首页 > Python资料 博客日记
全网最适合入门的面向对象编程教程:55 Python字符串与序列化-字节序列类型和可变字节字符串
2024-10-03 01:00:03Python资料围观86次
全网最适合入门的面向对象编程教程:55 Python 字符串与序列化-字节序列类型和可变字节字符串
摘要:
在 Python 中,字符编码是将字符映射为字节的过程,而字节序列(bytes)则是存储这些字节的实际数据结构,字节序列和可变字节字符串的主要区别在于其可变性和用途,bytearray 是可变的字节序列,允许修改其内容。
原文链接:
往期推荐:
全网最适合入门的面向对象编程教程:00 面向对象设计方法导论
全网最适合入门的面向对象编程教程:01 面向对象编程的基本概念
全网最适合入门的面向对象编程教程:02 类和对象的 Python 实现-使用 Python 创建类
全网最适合入门的面向对象编程教程:03 类和对象的 Python 实现-为自定义类添加属性
全网最适合入门的面向对象编程教程:04 类和对象的Python实现-为自定义类添加方法
全网最适合入门的面向对象编程教程:05 类和对象的Python实现-PyCharm代码标签
全网最适合入门的面向对象编程教程:06 类和对象的Python实现-自定义类的数据封装
全网最适合入门的面向对象编程教程:07 类和对象的Python实现-类型注解
全网最适合入门的面向对象编程教程:08 类和对象的Python实现-@property装饰器
全网最适合入门的面向对象编程教程:09 类和对象的Python实现-类之间的关系
全网最适合入门的面向对象编程教程:10 类和对象的Python实现-类的继承和里氏替换原则
全网最适合入门的面向对象编程教程:11 类和对象的Python实现-子类调用父类方法
全网最适合入门的面向对象编程教程:12 类和对象的Python实现-Python使用logging模块输出程序运行日志
全网最适合入门的面向对象编程教程:13 类和对象的Python实现-可视化阅读代码神器Sourcetrail的安装使用
全网最适合入门的面向对象编程教程:全网最适合入门的面向对象编程教程:14 类和对象的Python实现-类的静态方法和类方法
全网最适合入门的面向对象编程教程:15 类和对象的 Python 实现-__slots__魔法方法
全网最适合入门的面向对象编程教程:16 类和对象的Python实现-多态、方法重写与开闭原则
全网最适合入门的面向对象编程教程:17 类和对象的Python实现-鸭子类型与“file-like object“
