首页 > Python资料 博客日记
我去图书馆微信公众号抢座【Python版本】
2024-02-29 22:00:06Python资料围观230次
更新记录
- 介于大部分是小白这里就重新整理一下思路 直接跳第十次更新!
- 第一次更新 抓包抢座
- 2023-4-28日第二次更新(更新了指定时间抢座 加了时间戳)
- 2023-5-9日第三次更新(更新了延迟时间 测试成功案例)
- 2023-5-31日第四次更新(关于程序中url的抓取)
- 2023-6-1日第五次更新(关于评论区有同学出现的bug(远程已帮忙解决))
- 2023-6-30日第六次更新(更新了大家心心念念的明日预约功能)
- 2023-7-1日第七次更新(更新了免抓包获取cookie 灵感来自B站和Github两位大佬)
- 2023-7-10日第八次更新(添加了异常捕获 避免报异常之后无法继续运行)
- 2023-9-10日第九次更新(更新大家反馈的座位信息如何抓取的方法)
- 2023-9-16日第十次更新(完整代码+抓包步骤整理)
- bug反馈区,持续更新...
介于大部分是小白这里就重新整理一下思路 直接跳第十次更新!
第一次更新 抓包抢座
先来个效果图(利益相关先全码上了 )
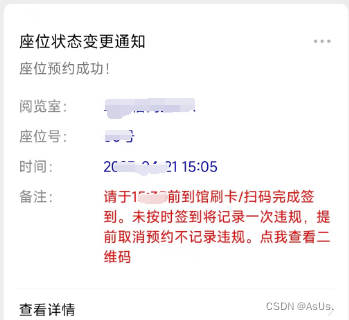
因为我们学校前一阵已经把系统部署到学校服务器了,所以这里就不放地址了,简单讲下思路。
写在前面:
①代码很简单 就一个request请求 后面作者本人还会继续优化 先讲一下我的需求:
<1> 实现全自动抢座,每天开馆的时候定时开抢
<2> 速度比人快,达到馆开座到的效果 所以后期这里应该会优化 因为本博客只提交了一次request请求,也没有加时间戳什么的 这个很好实现 大家自由发挥
②过程中肯定避免不了多次请求 所以为了避免反爬封ip所以后期一定要加上代理池之类的(但是如果老师真想搞你 肯定会有你信息的 所以大家还是慢点冲吧)这个可与先不考虑,此程序不会导致这种情况
思路:
①运用了Python的request库去提交get/post请求 具体是用get还是post需要大家自己去抓包分析
②抓包软件我用的是Fiddler
③我们需要手机连接到Fiddler 然后手动去预约一次拿到post的参数 比如header data cookie等等 (第二次更新可以不用去抓手机PC端微信可以解决!)
最后就是撸代码 去提交post请求
坑:
1.最好还是用抓手机的请求去获取cookie,我用pc端的微信去预约结果报语法错误? 也可能哪里没弄好 后来手机端cookie可以了也就没去再测试pc端的 大家自测吧 后期如果我测试了会补上 (第二次更新解决 PC端是可以的)
2.看好get/post请求 以及传送的data是json还是其他格式
3.暴力请求就要加代理池了 被封了就不好了。。。。
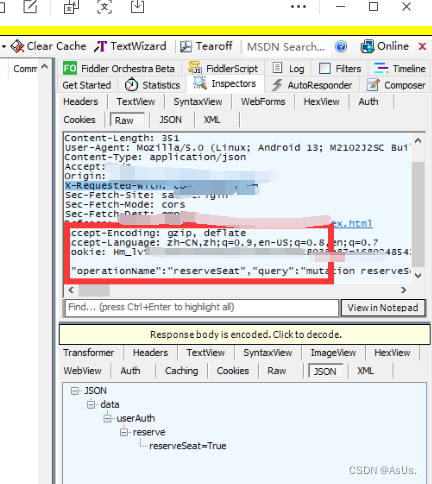
上代码(具体大家去根据自己情况抓包分析,每个系统都是不一样的 这里只讲了思路)
import json
import time
import requests
header = {
'Host': 'xxxx',
'Connection': 'keep-alive',
'Content-Length': '',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36 NetType/WIFI MicroMessenger/7.0.20.1781(0x6700143B) WindowsWechat(0x6309001c) XWEB/6763',
'Content-Type': '',
'Accept': '*/*',
'X-Requested-With': '',
'Origin': '',
'Sec-Fetch-Site': '',
'Sec-Fetch-Mode': '',
'Sec-Fetch-Dest': '',
'Referer': '',
'Accept-Encoding': '',
'Accept-Language': 'zh-CN,zh',
'Cookie': 'xxxx'
}
url = 'xxxx'
data = \
{"operationName": "reserveSeat",
"query": "mutation reserveSeat($libId: Int!, $seatKey: String!, $captchaCode: String, $captcha: String!) {\n userAuth {\n reserve {\n reserveSeat(\n libId: $libId\n seatKey: $seatKey\n captchaCode: $captchaCode\n captcha: $captcha\n )\n }\n }\n}",
"variables": {"seatKey": "35,18", "libId": 525, "captchaCode": "", "captcha": ""}}
res = requests.post(url=url, headers=header, json=data)
tm = res.elapsed.total_seconds()# 获取请求时间
print(tm)
print(res.status_code)
print(res.text)
2023-4-28日第二次更新(更新了指定时间抢座 加了时间戳)
本次更新了 程序可以对指定时间精确到秒来进行抢座
经过测试 pc端微信进入公众号进行抓取获取到的cookie是有效的 这样就省去了再用手机端进行抓取的繁琐步骤 爽✌
# -----------------------------正题--------------------------------
struct_openTime = "2023-4-28 17:20:00"
openTime = time.strptime(struct_openTime, "%Y-%m-%d %H:%M:%S")
openTime = time.mktime(openTime)
request_cnt = 0
while True:
# nowTime = int(time.mktime(time.localtime()))
print(time.time(), openTime)
if time.time() >= openTime:
# print(nowTime, openTime,time.time())
print("------------------------------")
print(time.time(), openTime)
print("ok Try to grab seat!")
