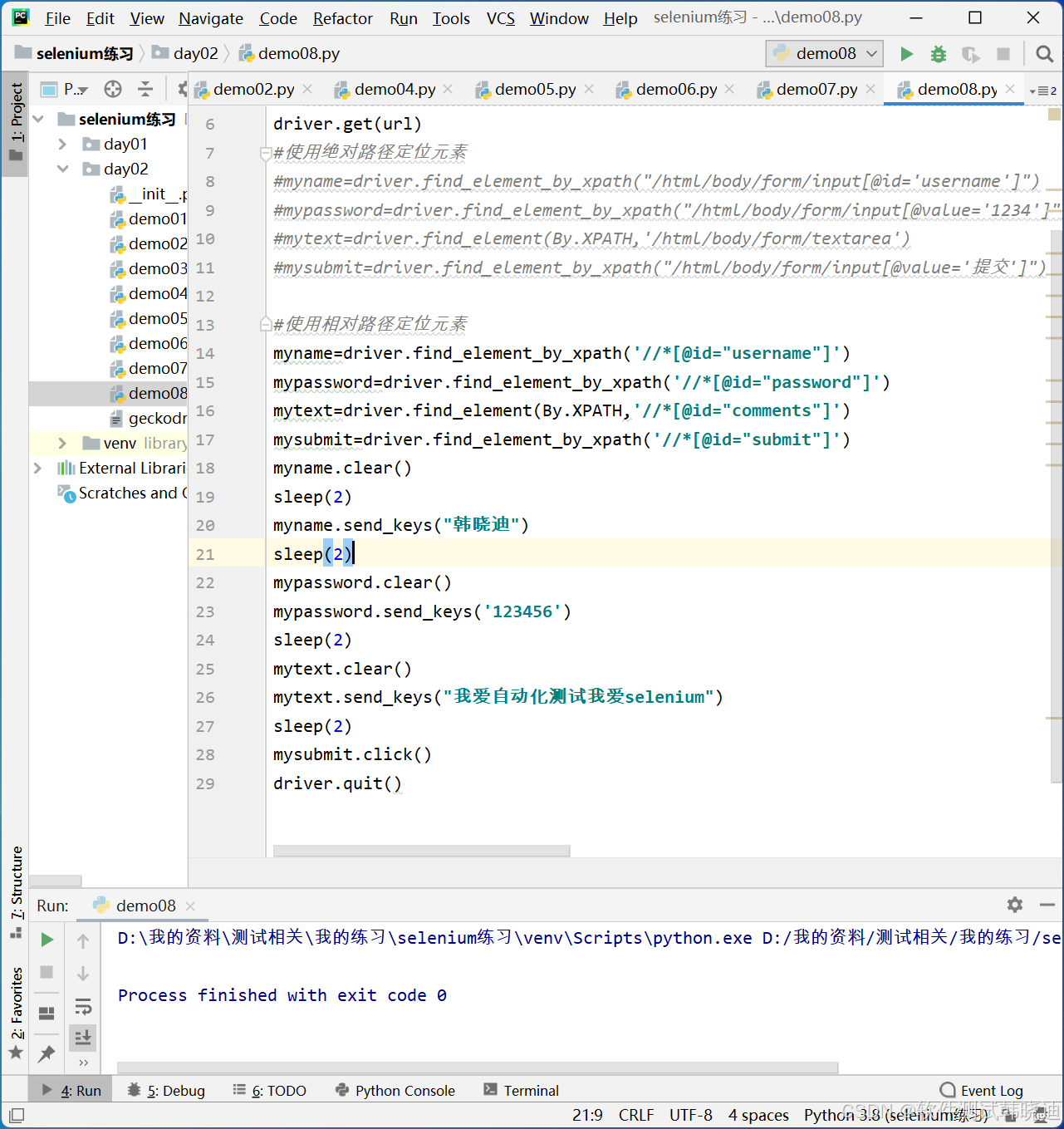
2.7.4 相对路径定位元素
相对路径Xpath表达式以双斜线“//”开始,表示在HTML文档中的全部层级位置进行查找索要定位元素
定位语句:
重点说明://input[@id='password']
使用相对路径查找以“//”开头,表示在HTML文档中的全部层级位置进行查找所有满足双斜线"//"之后规则的元素(无论层级关系)
优点:表达式简介,且可维护性好
缺点:效率低
推荐使用相对路径的XPath表达式,可以大大降低测试脚本中定位表达式的维护成本
eg:
2.8 css定位
2.8.1 什么是css
CSS(Cascading Style Sheets)中文意思是层叠样式单,是一种用于描述HTML和XML文件样式的前端页面语言,主要用于描述页面元素的展现和样式的定义
WebDriver提供CSS定位方式,对应的方法:
driver=webdriver.Firefox()
driver.find element by_css selector("css表达式")
driver.find element(By.CSS SELECTOR,"css表达式")
2.8.2 绝对路径css定位
- 绝对路径CSS表达式从HTML代码的最外层节点标记htm开始,逐级描述节点的位置路径
- 查找的时候,从根节点html开始,按照指定的路径逐级查找,直到找到想要的节点元素
- 使用大于号>作为路径的分隔符
- 如:html>body>form>textarea
精确定位基本语法:
html>body>form>input [value="姓名"]
Python定位语句:
driver=webdriver.Firefox()
myname=driver.find element by css selector("html>body>form>input[value="姓名"]myname=driver.find element(By.CSS_SELECTOR, html>body>form>input[value='姓名"])
拓展:
1.

在浏览器中可下载这个插件开启后,点击某个控件,直接出现对应控件的相对或绝对路径
2.