全网最适合入门的面向对象编程教程:18 类和对象的Python实现-多重继承与PyQtGraph串口数据绘制曲线图
全网最适合入门的面向对象编程教程:19 类和对象的 Python 实现-使用 PyCharm 自动生成文件注释和函数注释
全网最适合入门的面向对象编程教程:20 类和对象的Python实现-组合关系的实现与CSV文件保存
全网最适合入门的面向对象编程教程:21 类和对象的Python实现-多文件的组织:模块module和包package
全网最适合入门的面向对象编程教程:22 类和对象的Python实现-异常和语法错误
全网最适合入门的面向对象编程教程:23 类和对象的Python实现-抛出异常
全网最适合入门的面向对象编程教程:24 类和对象的Python实现-异常的捕获与处理
全网最适合入门的面向对象编程教程:25 类和对象的Python实现-Python判断输入数据类型
全网最适合入门的面向对象编程教程:26 类和对象的Python实现-上下文管理器和with语句
全网最适合入门的面向对象编程教程:27 类和对象的Python实现-Python中异常层级与自定义异常类的实现
全网最适合入门的面向对象编程教程:28 类和对象的Python实现-Python编程原则、哲学和规范大汇总
全网最适合入门的面向对象编程教程:29 类和对象的Python实现-断言与防御性编程和help函数的使用
全网最适合入门的面向对象编程教程:30 Python的内置数据类型-object根类
全网最适合入门的面向对象编程教程:31 Python的内置数据类型-对象Object和类型Type
全网最适合入门的面向对象编程教程:32 Python的内置数据类型-类Class和实例Instance
全网最适合入门的面向对象编程教程:33 Python的内置数据类型-对象Object和类型Type的关系
全网最适合入门的面向对象编程教程:34 Python的内置数据类型-Python常用复合数据类型:元组和命名元组
全网最适合入门的面向对象编程教程:35 Python的内置数据类型-文档字符串和__doc__属性
全网最适合入门的面向对象编程教程:36 Python的内置数据类型-字典
全网最适合入门的面向对象编程教程:37 Python常用复合数据类型-列表和列表推导式
全网最适合入门的面向对象编程教程:38 Python常用复合数据类型-使用列表实现堆栈、队列和双端队列
全网最适合入门的面向对象编程教程:39 Python常用复合数据类型-集合