grab_time = time.localtime(time.time())
ts = time.strftime("%Y-%m-%d %H:%M:%S", grab_time)
print('当前时间是: ' + ts)
request_cnt += 1
res = requests.post(url=url, headers=header, json=data3)
tm = res.elapsed.total_seconds()
print(tm)
print(res.status_code)
print(res.text)
# break
if str(res.text).count("true"):
print("恭喜你!抢座成功!程序即将结束......")
break
else:
time.sleep(0.2)
print("------------------------------\n\n")
if request_cnt >= 5: # 防止请求过多 被老师XX 所以这里我只敢 “最多” 请求5次
break # 另一个作用是避免图书馆服务器有延迟 加上上面的sleep 延迟时间可以控制在 5*0.2s = 1s 内 而且避免了过多的请求(程序1秒内发送的请求是很可怕的数量)
print("程序结束成功!")
这个图是刚开始测试截的图 后面完整程序没截图 不过程序是可以用的 图后期补上吧 如果有时间
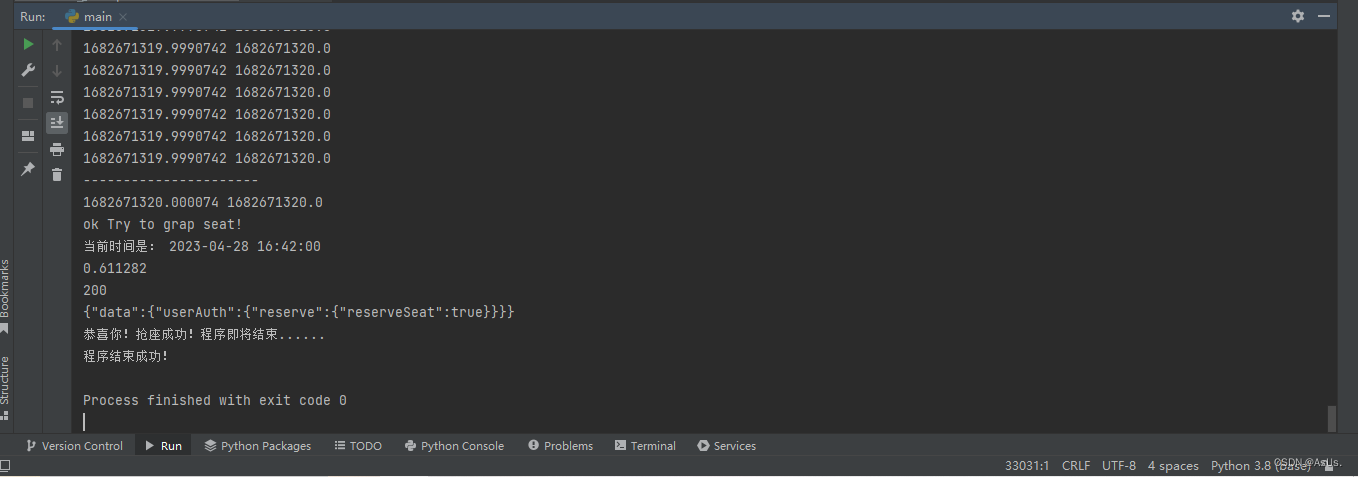
2023-5-9日第三次更新(更新了延迟时间 测试成功案例)
这次就说一下实战中遇见的问题和如何解决的
写好程序去实战的时候发现 我们学校服务器是有延迟的 之前设置的 sleep(0.2) * 5 = 1s是达不到要求的,所我就修改成了sleep(0.3) * 10 = 3s 来进行抓取,结果很丝滑,大家实战的时候可以按自己学校服务器放缩。另外今天也测试了一下人工手速和程序抢,结果基本被程序秒杀…
坑:
①注意cookie时效性,cookie会在一定时间内失效,需要自己去重新获取,这个我不知道多久失效一次(大约30分钟失效的样子),所以我每次抢座都会获取最新的cookie,好像发现计网有一块是讲这个的,等复习到再来更新一波吧…
②服务器延迟,大家多测试几次就行了,或者时间打长点,轻点c也是没问题的。
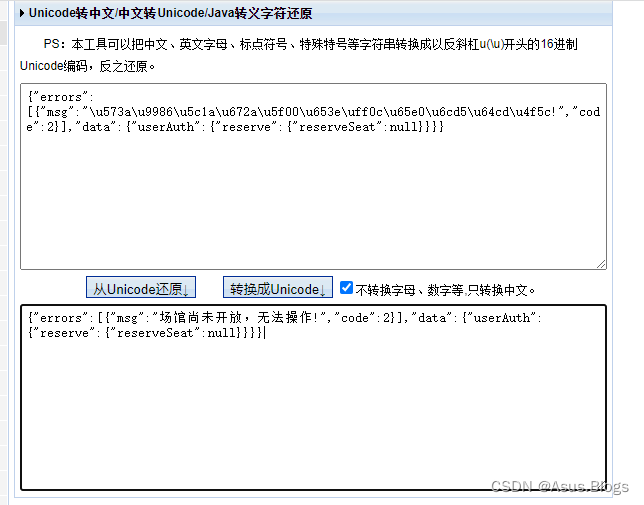
这里因为有延迟所以失败了一次,不过我设置的是请求10次,只要成功就会break掉程序,所以接下来的一次成功啦。到此也就结束了!