try xpath可以检查路径定位是否正确
1.在网页,点击键盘F12弹出查看器,点击左下角选取按钮,再点击想查看的元素
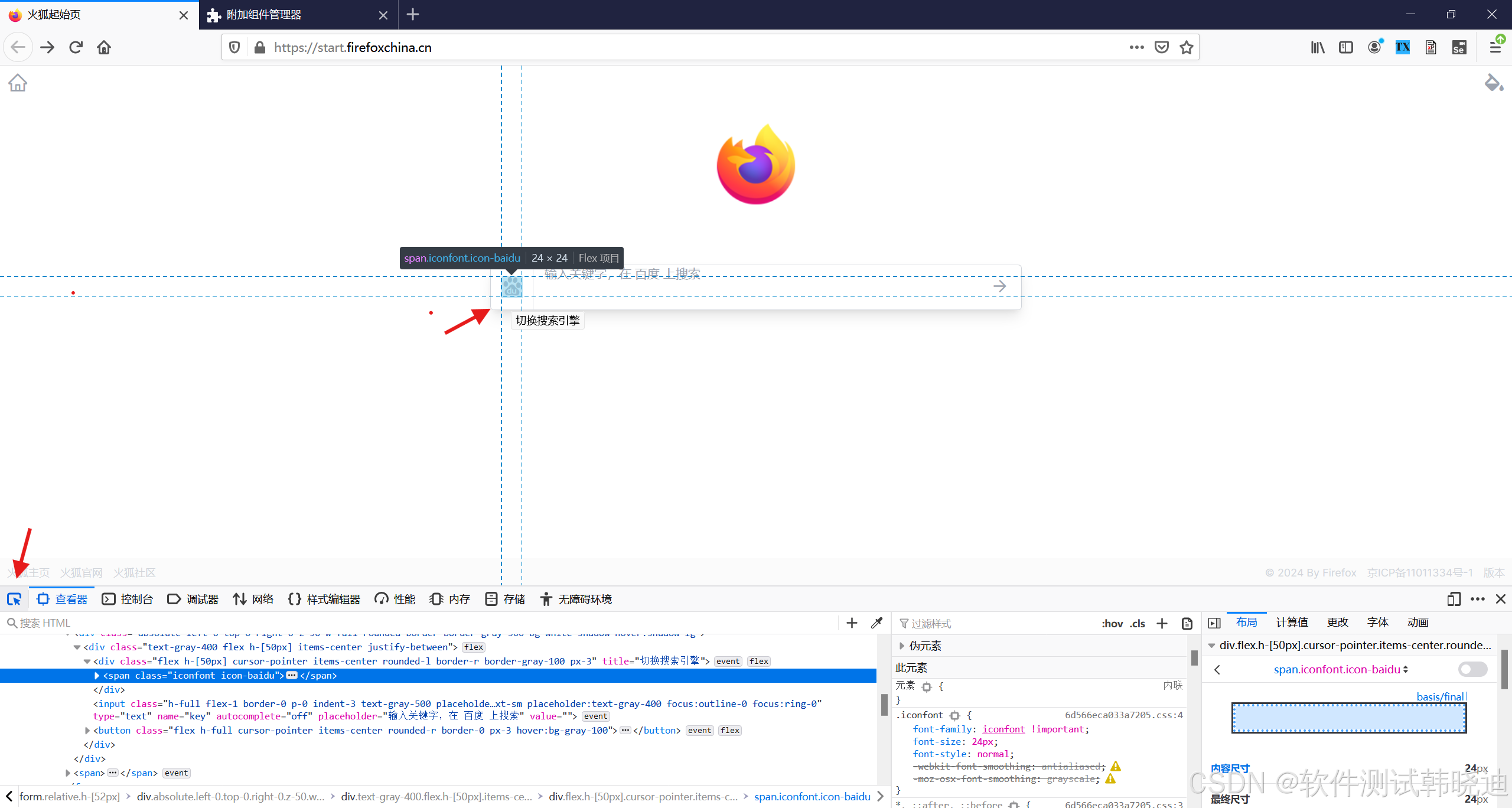
2.会定位相应的语句,在语句边右击然后点击‘复制’,xpath
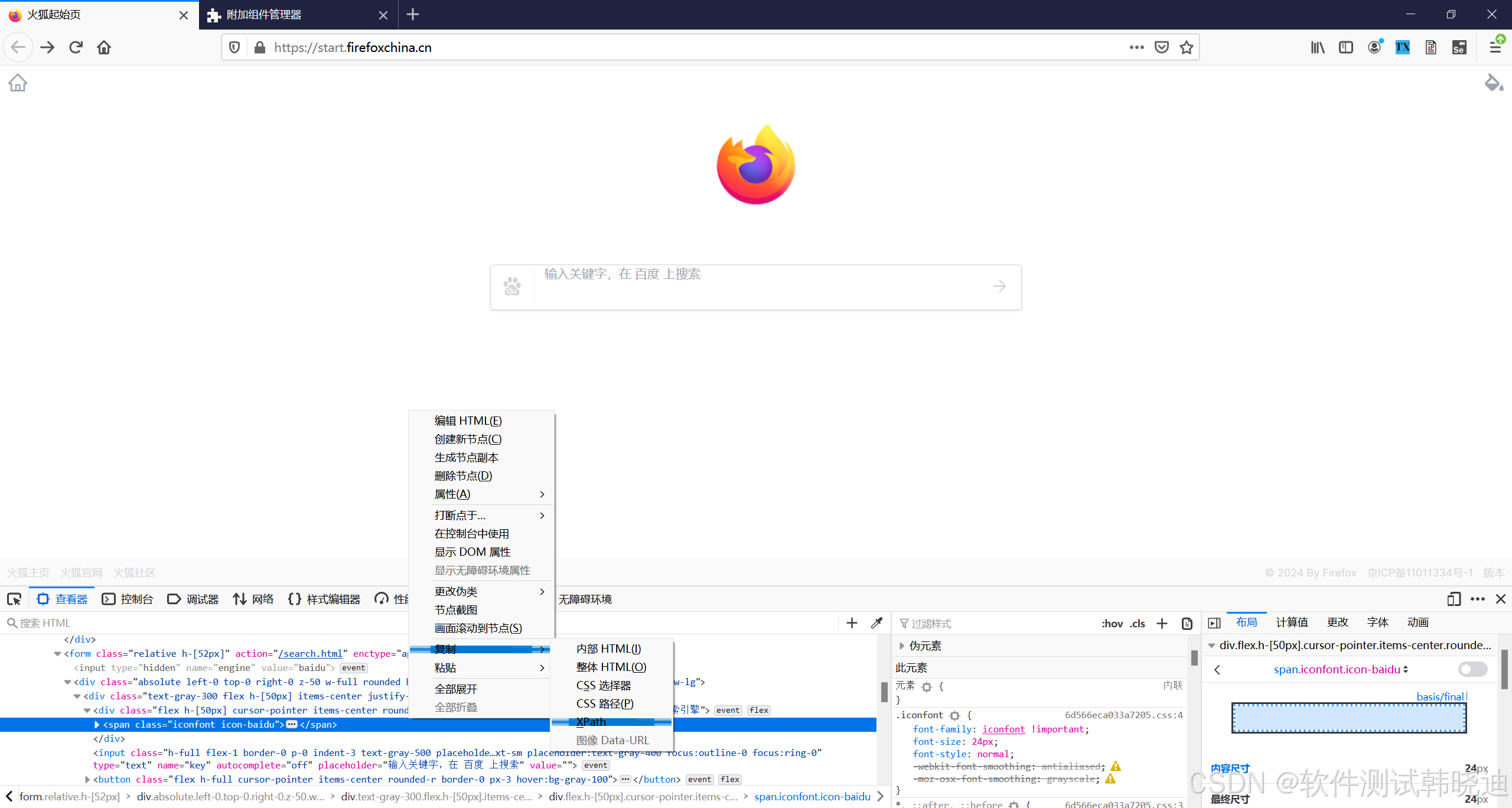
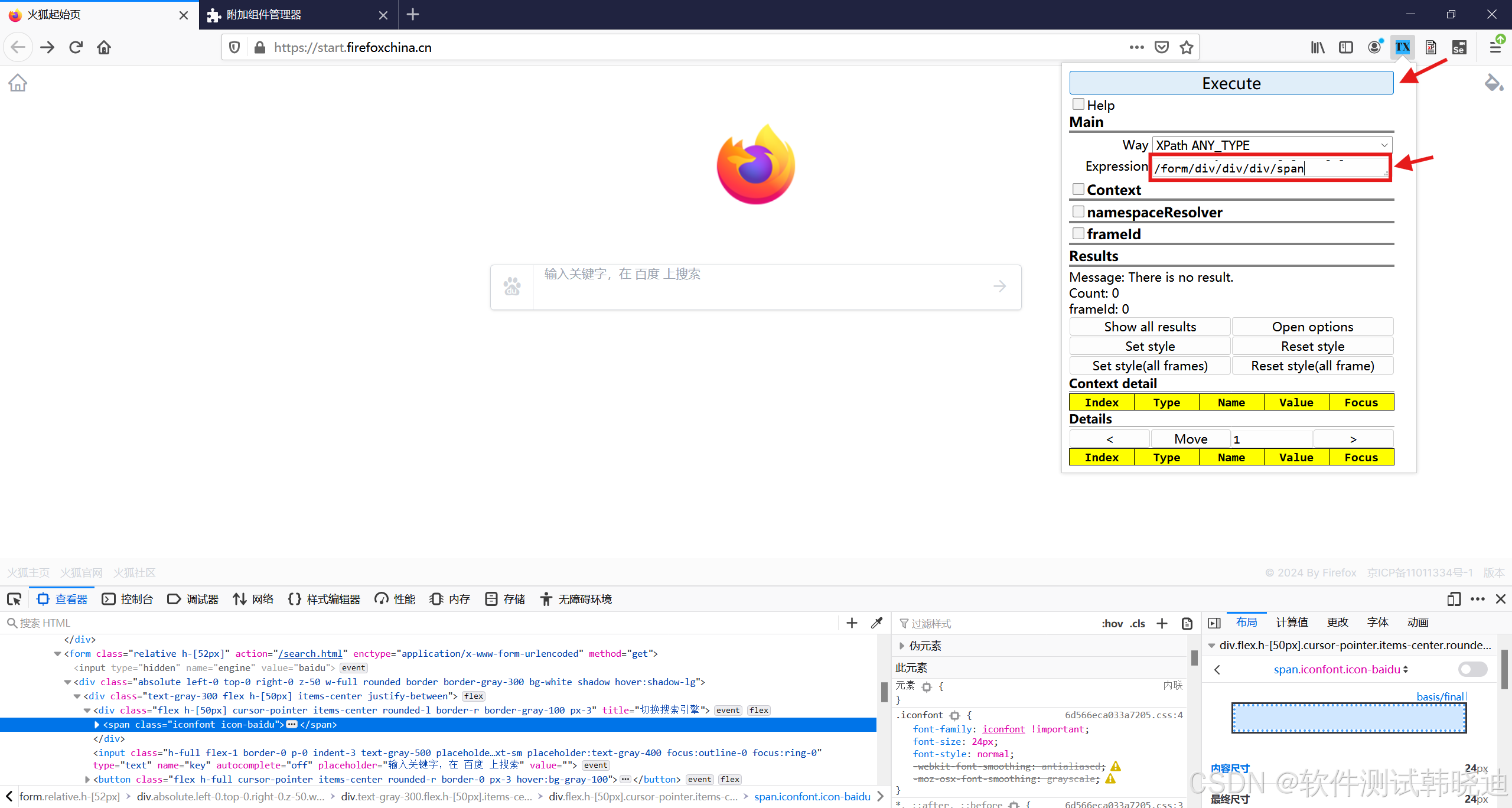
3.打开插件将复制的‘xpath’输入到‘Expression’,点击‘execute’按钮
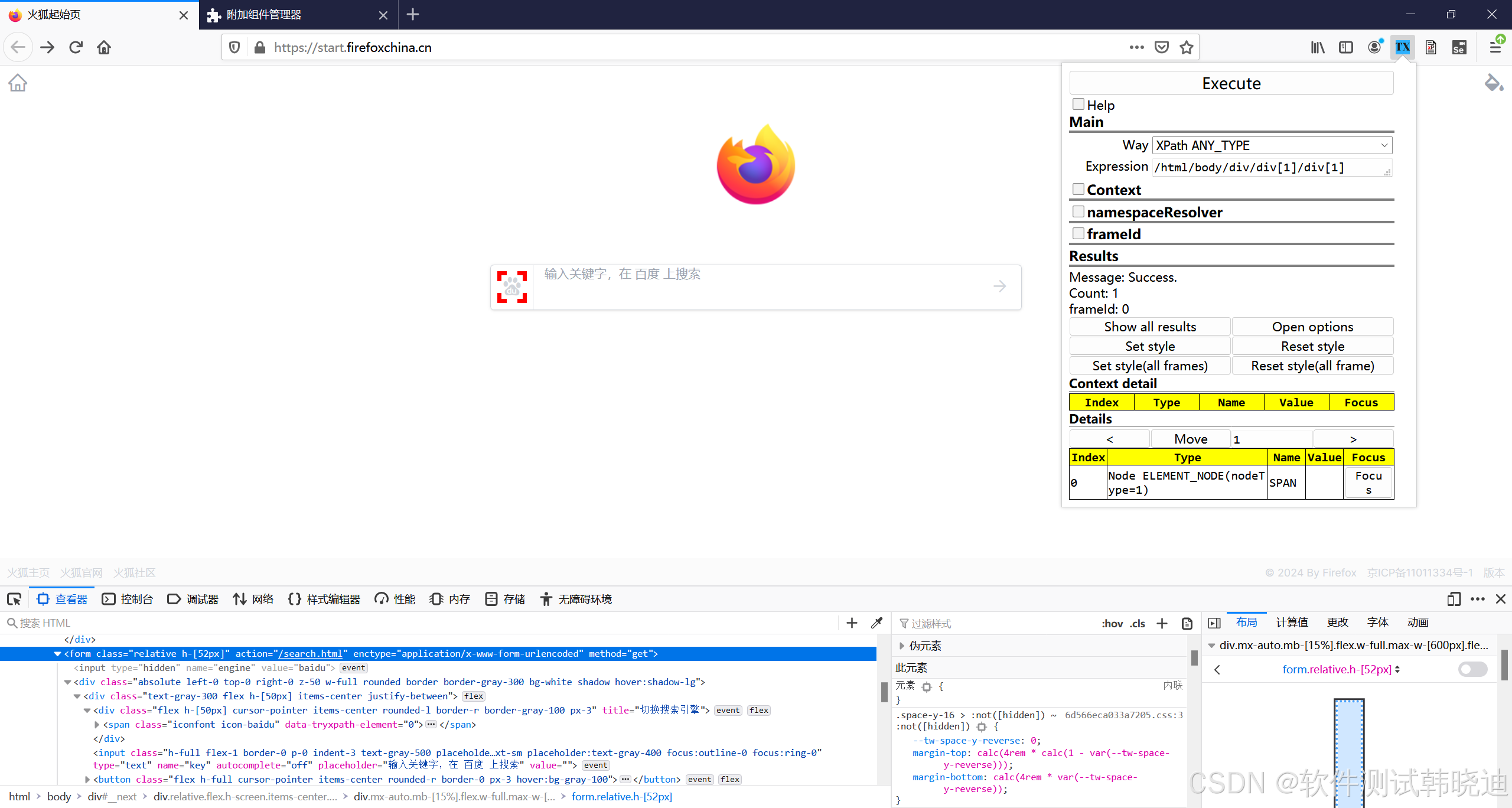
4.定位到相应的元素检查成功对应正确
2.8.3 相对路径css定位
- 相对路径表示在HTML文档中的全部层级位置进行查找所要定位元素
1.使用属性名="属性值":
input [id='password']
driver=webdriver.Firefox()
mypassword=driver.find element by css selector("input[id='password']")mypassword=driver.find element(By.CSS SELECTOR,"input[id='password’]")
2.使用属性:
input [checked]
driver=webdriver.Firefox()
mypassword=driver.find element by css selector("input[checked]")
mypassword=driver.find element(By.CSS SELECTOR,"input[checked]")
3.使用ID属性值:
input#password
driver=webdriver.Firefox()
mypassword=driver.find element by css selector("input#password")
mypassword=driver.find element(By.CSS SELECTOR,"input#password")
4.使用class属性值:
input.username
driver=webdriver.Firefox()