全网最适合入门的面向对象编程教程:40 Python常用复合数据类型-枚举和enum模块的使用
全网最适合入门的面向对象编程教程:41 Python常用复合数据类型-队列(FIFO、LIFO、优先级队列、双端队列和环形队列)
全网最适合入门的面向对象编程教程:42 Python常用复合数据类型-collections容器数据类型
全网最适合入门的面向对象编程教程:43 Python常用复合数据类型-扩展内置数据类型
全网最适合入门的面向对象编程教程:44 Python内置函数与魔法方法-重写内置类型的魔法方法
全网最适合入门的面向对象编程教程:45 Python实现常见数据结构-链表、树、哈希表、图和堆
全网最适合入门的面向对象编程教程:46 Python函数方法与接口-函数与事件驱动框架
全网最适合入门的面向对象编程教程:47 Python函数方法与接口-回调函数Callback
全网最适合入门的面向对象编程教程:48 Python函数方法与接口-位置参数、默认参数、可变参数和关键字参数
全网最适合入门的面向对象编程教程:49 Python函数方法与接口-函数与方法的区别和lamda匿名函数
全网最适合入门的面向对象编程教程:50 Python函数方法与接口-接口和抽象基类
全网最适合入门的面向对象编程教程:51 Python函数方法与接口-使用Zope实现接口
全网最适合入门的面向对象编程教程:52 Python函数方法与接口-Protocol协议与接口
全网最适合入门的面向对象编程教程:53 Python字符串与序列化-字符串与字符编码
全网最适合入门的面向对象编程教程:54 Python字符串与序列化-字符串格式化与format方法
更多精彩内容可看:
给你的 Python 加加速:一文速通 Python 并行计算
一个MicroPython的开源项目集锦:awesome-micropython,包含各个方面的Micropython工具库
SenseCraft 部署模型到Grove Vision AI V2图像处理模块
文档和代码获取:
可访问如下链接进行对文档下载:
https://github.com/leezisheng/Doc

本文档主要介绍如何使用 Python 进行面向对象编程,需要读者对 Python 语法和单片机开发具有基本了解。相比其他讲解 Python 面向对象编程的博客或书籍而言,本文档更加详细、侧重于嵌入式上位机应用,以上位机和下位机的常见串口数据收发、数据处理、动态图绘制等为应用实例,同时使用 Sourcetrail 代码软件对代码进行可视化阅读便于读者理解。