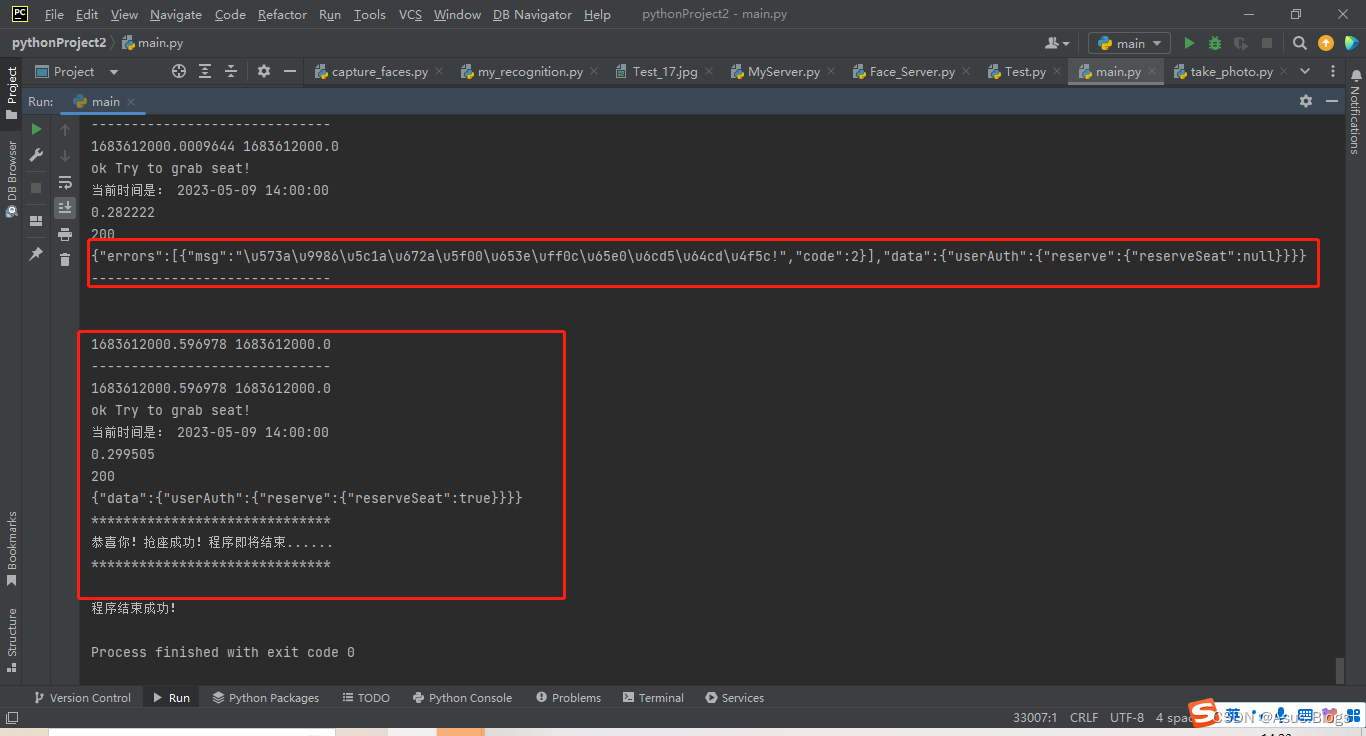
完整代码:
import json
import time
import requests
header = {
'Host': '',
'Connection': 'keep-alive',
'Content-Length': '353',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36 NetType/WIFI MicroMessenger/7.0.20.1781(0x6700143B) WindowsWechat(0x6309001c) XWEB/6763',
'Content-Type': 'application/json',
'Accept': '*/*',
'X-Requested-With': 'com.tencent.mm',
'Origin': '',
'Sec-Fetch-Site': 'same-origin',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Dest': 'empty',
'Referer': '',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh',
'Cookie': ''
}
url = ''
# 2楼 60号
data3 = \
{"operationName": "reserveSeat",
"query": "mutation reserveSeat($libId: Int!, $seatKey: String!, $captchaCode: String, $captcha: String!) {\n userAuth {\n reserve {\n reserveSeat(\n libId: $libId\n seatKey: $seatKey\n captchaCode: $captchaCode\n captcha: $captcha\n )\n }\n }\n}",
"variables": {"seatKey": "35,18", "libId": 525, "captchaCode": "", "captcha": ""}}
#
data = {"operationName": "reserveSeat",
"query": "mutation reserveSeat($libId: Int!, $seatKey: String!, $captchaCode: String, $captcha: String!) {\n userAuth {\n reserve {\n reserveSeat(\n libId: $libId\n seatKey: $seatKey\n captchaCode: $captchaCode\n captcha: $captcha\n )\n }\n }\n}",
"variables": {"seatKey": "**,**", "libId": ***, "captchaCode": "", "captcha": ""}}
# -----------------------------测试--------------------------------
# res = requests.post(url=lib_url2, headers=header, json=data3)
# tm = res.elapsed.total_seconds()
# print(tm)
# print(res.status_code)
# print(res.text)
# -----------------------------正题--------------------------------
struct_openTime = "2023-5-9 14:00:00"
openTime = time.strptime(struct_openTime, "%Y-%m-%d %H:%M:%S")
openTime = time.mktime(openTime)
request_cnt = 0
while True:
# nowTime = int(time.mktime(time.localtime()))
print(time.time(), openTime)
if time.time() >= openTime:
# print(nowTime, openTime,time.time())
print("------------------------------")
print(time.time(), openTime)
print("ok Try to grab seat!")