mypassword=driver.find element by css selector("input.username")
mypassword=driver.find element(By.CSS SELECTOR,"input.username")
三、谓语
3.1 谓语概述
什么是谓词:
XPath的谓词即筛选表达式,也就是附加筛选的条件,使定位元素更加精确,所有的条件,都写在方括号“[ ]"中,表示对前面的节点进行进一步的筛选说明,如://input[@id='password’]
常用的方法:
- 使用页面元素的属性值
- 使用页面元素的索引号
- 使用页面元素存在某属性
- 使用页面元素存在某子节点
- 使用页面元素的子节点值
3.2 使用页面元素的属性值
作用:当存在很多页面元素满足条件时,可以通过”属性名称=属性值”的方式定位元素
语法:节点名称[@属性名称="属性值”]
如:
//input[@id="username"]
3.3 使用页面元素的索引号
作用:当存在很多元素满足条件时,可以使用元素的索引号来定位元素
语法:节点名称[索引号]
注意:索引号从1开始
如:
//input[1]
3.4 使用页面元素存在某属性
作用:当存在很多节点满足条件时,如果某个元素拥有唯一的某个属性可以使用属性名称来定位该元素
语法:节点名称[@属性名称]
如:
//input[@checked]
3.5 使用页面元素存在某子节点
作用:当某节点自身不好定位时,但其有唯一的某个子节点,此时,可以查找这个子节点来定位父元素节点
语法:节点名称[子节点名称]
如:
//ul[lable]
3.6 使用页面元素的子节点值
作用:当某节点自身不好定位时,但其子节点包含唯一的值,此时,可以查找子节点值来定位父元素节点
语法:节点名称[子节点名称='子节点文本值']
如:
ul[li='足球']
四、多条件查找
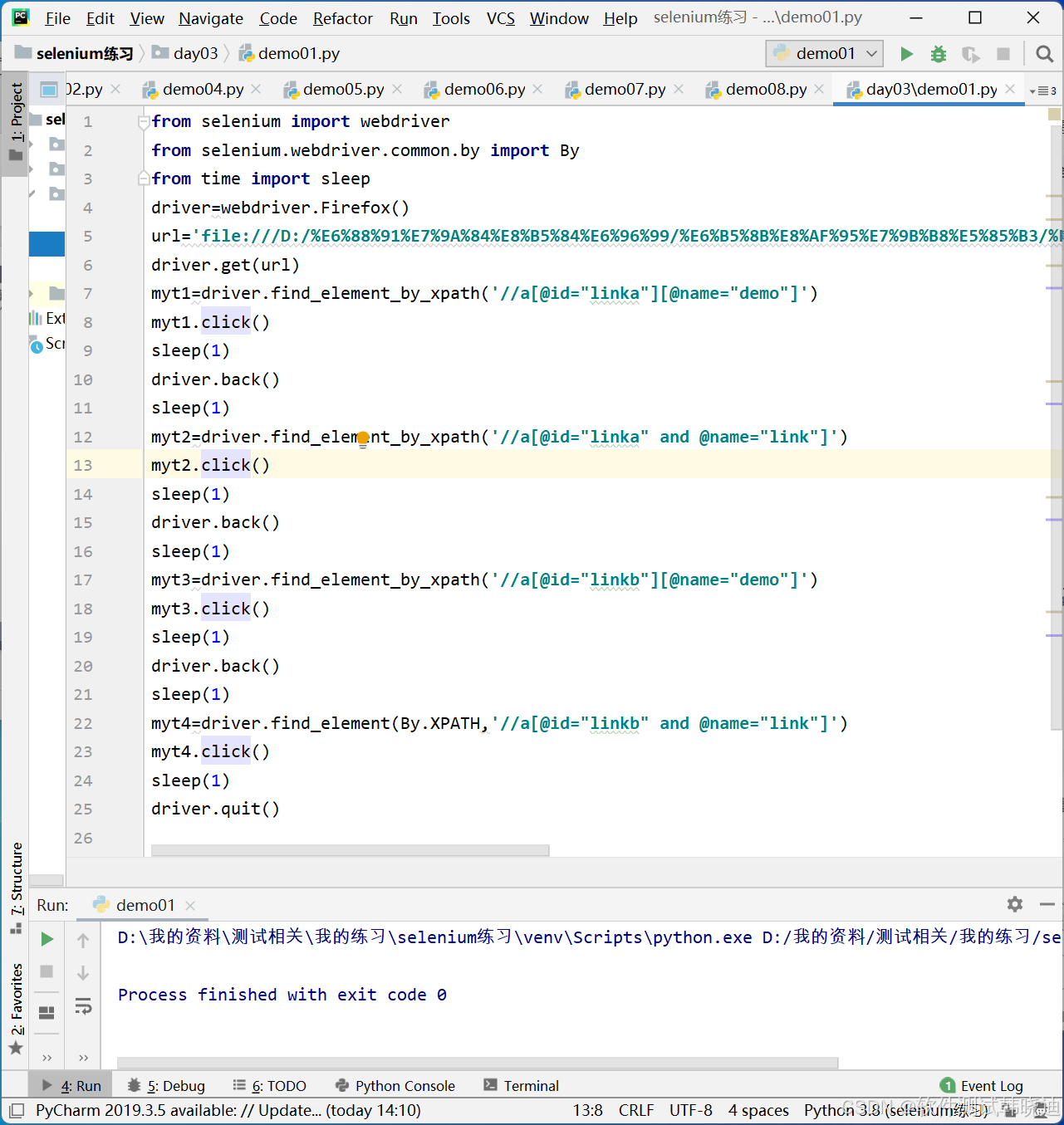
4.1多条件查找
如果通过一个属性信息不能定位到元素,可以通过多个属性信息进行定位
语法:
方法1://节点名称[@属性名1='属性值1'][@属性名2='属性值2']
方法2://节点名称[@属性名1='属性值1' and @属性名2='属性值2']
多条件查找eg:


4.2 通配符
"*"表示匹配任何元素节点
示例1:
//*[@id='username']査找任何id属性值等于username的元素节点
示例2:
//select[@name]/* 査找存在name属性的select节点的所有子节点
"@*"表示匹配任何属性
示例1
//input[@*='password']查找任何属性值等于password的input元素节
示例2
//select[@*]查找所有带有属性的select元素节点
示例3
//*[@*='汽车']查找任何属性等于“汽车”的所有元素节点
eg:
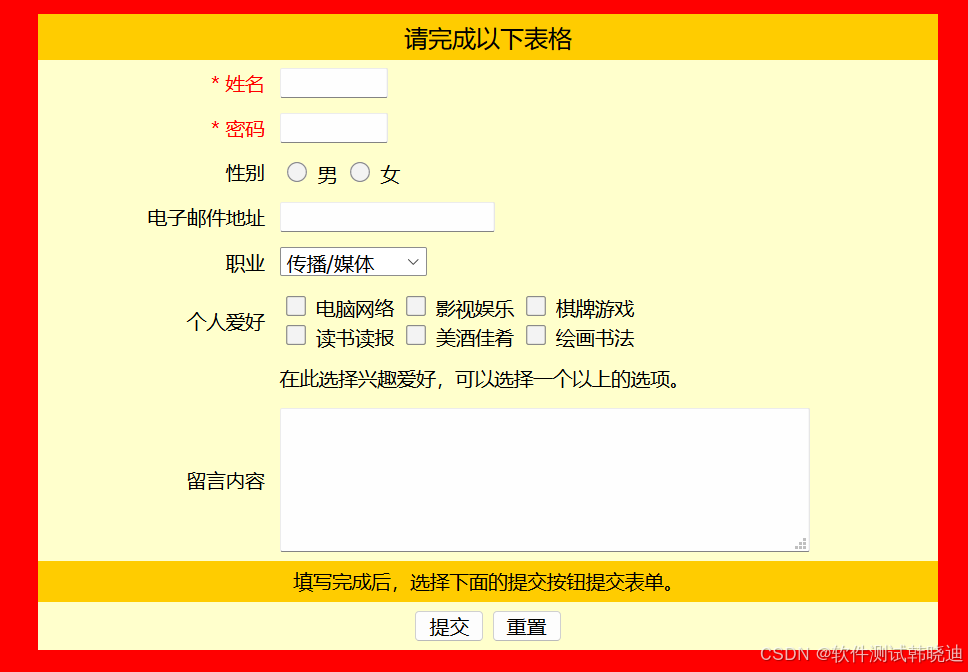
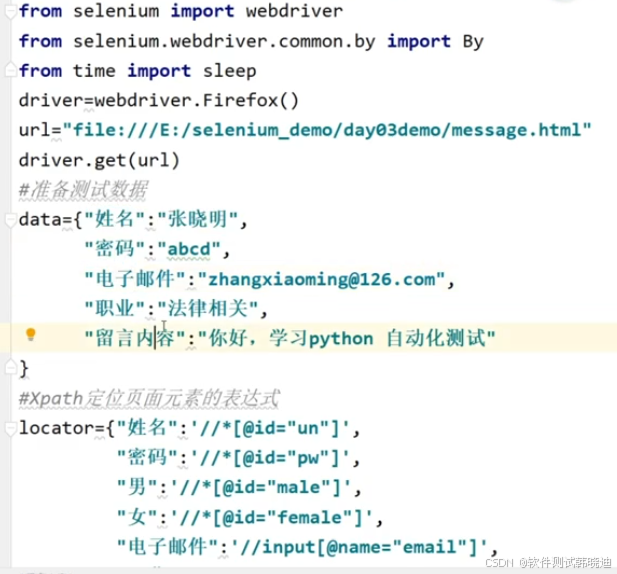