相关示例代码获取链接如下:https://github.com/leezisheng/Python-OOP-Demo
正文
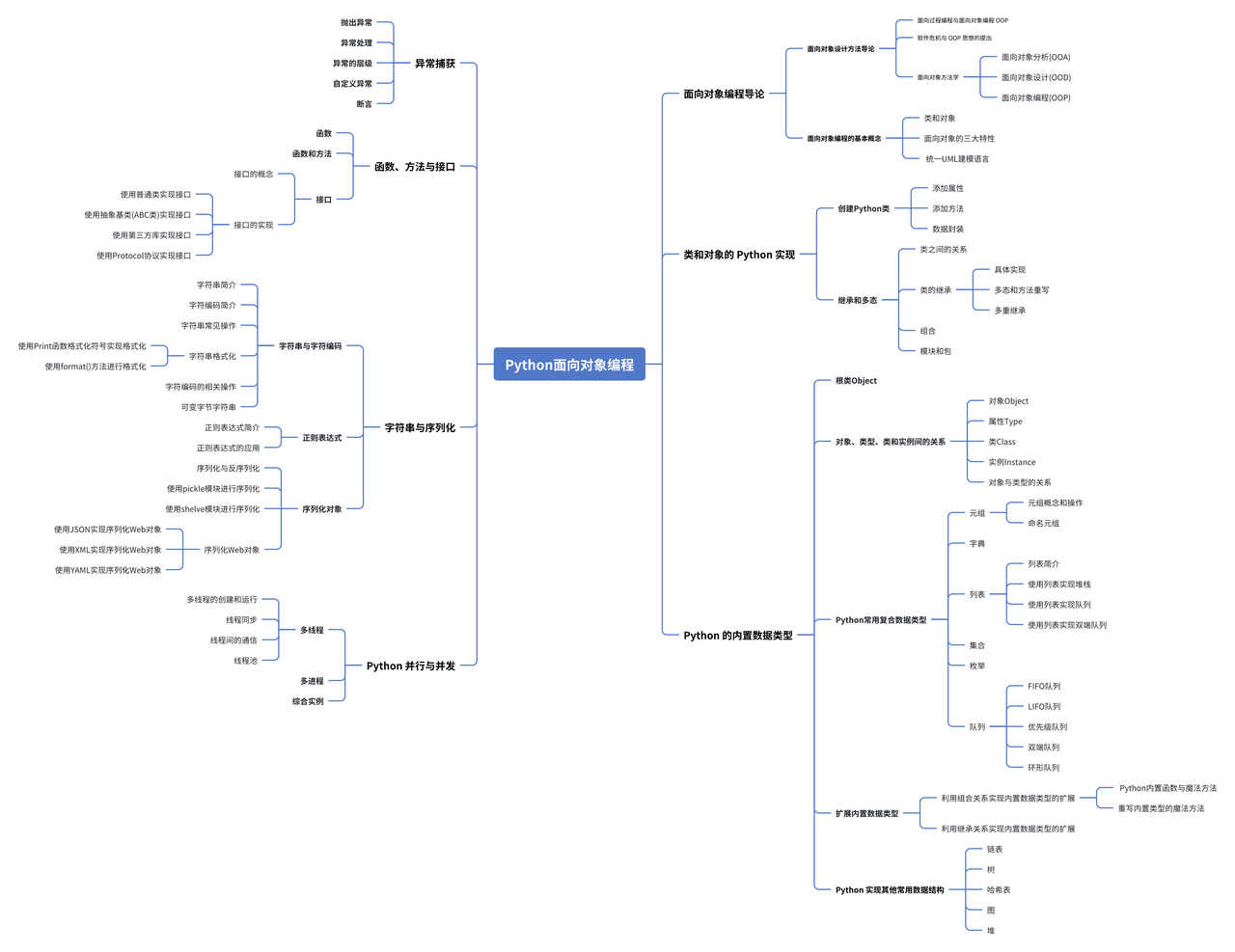
字符编码和字节序列 bytes
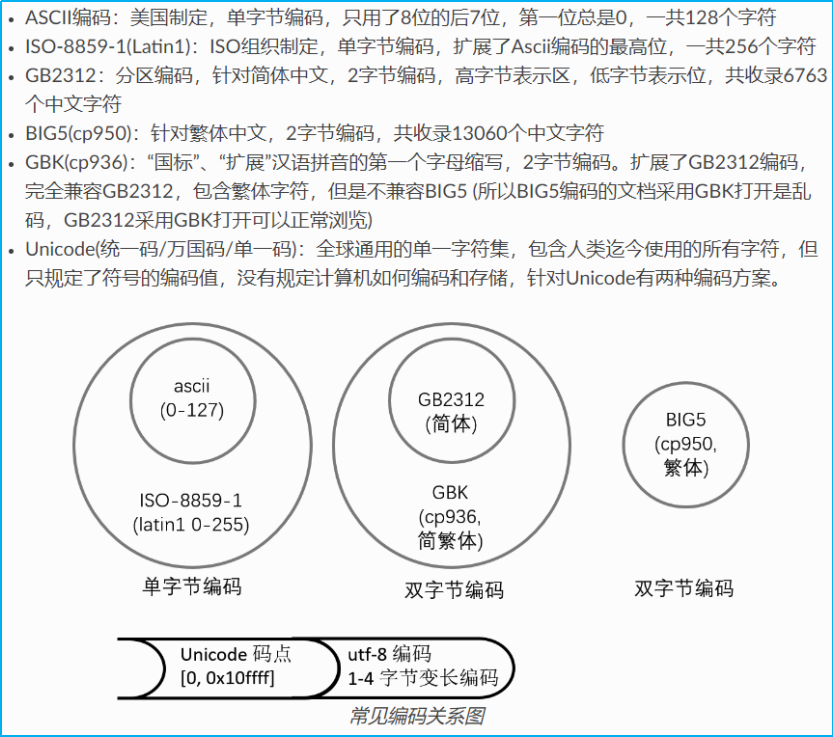
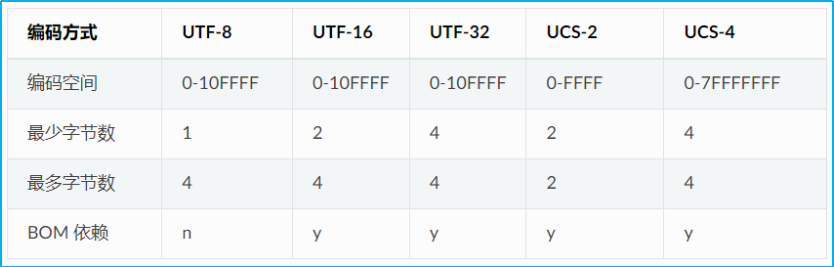
在计算机内存中,我们遵循标准化的编码原则,普遍采用 Unicode 编码体系。然而,当需要将数据持久化保存至硬盘或进行网络传输时,我们则将其转换为 UTF-8 编码。举例来说,当我们使用记事本进行文档编辑时,从文件中读取的 UTF-8 字符将被转换为 Unicode 字符以适应内存处理。编辑工作完成后,系统再将这些 Unicode 字符转换回 UTF-8 编码,以确保文件保存的准确性和兼容性。这一流程确保了数据在不同平台和系统间的顺畅交流,满足了现代计算环境中对于数据编码的多样化需求。

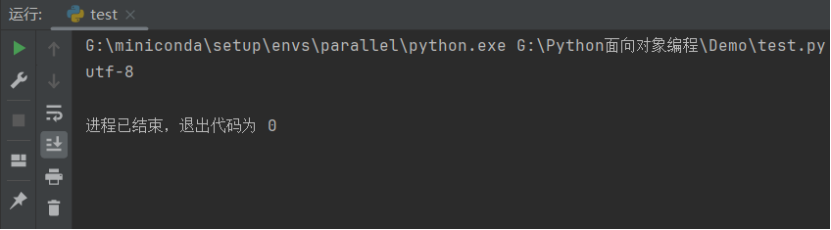
我们可以通过如下代码获取我们自己计算机默认的编码方式:
import sys
print(sys.getdefaultencoding())
我们来看一下运行结果,显示系统默认 UTF-8 编码:
Python3 中明确区分字符串类型 (str) 和字节序列类型 (bytes),也称为字节流。内存,磁盘中均是以字节流的形式保存数据,它由一个一个的字节(byte,8bit)顺序构成。在前文中,我们提到字节是计算过程中最底层的存储格式,所以字符串实际上为内置的 bytes 类型。然而人们并不习惯直接使用字节,既读不懂,操作起来也很麻烦,人们容易看懂的是字符串。所以字符串和字节流需要进行转化,字节流转换为人们可以读懂的过程叫做解码,与此相反,将字符串转换为字节流的过程叫做编码。在下面的示例中,我们先声明了一个 bytes 数组,然后用 bytes 类的.decode 方法将其转换为我们可以看得懂的 Unicode 字符串。这个方法接受不同字符编码方式作为参数,示例代码如下:
_# 表示 Latin-1 编码中的 cliché_
_# b 表示在定义一个 bytes 对象_
_# \x 字符表示每个字节用十六进制数字表示_
bytestr = b'\x63\x6c\x69\x63\x68\xe9'
_# 输出这些字节的 ASCII 符号本身_
_# 对于 ASCII 来说是未知的字符还是保留原有的十六进制格式_
_# 输出结果包含了 b 字符,提示我们这是一个bytes,而不是字符串_