grab_time = time.localtime(time.time())
ts = time.strftime("%Y-%m-%d %H:%M:%S", grab_time)
print('当前时间是: ' + ts)
request_cnt += 1
res = requests.post(url=url, headers=header, json=data) # 此处data3 是2楼 60
tm = res.elapsed.total_seconds()
print(tm)
print(res.status_code)
print(res.text)
# break
if str(res.text).count("true"):
print("******************************")
print("恭喜你!抢座成功!程序即将结束......")
print("******************************\n")
break
else:
time.sleep(0.3)
print("------------------------------\n\n")
if request_cnt >= 10: # 防止请求过多 被老师XX 所以这里我只敢 “最多” 请求10次
break # 另一个作用是避免图书馆服务器有延迟 加上上面的sleep 延迟时间可以控制在 10*0.3s = 3s 内 而且避免了过多的请求(程序1秒内发送的请求是很可怕的数量)
print("程序结束成功!")
2023-5-31日第四次更新(关于程序中url的抓取)
首先打开我们的Fiddler和PC端微信 并在微信中打开图书馆公众号进行模拟选座
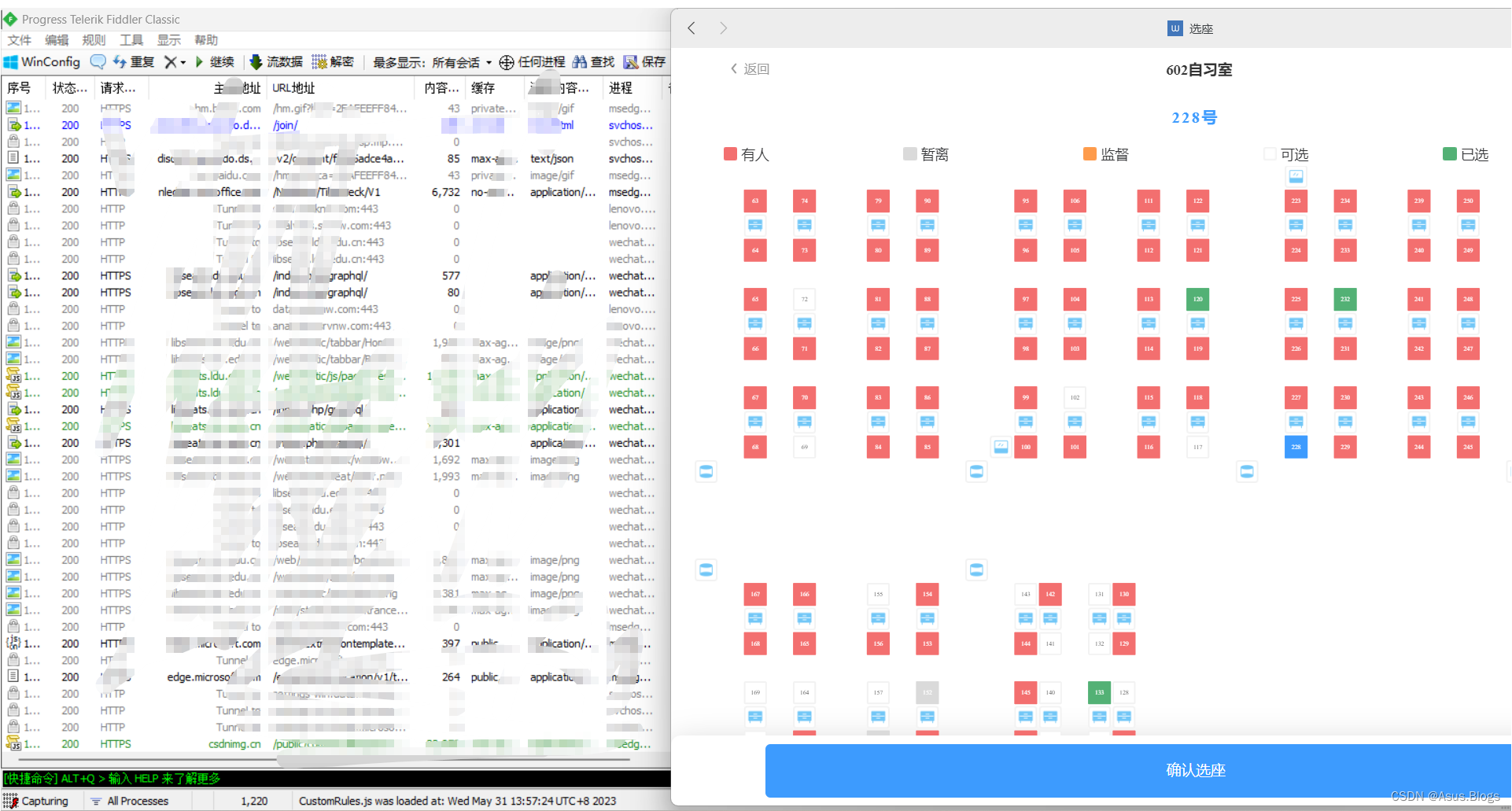

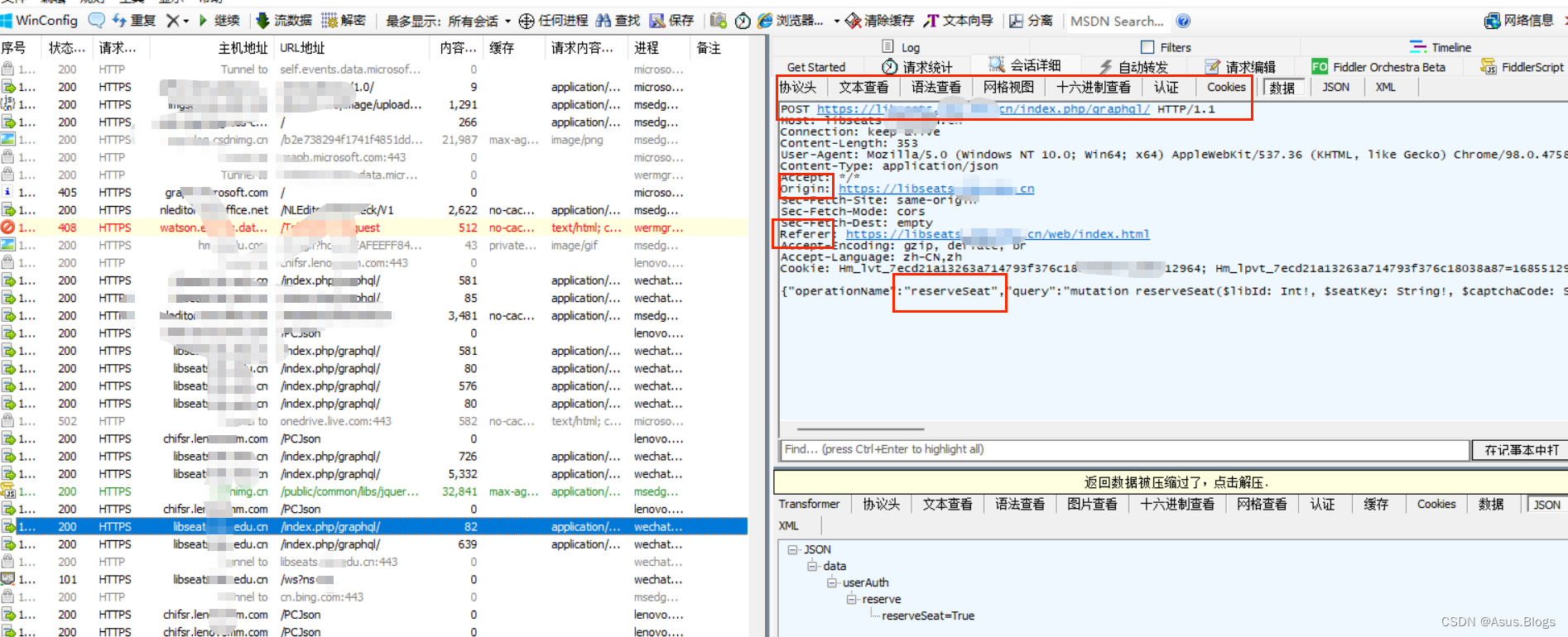
在Fiddler中就可以看到我们发出的选座请求以及各种header参数,而url就是POST后面那个冒蓝光的那个。
2023-6-1日第五次更新(关于评论区有同学出现的bug(远程已帮忙解决))
有同学在使用过程中返回了各种错误,在这里做一波更新
关于Access Denied 或者 其他

这个问题多半是cookie失效 或者 cookie填写不正确,大家在选cookie的时候可能出现各种格式的cookie,可能有很多参数行,我们只需要在fiddler中找到模拟请求的那个Http请求里的cookie就行了,注意 如果cookie有多个参数需要用分号隔开,不过在Raw里面fiddler已经给分好了,可以拿来直接用就行啦。
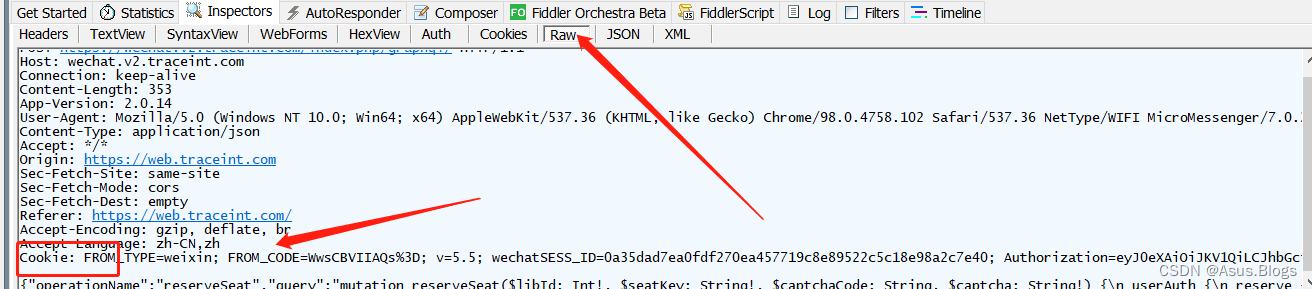
以上是第一次获取cookie的过程,因为要拿到header中的其他参数,所以我们需要手动模拟一次,在以后使用过程中,我们只需要抓取登录页面的cookie就可以了,不需要每次再手动选座获取了
最后填个坑:在fiddler运行过程中会自动开启代理

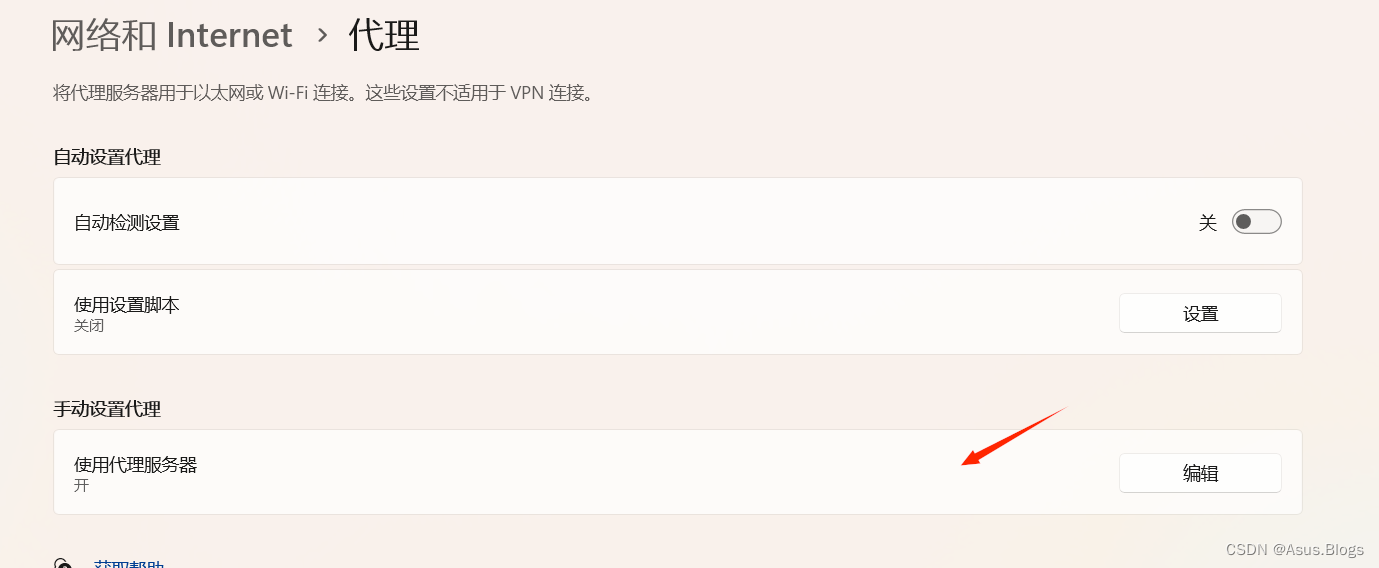
把下面这个关掉再去运行程序,或者拿到cookie之后把fiddler关掉去运行程序,如果开着这个代理的话程序是运行不了的
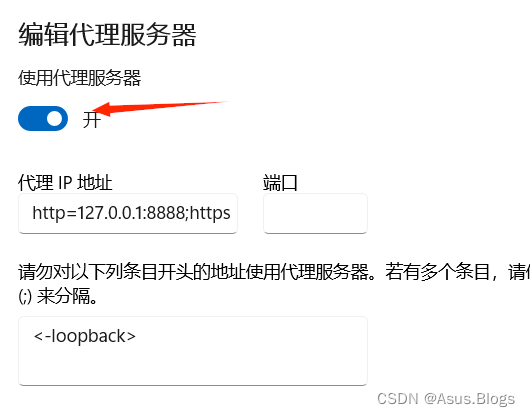