这样写方便后期维护
五、控件的使用
5.1 文本框和文本域的使用
文本框/输入框:<input type=text>
文本框常见属性:

文本域:<textarea>
文本域常见属性:

对文本框/文本域的主要操作:
- 输入文本:send_keys()
- 清空文本:clear()
- 获得文本框的属性值:get_attribute()
- 判断文本框是否可以:is_enable()
5.2 单选按钮和复选按钮使用
单选按钮:<input type=radio>
单选按钮常见属性:
对单选按钮主要操作:
- 点击:click()
- 是否选择:is_selected()
- 获得属性值:get_attribute()
复选框:<input type=checkbox>
复选框常见属性:
复选框主要操作:
- 点击:click()
- 是否选择:is_selected()
- 获得属性值:get_attribute()
5.3 超级链接使用
超级链接:<a href="连接文本">链接内容</a>
链接主要操作:
- 点击链接:click()
- 获取超级链接文本:text
图片:<img src="图片地址">
图片结合超级链接:<a href="网页URL"><img src="图片URL" alt="代替文本"></a>
图片链接主要操作:
- 点击:click()
5.4 键盘操作和浏览器操作使用
键盘操作使用:
keys类提供了键盘上几乎所有按键的操作
- 需要导入:from selenium.webdriver.common.keys import Keys
- 这些操作作为send_keys()方法的参数