print(bytestr)
_# 用 Latin-1 编码来解码字符串,decode 方法返回一个正常字符串_
print(bytestr.decode("latin-1"))
_# 使用 iso8859-5 编码来解码字符串_
print(bytestr.decode("iso8859-5"))
_# 使用 CP437 编码来解码字符串_
print(bytestr.decode("CP437"))
运行结果如下:

我们也可以使用 encode 将字符串转换为 bytes 数组,示例代码如下:
str = "cliché"
_# 前 3 个编码为重音字符创建了不同的字节集合_
print(str.encode("UTF-8"))
print(str.encode("latin-1"))
print(str.encode("CP437"))
_# 第 4 个则无法处理这种情况 ,有未知字符_
print(str.encode("ascii"))
运行结果如下:
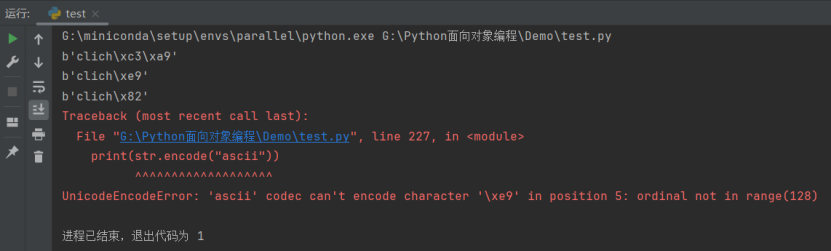
可以看到,最后一种情况抛出了异常,因为具有未知字符,有时候我们想要让那些未知字符以不同的方式进行处理。encode 方法还接受一个可选的字符串参数,名为 errors,用于定义这个字符应该如何处理。可选的值如下所示:
- strict:strict 替换规则是默认的,当字节序列在我们所用的编码中无法表示某个字符时,会抛出异常;
- replace:使用 replace 策略时,这个字符会用另外一个字符替换;
- ignore:ignore 策略会直接省去不认识的字符;
- xmlcharrefreplace:xmlcharrefreplace 策略创建一个 xml 实体表示 Unicode 字符,这样可以根据 XML 文档来转换字符串。
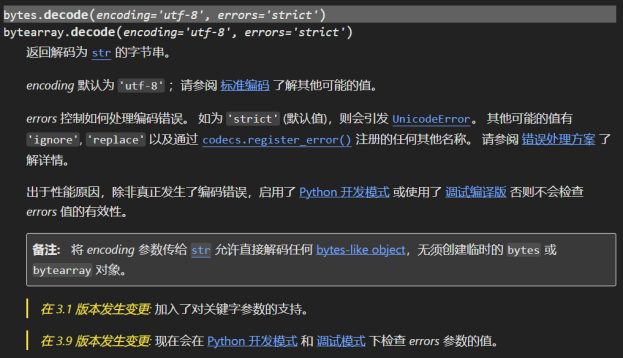
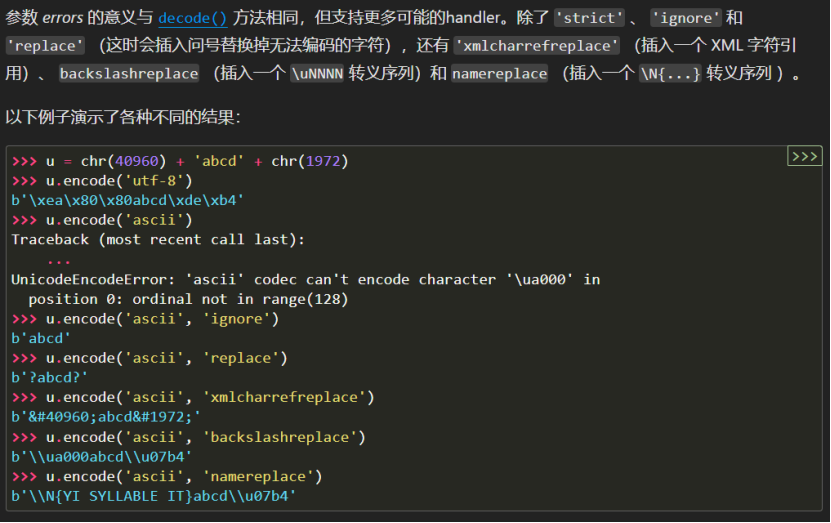
Python 有大约 100 种不同的编码格式,详情可以看如下链接:
https://docs.python.org/zh-cn/3/library/codecs.html#standard-encodings
一些编码格式有多个名称,比如'latin-1'、'iso_8859_1'和'8859’都是指同一种编码。在处理编码文件时,选择正确的编码至关重要。我强烈推荐使用 UTF-8 编码。UTF-8 不仅具备表示任何 Unicode 字符的能力,更在现代软件领域中已成为一种广泛接受的标准。