第二点是如果开着fiddler不正常关机的话会导致下次开机网页打不开,解决办法是重新打开fiddler再关掉就能解决了。本质是如果开着fiddler关机 ,此时的代理服务器会保存,也就是保存为下图的代理IP地址,从而导致网页打不开
2023-6-30日第六次更新(更新了大家心心念念的明日预约功能)
主要是太忙了没时间去想怎么实现这个功能,但我们图书馆突然发布通知说更改选座规则 只支持明日预约功能 这给我气的!被迫开发了只能~
以前总以为和选座一样 只改个data参数就能实现这个功能 没想到这个想法太简单了
主要是一直没有跨过去那个排队的逻辑,后来在B站遇见一个大佬 礼貌附上大佬主页,大家关注三连呀!,以及抓包发现是一个websocket连接,这方面是盲区,要来了大佬的代码,取出了他的排队逻辑,成功实现了明日预约功能
直接上代码
import json
import time
import requests
import websocket
cookieStr = 'Authorization=eyJ0eXAiOiJKV1QiLCJhbGciOiJSUzI1NiJ9.eyJ1c2VySWQiOjI0Nzg2NjU4LCJzY2hJZCI6MTMyLCJleHBpcmVBdCI6MTY4ODEzOTAwOH0.DNTDgOcTbEkipn1vCNMA1MlVapTc5nk-XbdHZp4tdV5Q7k3E-t3r4q1lHXenVp3u8ukvNQx3MhTq-3TT8spvQvAprE9X5DI3XKJC6zAgdWowZxiqPyg9CttQaNG3FSKcehPHDIb7ro5eY91iPf57G9KH26Yb10fpmrgrYBh6QXR-QZzk7F_enyEJuJCg92gX-NrTFAWwXG24mvaBdF-Cve6EqqD5R1bc1f34_YdMdtDapCrIgO6TodJejJJC9P7Yzws7Oqtumx_V87a6xtwzF25gD_PYXrrkeCV0pWlmRv5VYltHgRZ9AuoEN7lYl8cwefGDWv5fTkL1KRJtmFYSHg'
queue_header = {
'Host': '**',
'Connection': 'Upgrade',
'Pragma': 'no-cache',
'Cache-Control': 'no-cache',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36 NetType/WIFI MicroMessenger/7.0.20.1781(0x6700143B) WindowsWechat(0x63090551) XWEB/6945 Flue',
'Upgrade': 'websocket',
'Origin': 'https://**',
'Sec-WebSocket-Version': '13',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh',
'Sec-WebSocket-Key': 'eTYh3AZI8PuXyuPRr65Zbg==',
'Sec-WebSocket-Extensions': 'permessage-deflate; client_max_window_bits',
'Cookie': cookieStr
}
pre_header = {
'Host': '**',
'Connection': 'keep-alive',
'Content-Length': '307',