浏览器的基本操作:
- 打开浏览器:get()
- 关闭浏览器:quit() 或者 close()
- 浏览器后退:back()
- 浏览器前进:forward()
- 获得当前页面的标题:title
- 获得当前页面的URL:current_url
- 设置浏览器窗口大小:set_window_size(宽,高)
- 设置浏览器窗口最大化/最小化:maximize_window() minimize_window()
5.5 下拉列表的基本使用
5.5.1 概述
下拉列表:<select>和<option>
下拉列表常见属性:
Select类是Webdriver的一个特定的类,用于与下拉列表和下拉菜单进行交互,它提供了丰富的功能和方法实现与用户的交互
导入Select类:
from selenium.webdriver.support.select import Select
5.5.2 下拉列表使用基本步骤
1、导入Select类
from selenium.webdriver.support.select import Select
2、定位下拉列表
list1=driver.find element(By.XPATH,"xpath表达式")
3、把定位的下拉列表封装为Select对象
s1=Select(list1)
4、使用Select对象的方法,操作选项
s1.select_by_index(1)
5.5.3 select对象
判断是否允许多选:is_multiple

获取所有的备选项:
option
text

选中选项:
- 通过选项索引值(索引从零开始):select_by_index(索引值)
- 通过选项的value属性值:select_by_value("value属性值")
- 通过备选项的文本值:select_by_visible_text("备选项")

获取所有以选中的选项:
all_selected_options
text

获取选中的第一个选项:
first_selected_option
text

取消选中选项:
- 通过选项索引值(索引从0开始):deselect_by_index(索引值)
- 通过选项的value属性值:deselect_by_value(“value属性值”)
- 通过备选项的文本值:deselect_by_visible_text("备选项")
- 取消所有选项:deselect all()

5.6 弹出对话框使用
网页中经常遇到使用JavaScript实现的各种类型的弹出对话框,一般用于给用户一些提示信息。
弹出对话框包括以下几个常见类型:
- 警告信息框alert
- 确认对话框confirm
- 输入提示框prompt
定位弹出对话框(切换到alert对象):
driver=webdriver.Firefox()
alert1=driver.switch_to.alert
获得文本提示信息:
text
点击确定按钮:
accept()
点击取消按钮:
dismiss()
5.7 窗口截图
截取当前操作页面的截图,对于检查自动化执行过程非常有帮助,尤其是在出现错误的情况下,通过截图可以直观的看出出现错误的原因
截图方法:
driver=webdriver.firefox()
driver.get_screenshot_as_file(截图存储位置)
六、Frame
6.1 Frame简介
网页中使用框架(Frame),实现在一个窗口中同时显示多个HTML页面
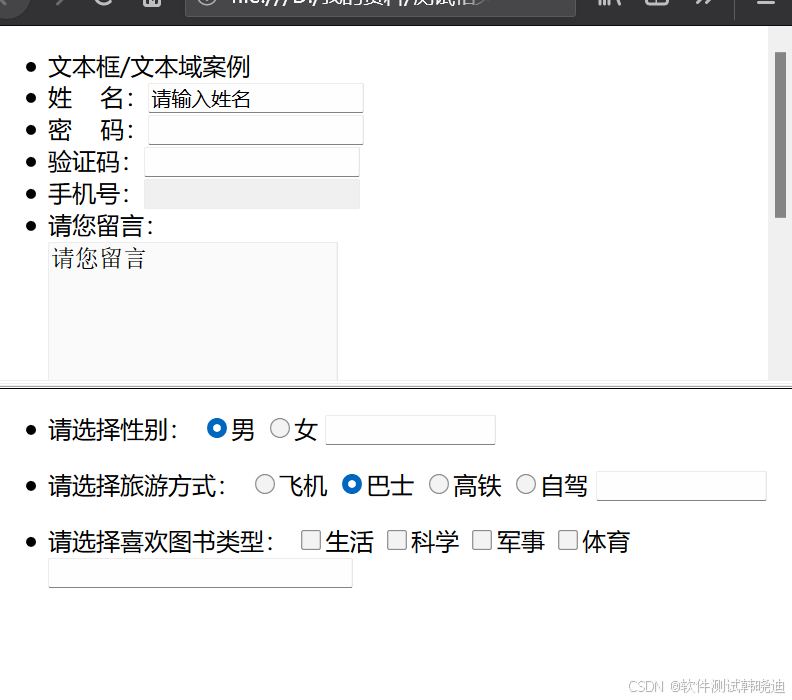
Frame要放在FramSet中,FrameSet使用时不使用Body每个Frame内都包含一个独立的html文件

实现在一个网页中嵌套另一个网页,Frame1、2放在body中

6.2 切换Frame
Frame处理步骤:
- 步骤一:切换到要处理的Frame
- 步骤二:在Frame中定位页面元素并进行操作
- 步骤三:返回当前处理Frame的上一级页面或主页面
- 对Frame中的页面进行进行定位、操作,需要切换到要处理的Frame:
switch_to.frame("frame的id属性值或name属性值")
如:driver.switch_to.frame("frame1")
- 说明:
1.默认情况下,switch_to.frame()可以直接取得frame的id属性值或name属性值
2.如果没有id和name属性,可以使用frame的索引号定位(索引号从0开始的整数)
- 也可以通过如下方式处理:
1.先定位到frame
frame1=driver.find_element(By.XPATH,"Xpath表达式")
2.再将定位对象传给switch_to.frame()函数
driver.switch_to.frame(frame1)
- 处理完当前Frame,需切换回当前处理frame的上一级页面或者主页面、
返回上一级页面:swich_to.parent_frame()
返回主页面:switch_to.default_content()
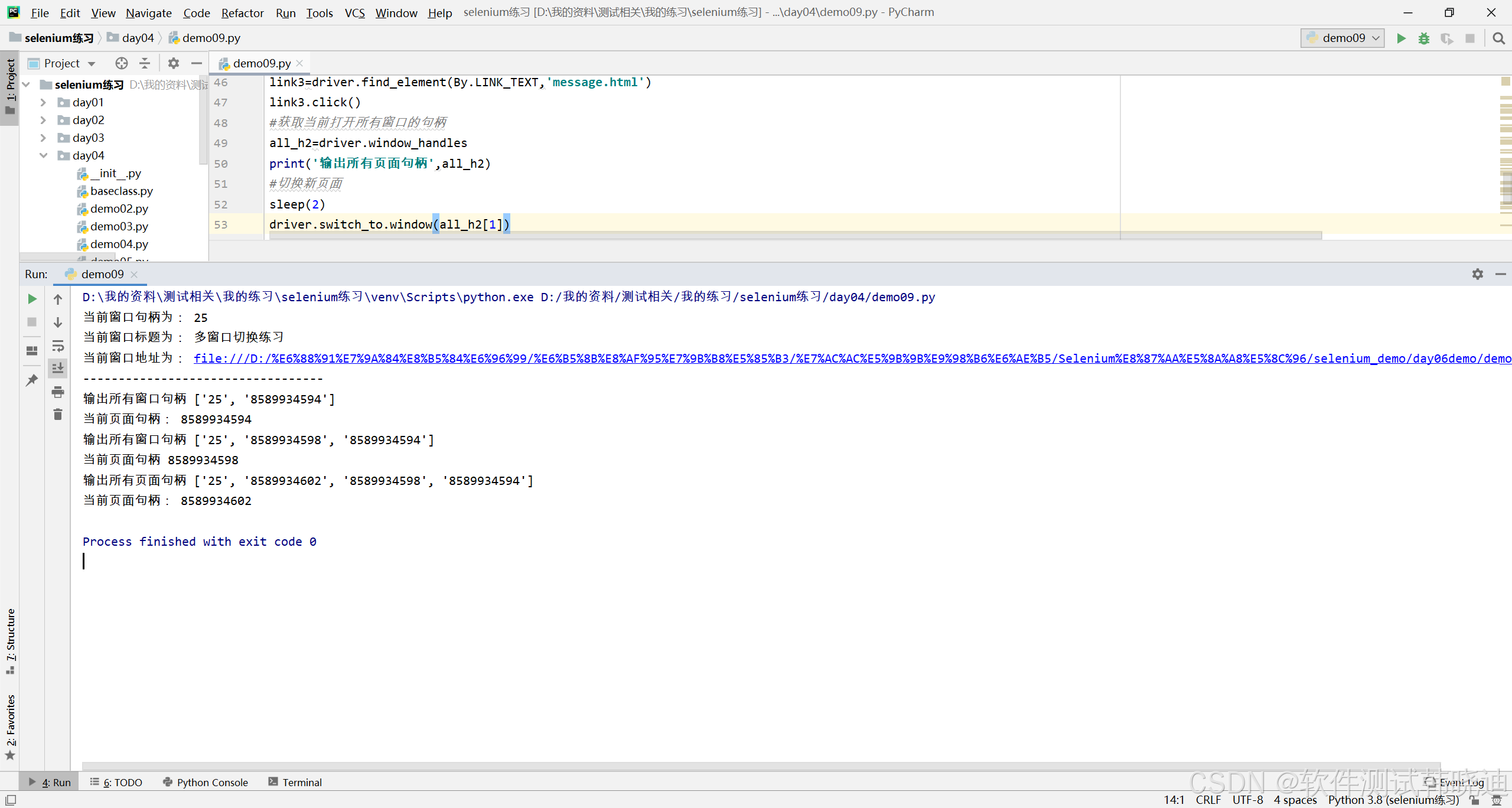
6.3 多窗口切换
在页面操作过程中经常会弹出新的窗口,需要切换到不同的窗口进行操作
基本步骤:
- 步骤一:获得当前窗口句柄
h1=driver.current_window_handle
- 步骤二:获得当前所有打开窗口的句柄
all_handles=driver.window_handles
- 步骤三:切换到指定句柄窗口
driver.switch_to.window(h1)
eg:



七、unittest单元测试框架
7.1 什么是单元测试
单元测试是对程序最小设计单元进行正确性检验的测试工作
单元测试的特点:
- 程序单元是应用的最小可测试部件(函数、类等)
- 被测程序单元和其他单元是相互独立的
- 单元测试执行速度比较快
- 单元测试发现的问题,相对容易定位
- 单元测试经常结合白盒测试方法(一般由开发来进行测试)
不用测试框架的单元测试弊端:
测试程序的写法没有一定的规范可以遵循,这样不统一的代码后期维护起来十分麻烦,需要编写大量的辅助(测试)代码才能完成单元测试
在Python语言中,主要的单元测试框架有:unittest、pytest、doctest、nose等
单元测试框架的主要作用:
- 提供用例的组织和执行
- 提供丰富的断言
- 提供丰富的日志
unittest框架,原名为PyUnit框架,是Python语言自带的单元测试框架,在Python2.1及其以后的版本中,将unittest作为一个标准模块放入Python开发包中
unittest是Python自带的单元测试框架,作为一个标准模块放入Python开发包中(使用时需要导入)
unittest模块中的TestCase类是一个核心的测试类,提供很多测试功能,如初始化、断言、清理等(使用时需要继承)
TestCase类提供setUp方法和tearDown方法完成测试环境初始化和清理工作(根据实际情况重写);提供各种断言方法判断实际结果和预期结果是否一致
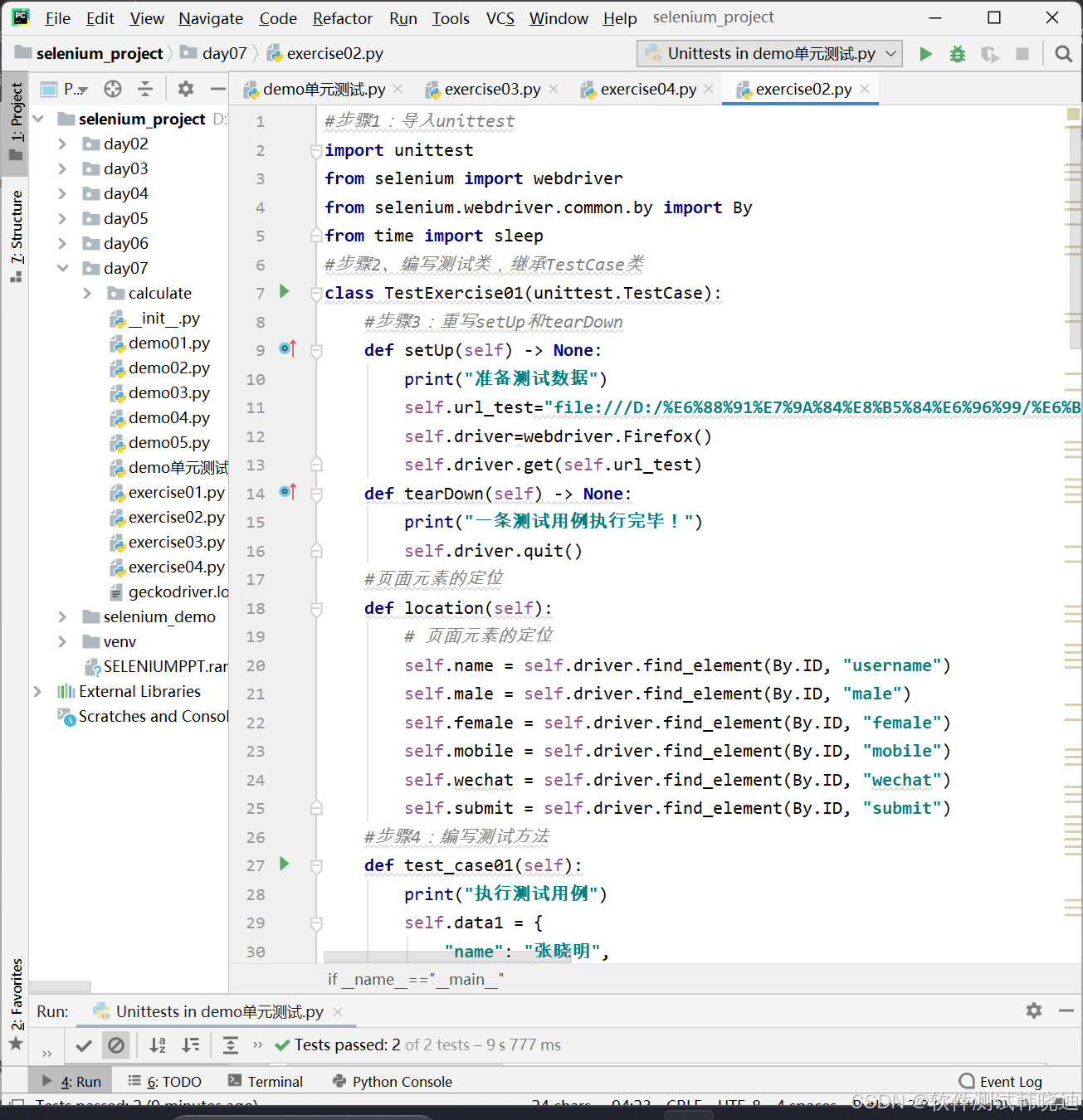
7.2 unittest单元测试框架测试步骤
步骤一:导入unittest模块
步骤二:编写测试类Textxxx,继承unittest模块中的TestCase类
步骤三:覆盖setUp搭建测试环境,覆盖tearDown撤销测试环境
步骤四:编写测试方法testxxx,测试被测方法(或函数)在setUp与 tearDown中间写
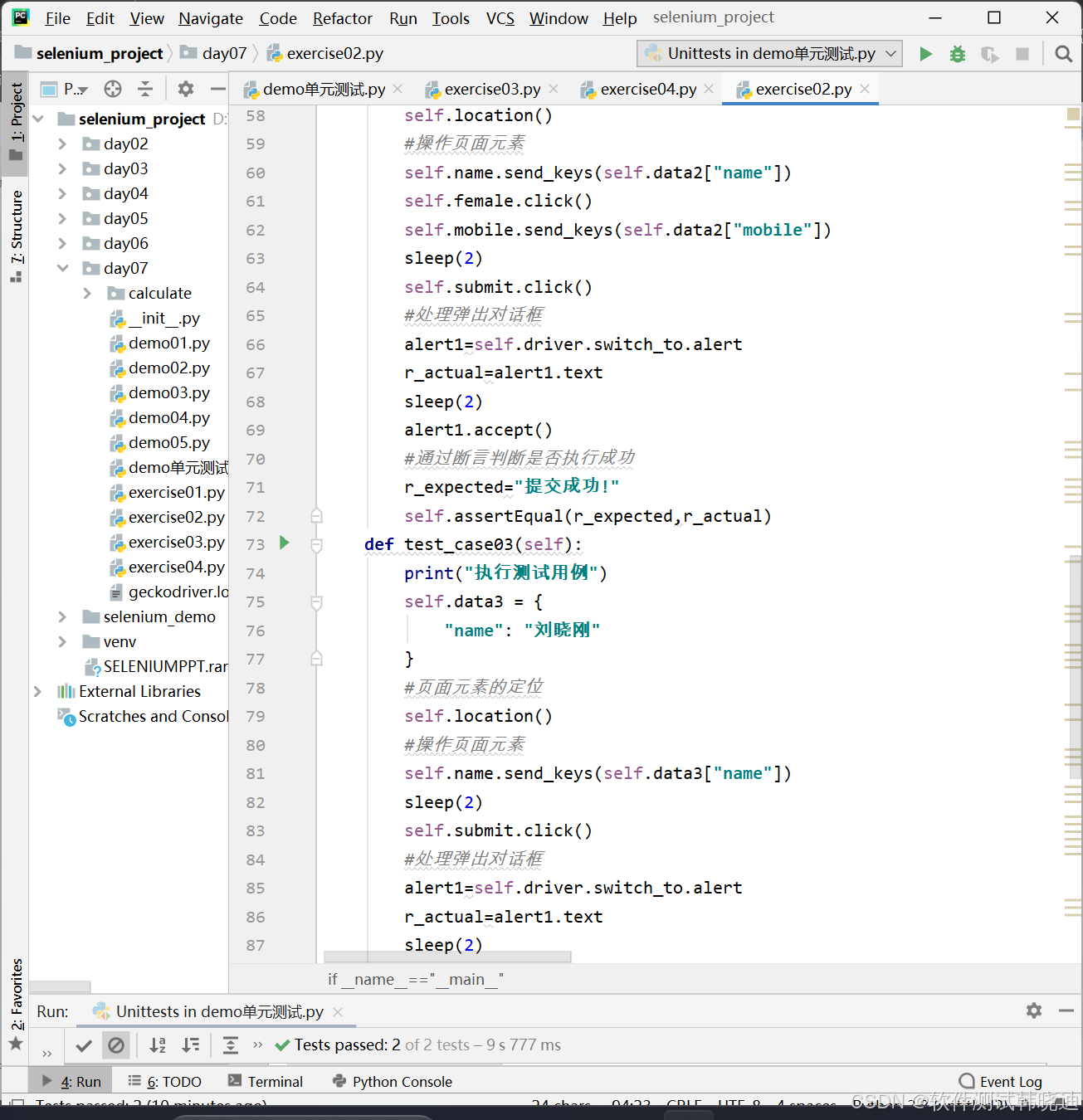
步骤五:执行测试方法(测试用例)
步骤四、编写测试方法testxxx,测试被测方法(或函数)
测试方法必须以test开头,以test开头的方法,会自动执行;xxx一般为被测试的方法名称
此方法主要包括的代码有:被测类的实例化、被测方法的调用,获得被测方法返回值,通过断言方法比较实际结果和预期结果是否相等