Python 源代码也是一个文本文件,所以,当你的源代码中包含中文的时候,在保存源代码时,就需要务必指定保存为 UTF-8 编码。当 Python 解释器读取源代码时,为了让它按 UTF-8 编码读取,我们通常在文件开头写上这两行:
_#!/usr/bin/env python3_
_# -*- coding: utf-8 -*-_
第一行注释是为了告诉 Linux/OS X 系统,这是一个 Python 可执行程序,Windows 系统会忽略这个注释;
第二行注释是为了告诉 Python 解释器,按照 UTF-8 编码读取源代码,否则,你在源代码中写的中文输出可能会有乱码。
申明了 UTF-8 编码并不意味着你的.py 文件就是 UTF-8 编码的,必须并且要确保 IDE 正在使用 UTF-8 编码。以 PyCharm IDE 为例:
可变字节字符串 bytearray
bytes 类型与 str 类似,它们都是不可变的。这意味着一旦创建了一个 bytes 对象,我们就不能对其进行扩展或修改。尽管如此,我们仍然可以对 bytes 对象执行索引或切片操作,甚至搜索特定的字节序列。然而,在处理 I/O 操作时,这种不可变性可能会带来一些不便。因为在进行输入/输出操作时,我们经常需要缓存字节,直到它们准备好被发送。
例如,当从套接字接收数据时,可能需要多次调用 recv 函数才能接收完整的消息。在这种情况下,我们可以使用内置的 bytearray 类型来解决这个问题。bytearray 的行为类似于列表,但它包含的元素是字节。它的构造函数可以接受 bytes 对象作为参数进行初始化。此外,bytearray 还提供了 extend 方法,允许我们向数组中添加更多的 bytes 对象,例如在从套接字或其他 I/O 通道接收到更多数据时,这种灵活性使得 bytearray 在处理需要动态修改字节序列的场景中非常有用。
bytearray 用法如下:
Syntax: bytearray(source, encoding, errors)
Parameters:
-source[optional]: Initializes the array of bytes
-encoding[optional]: Encoding of the string
-errors[optional]: Takes action when encoding fails
Returns:
Returns an array of bytes of the given size.