'User-Agent': 'User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36 NetType/WIFI MicroMessenger/7.0.20.1781(0x6700143B) WindowsWechat(0x63090551) XWEB/6945 Flue',
'Content-Type': 'application/json',
'Accept': '*/*',
'X-Requested-With': 'com.tencent.mm',
'Origin': 'https://**',
'Sec-Fetch-Site': 'same-origin',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Dest': 'empty',
'Referer': 'https://***/web/index.html',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh',
'Cookie': cookieStr
}
data = {"operationName": "save",
"query": "mutation save($key: String!, $libid: Int!, $captchaCode: String, $captcha: String) {\n userAuth {\n prereserve {\n save(key: $key, libId: $libid, captcha: $captcha, captchaCode: $captchaCode)\n }\n }\n}",
"variables": {"key": "*,*", "libid": **, "captchaCode": "", "captcha": ""}}
url = '**'
def pass_queue():
print("================================")
print("开始排队。。。")
ws = websocket.WebSocket()
# ws.connect("wss://wechat.**.com/ws?ns=prereserve/queue", header=headers)
ws.connect("wss://******/ws?ns=prereserve/queue", header=queue_header)
if ws.connected:
print('test pass queue connect')
while True:
ws.send('{"ns":"prereserve/queue","msg":""}')
a = ws.recv()
if a.find('u6392') != -1: # 排队成功返回的第一个字符
break
if a.find('u6210') != -1: # 已经抢座成功的返回
print("rsp msg:{}".format(json.loads(str(a))["msg"]))
time.sleep(5)
break
print("排队中,rsp:{}".format(a))
time.sleep(0.05)
# 关闭连接
ws.close()
time.sleep(0.05)
print("排队结束。。。")
print("================================")