7.3 测试套件
TestSuite:测试套件(测试组件)
一个功能的验证往往需要多个测试用例(TestCase),把多个测试用例集合在一起执行,就是TestSuite。
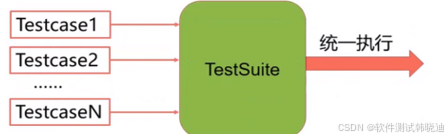
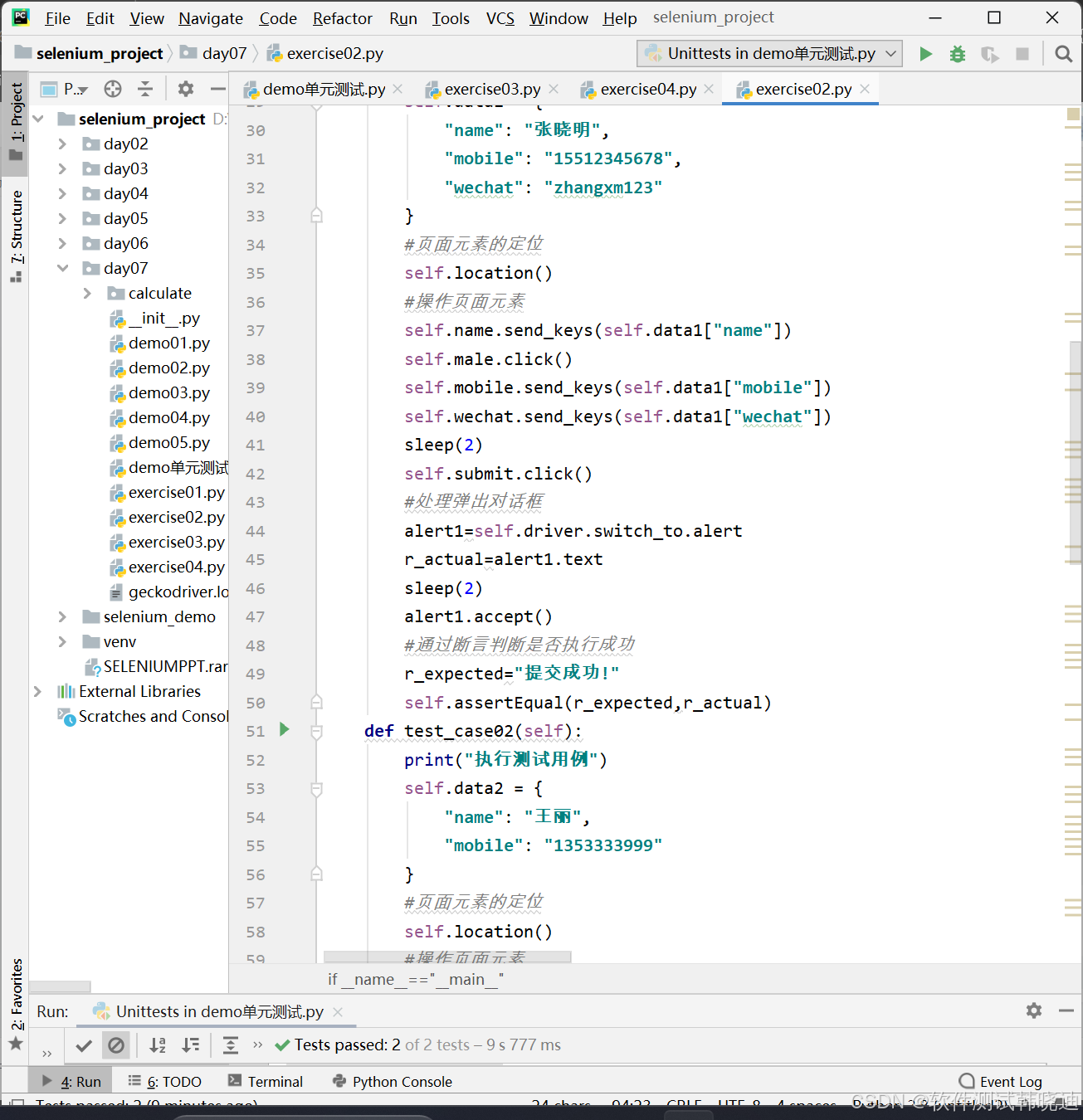
采用TestSuit,使用unittest单元测试框架基本步骤:
步骤1:导入unittest模块
步骤2:编写测试类Teatxxx,继承unittest模块中的TestCase类
步骤3:编写测试用例(setUp、tearDown、testxxx、断言)
- 需要编写多个测试方法
- 如何把这些测试方法添加到测试套件TestSuite中?
步骤4:执行全部测试方法(TestSuite)
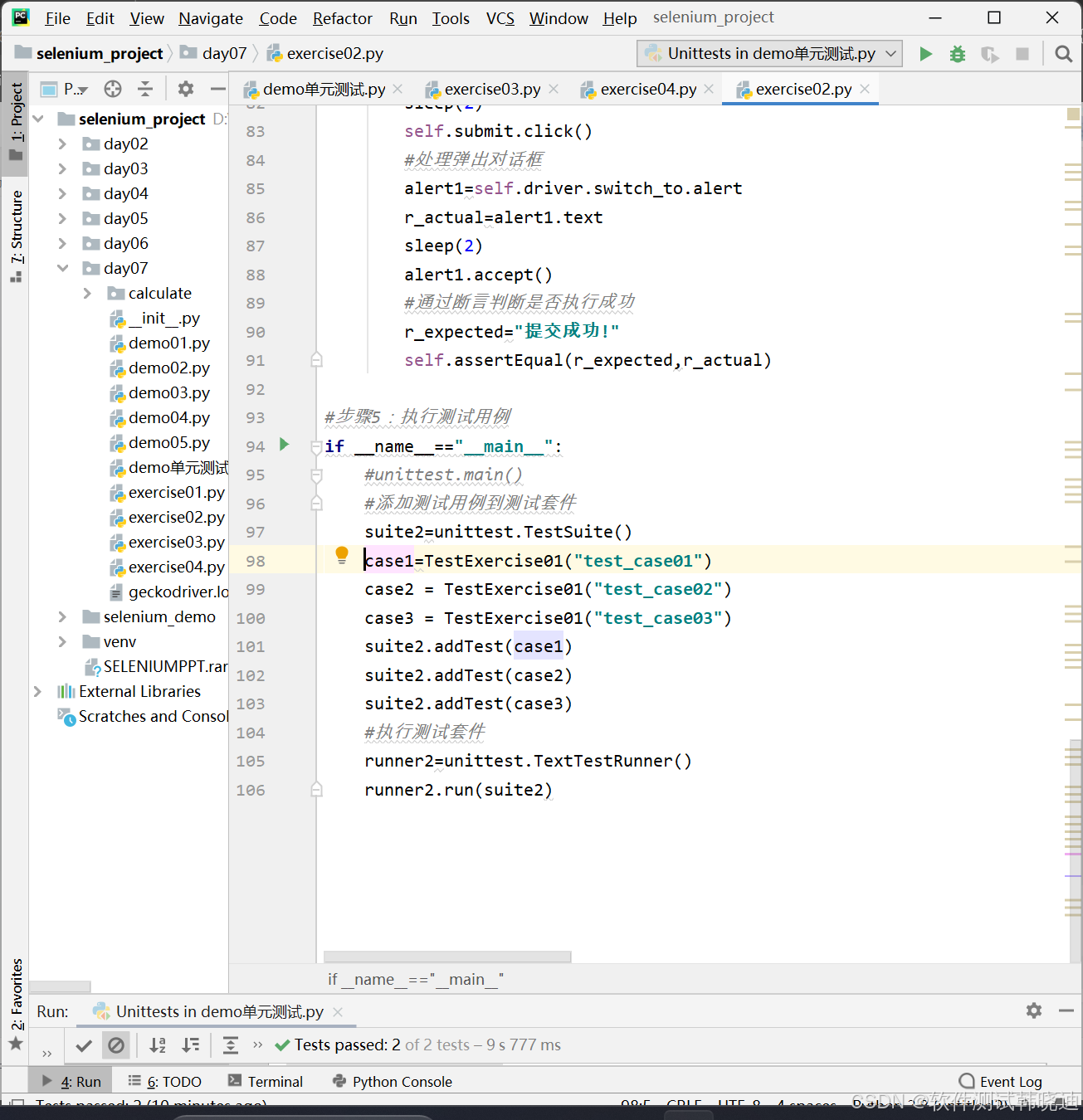
如何把这些测试方法添加到测试套件TestSuite中?
1.对TestSuite类进行实例化
suite=unittest.TestSuite()
2.对每一条测试用例进行实例化
case1=TestCount("test_add1")
case2=TestCount("test_add2")
3.调用TestSuite类中的addTest方法添加测试用例到测试套件
suite.addTest(case1)
suite.addTest(case2)
如何执行全部测试方法(测试用例)?
1.对TextTestRunner类进行实例化
2.调用TextTestRunner类中的run方法执行测试套件
runnner=unittest.TextTextRunner()
runner.run(suite)
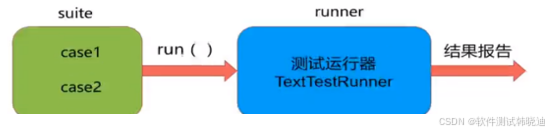
采用TestSuit,使用unittest单元测试框架基本步骤:
步骤1:导入unittest模块
步骤2:编写测试类Teatxxx,继承unittest模块中的TestCase类
步骤3:编写测试用例(setUp、tearDown、testxxx、断言)
步骤4:把这些测试方法添加到TestSuit中
步骤5:执行TestSuite
7.4 测试固件
TestFixture:
测试固件:
一个或多个测试执行前的准备工作(setUp)和测试结束后的清理动作(tearDown),测试用例环境搭建和销毁,称为测试固件(TestFixture)
unuttest提供的三种主要测试固件:
- setUp和tearDown
- setUpClass和tearDownClass
- setUpMoudule和tearDownModule
setUp和tearDown方法:
用于一条测试用例环境搭建和销毁
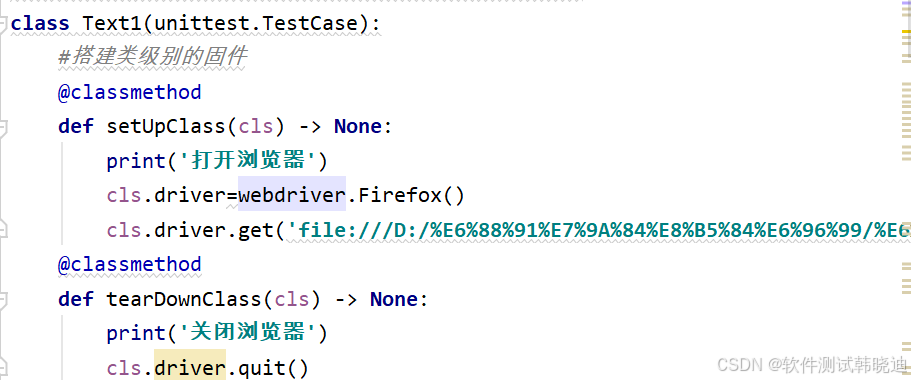
setUpClass和tearDownClass方法:
(全程只调用一次)必须使用@classmethod 装饰器
setUpClass:
搭建一个测试类的环境,是一个测试类中所有测试方法共享的环境
第一条测试用例的setUp方法之前执行,整个测试过程只执行一次
必须使用@Classmethod装饰器进行修饰
tearDownClass
销毁一个测类的环境
最后一条测试用例的tearDown方法之后执行,整个测试过程只执行一次
必须使用@classmethod装饰器进行修饰
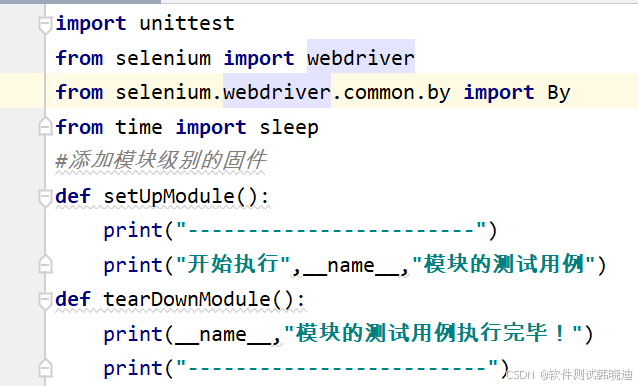
setUpMoudle和tearDownMoudle方法:
模块级别指的是文件级别。Python 中文件即模块,所以你可以理解为每个文件只运行一次 ,不管你的这个测试文件中有多少的测试类和测试方法。
标签:
相关文章
最新发布
- 光流法结合深度学习神经网络的原理及应用(完整代码都有Python opencv)
- Python 图像处理进阶:特征提取与图像分类
- 大数据可视化分析-基于python的电影数据分析及可视化系统_9532dr50
- 【Python】入门(运算、输出、数据类型)
- 【Python】第一弹---解锁编程新世界:深入理解计算机基础与Python入门指南
- 华为OD机试E卷 --第k个排列 --24年OD统一考试(Java & JS & Python & C & C++)
- Python已安装包在import时报错未找到的解决方法
- 【Python】自动化神器PyAutoGUI —告别手动操作,一键模拟鼠标键盘,玩转微信及各种软件自动化
- Pycharm连接SQL Sever(详细教程)
- Python编程练习题及解析(49题)
点击排行
- 版本匹配指南:Numpy版本和Python版本的对应关系
- 版本匹配指南:PyTorch版本、torchvision 版本和Python版本的对应关系
- Python 可视化 web 神器:streamlit、Gradio、dash、nicegui;低代码 Python Web 框架:PyWebIO
- 相关性分析——Pearson相关系数+热力图(附data和Python完整代码)
- Anaconda版本和Python版本对应关系(持续更新...)
- Python与PyTorch的版本对应
- Windows上安装 Python 环境并配置环境变量 (超详细教程)
- Python pyinstaller打包exe最完整教程
本站推荐