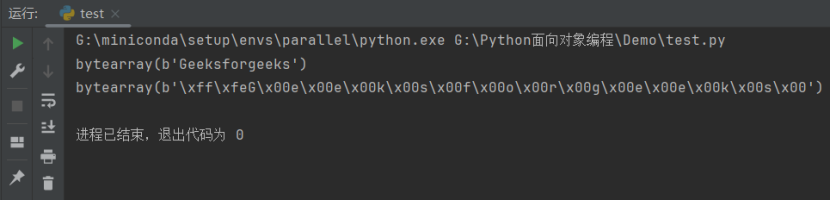
在下面的示例中,我们创建了两个 bytearray 数组,并使用 bytearray() 函数对字符串进行编码:
str = "Geeksforgeeks"
_# encoding the string with unicode 8 and 16_
array1 = bytearray(str, 'utf-8')
array2 = bytearray(str, 'utf-16')
print(array1)
print(array2)
代码输出如下:
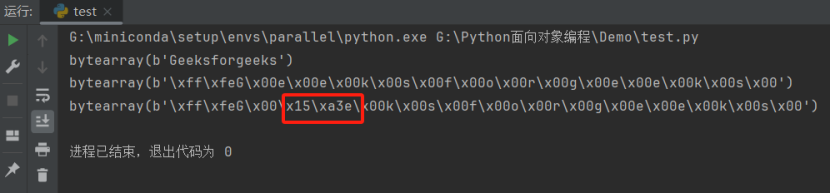
我们也可以通过切片操作直接修改 bytearray:
array2[4:6] = b"\x15\xa3"
print(array2)
运行结果如下:
需要注意的是,如果我们想要操作 bytearray 中的单个元素,则需要传入一个 0~255 的整数值。这个整数代表的是一个特定的 bytes。如果我们用字符或 bytes 对象,将会抛出异常。
单字节字符可以通过 ord 函数(ordinal 的简写)转换成整数。这一函数返回表示一个单独字符的整数。示例代码如下:
b = bytearray(b'abcdef')
b[3] = ord(b'g')
b[4] = 68
print(b)
运行结果如下:
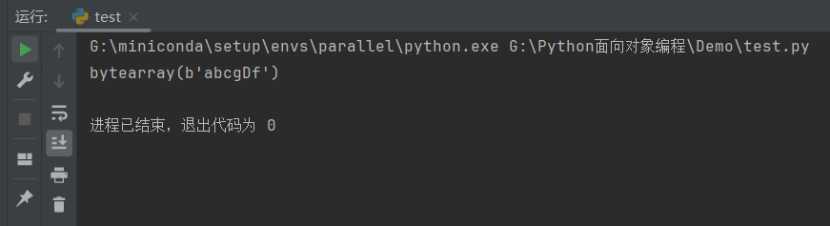
这里,我们在构造完成可变字节字符串后,将索引为 3 的字符(第 4 个字符,因为和列表一样,索引是从 0 开始的)替换为 103。它是通过 ord 函数返回的 ASCII 字符中的小写字母 g 所对应的数字。作为说明,我们也将下一个字符替换为字节数字 68,它对应 ASCII 字符中的大写字母 D。
bytearray 类型的一些方法让它可以像列表一样操作,我们也可以对其进行遍历、求其长度、使用 count 和 find 等方法,就像是对 bytes 或 str 对象一样。不同之处在于 bytearray 是可变类型,它可以用于从特定输入源构建复杂序列。
_# 创建bytearray_
array = bytearray(b"acbcdc")
_# 遍历_
for value in array:
print(value)
_# 对元素b'c'使用count方法_
print("Count of c is:", array.count(b"c"))
_# 对元素b'c'使用find方法_
print("Count of c is:", array.find(b"c"))
_# 对元素b'c'使用len方法_
print("Count of bytes:", len(array))

标签:
相关文章
最新发布
- 光流法结合深度学习神经网络的原理及应用(完整代码都有Python opencv)
- Python 图像处理进阶:特征提取与图像分类
- 大数据可视化分析-基于python的电影数据分析及可视化系统_9532dr50
- 【Python】入门(运算、输出、数据类型)
- 【Python】第一弹---解锁编程新世界:深入理解计算机基础与Python入门指南
- 华为OD机试E卷 --第k个排列 --24年OD统一考试(Java & JS & Python & C & C++)
- Python已安装包在import时报错未找到的解决方法
- 【Python】自动化神器PyAutoGUI —告别手动操作,一键模拟鼠标键盘,玩转微信及各种软件自动化
- Pycharm连接SQL Sever(详细教程)
- Python编程练习题及解析(49题)
点击排行
- 版本匹配指南:Numpy版本和Python版本的对应关系
- 版本匹配指南:PyTorch版本、torchvision 版本和Python版本的对应关系
- Python 可视化 web 神器:streamlit、Gradio、dash、nicegui;低代码 Python Web 框架:PyWebIO
- 相关性分析——Pearson相关系数+热力图(附data和Python完整代码)
- Anaconda版本和Python版本对应关系(持续更新...)
- Python与PyTorch的版本对应
- Windows上安装 Python 环境并配置环境变量 (超详细教程)
- Python pyinstaller打包exe最完整教程
本站推荐