# -----------------------------测试--------------------------------
# pass_queue()
# pass_queue()
#
# print('test pass queue ==> ok!')
# res = requests.post(url=url, headers=pre_header, json=data)
# print('test request ==> ok!')
# tm = res.elapsed.total_seconds()
# print(tm)
# print(res.status_code)
# print(res.text)
# -----------------------------正题--------------------------------
struct_openTime = "2023-6-30 23:14:00"
openTime = time.strptime(struct_openTime, "%Y-%m-%d %H:%M:%S")
openTime = time.mktime(openTime)
request_cnt = 0
while True:
# nowTime = int(time.mktime(time.localtime()))
print(time.time(), openTime)
if time.time() >= openTime:
# print(nowTime, openTime,time.time())
print("------------------------------")
print(time.time(), openTime)
print("ok Try to grab seat!")
grab_time = time.localtime(time.time())
ts = time.strftime("%Y-%m-%d %H:%M:%S", grab_time)
print('当前时间是: ' + ts)
request_cnt += 1
pass_queue()
pass_queue()
print('test pass queue ==> ok!')
res = requests.post(url=url, headers=pre_header, json=data)
print('test request ==> ok!')
tm = res.elapsed.total_seconds()
print(tm)
print(res.status_code)
print(res.text)
# break
if str(res.text).count("true"):
print("******************************")
print("恭喜你!预定成功!程序即将结束......")
print("******************************\n")
break
else:
time.sleep(0.3)
print("------------------------------\n\n")
if request_cnt >= 20: # 防止请求过多 被老师XX 所以这里我只敢 “最多” 请求10次
break # 另一个作用是避免图书馆服务器有延迟 加上上面的sleep 延迟时间可以控制在 10*0.3s = 3s 内 而且避免了过多的请求(程序1秒内发送的请求是很可怕的数量)
print("程序结束成功!")
2023-7-1日第七次更新(更新了免抓包获取cookie 灵感来自B站和Github两位大佬)
直接上代码把,这里如果大家使用的是我去图书馆官方的那个公众号 这里可以直接去Github上看项目代码,有直接可以拿url的二维码和完整的被我注释掉的部分,还有教程,完全可以用的。由于我们是学校服务器,所以这里就不放完整代码了,大家第一次可以抓包获取,至于如何使用以及如何获取需要输入的url,请移步Github或者B站大佬视频
import urllib.request
import urllib.parse
import http.cookiejar
def get_code(url):
query = urllib.parse.urlparse(url).query
codes = urllib.parse.parse_qs(query).get('code')
if codes:
return codes.pop()
else:
raise ValueError("Code not found in URL")
def get_cookie_string(code):
cookiejar = http.cookiejar.MozillaCookieJar()
opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cookiejar))
response = opener.open(
"https://**/urlNew/auth.html?" + urllib.parse.urlencode({
"r": "https://**/web/index.html",
"code": code,
"state": 1
})
)
print(response)
cookie_items = []
for cookie in cookiejar:
cookie_items.append(f"{cookie.name}={cookie.value}")
cookie_string = '; '.join(cookie_items)
return cookie_string
def main():
url = input("Please enter the URL: ")
code = get_code(url)
print(code)
cookie_string = get_cookie_string(code)
print("\nCookie string: \n")
print(cookie_string)
if __name__ == '__main__':
main()
2023-7-10日第八次更新(添加了异常捕获 避免报异常之后无法继续运行)
大家注意 抢座的data和预定的data是不一样的,具体参数也不一样!!!libId 和 libid 大小写~ 所以大家用的时候一定看清楚呀!!!
另外! time.time()这个获取的是本地电脑系统的时间,多次请求之后(大概连续抢一周的样子?就会慢个几秒钟,大家自测吧)会导致比北京时间快或者慢,从而导致程序提前结束或者延迟开始!大家要不定时同步系统时间,在设置里或者直接搜索时间即可!Win11挺方便的。还有一个解决方法是直接调用北京时间,不过我不愿意去实现了,真的太忙了!!!之前因为优化程序还通了个宵,导致两三天没恢复过来,后续看大家自己发挥吧!
import json
import time
from datetime import datetime
from datetime import timedelta
from datetime import timezone
import requests
import websocket
# -----------------------------测试--------------------------------
# rqst = 0
# while True:
# try:
# pass_queue()
# pass_queue()
#
# print('test pass queue ==> ok!')
# res = requests.post(url=url, headers=pre_header, json=data)
# print('test request ==> ok!')
# tm = res.elapsed.total_seconds()
# print(tm)
# print(res.status_code)
# print(res.text)
# rqst += 1
# if rqst >= 2:
# break
# except Exception as e:
# print(e)
# pass
# -----------------------------正题--------------------------------
# def get_utcTime():
# utc_now = datetime.utcnow().replace(tzinfo=timezone.utc)
#
# SHA_TZ = timezone(
# timedelta(hours=8),
# name='Asia/Shanghai',
# )
#
# # 北京时间
# beijing_now = utc_now.astimezone(SHA_TZ)
# print(beijing_now)
# print(type(beijing_now))
#
# fmt = '%Y-%m-%d %H:%M:%S'
# now_fmt = beijing_now.strftime(fmt)
# print(now_fmt)
# print(type(now_fmt))
# print('---------------------------')
# return now_fmt
struct_openTime = "2023-7-10 22:00:00"
openTime = time.strptime(struct_openTime, "%Y-%m-%d %H:%M:%S")
openTime = time.mktime(openTime)
request_cnt = 0
while True:
# nowTime = int(time.mktime(time.localtime()))
# print(get_utcTime(), openTime)
# print(, openTime)
timestamp = time.time()
# 转换成localtime
time_local = time.localtime(timestamp)
# 转换成新的时间格式(2016-05-05 20:28:54)
dt = time.strftime("%Y-%m-%d %H:%M:%S", time_local)
print(dt, struct_openTime)
if time.time() >= openTime:
# print(nowTime, openTime,time.time())
print("------------------------------")
# print(time.time(), openTime)
print("ok Try to grab seat!")
grab_time = time.localtime(timestamp)
ts = time.strftime("%Y-%m-%d %H:%M:%S", grab_time)
print('当前时间是: ' + ts)
request_cnt += 1
try:
pass_queue()
pass_queue()
print('test pass queue ==> ok!')
res = requests.post(url=url, headers=pre_header, json=data)
print('test request ==> ok!')
tm = res.elapsed.total_seconds()
print(tm)
print(res.status_code)
print(res.text)
if str(res.text).count("true"):
print("******************************")
print("恭喜你!预定成功!程序即将结束......")
print("******************************\n")
break
else:
print('---睡眠0.3s---')
time.sleep(0.3)
except Exception as e:
print(e)
# break
print('test Exception continue.')
print("------------------------------\n\n")
if request_cnt >= 100: # 防止请求过多 被老师XX 所以这里我只敢 “最多” 请求10次
break # 另一个作用是避免图书馆服务器有延迟 加上上面的sleep 延迟时间可以控制在 10*0.3s = 3s 内 而且避免了过多的请求(程序1秒内发送的请求是很可怕的数量)
print("程序结束成功!")
2023-9-10日第九次更新(更新大家反馈的座位信息如何抓取的方法)
进入选座页面,选择你想去的楼层,然后点进去
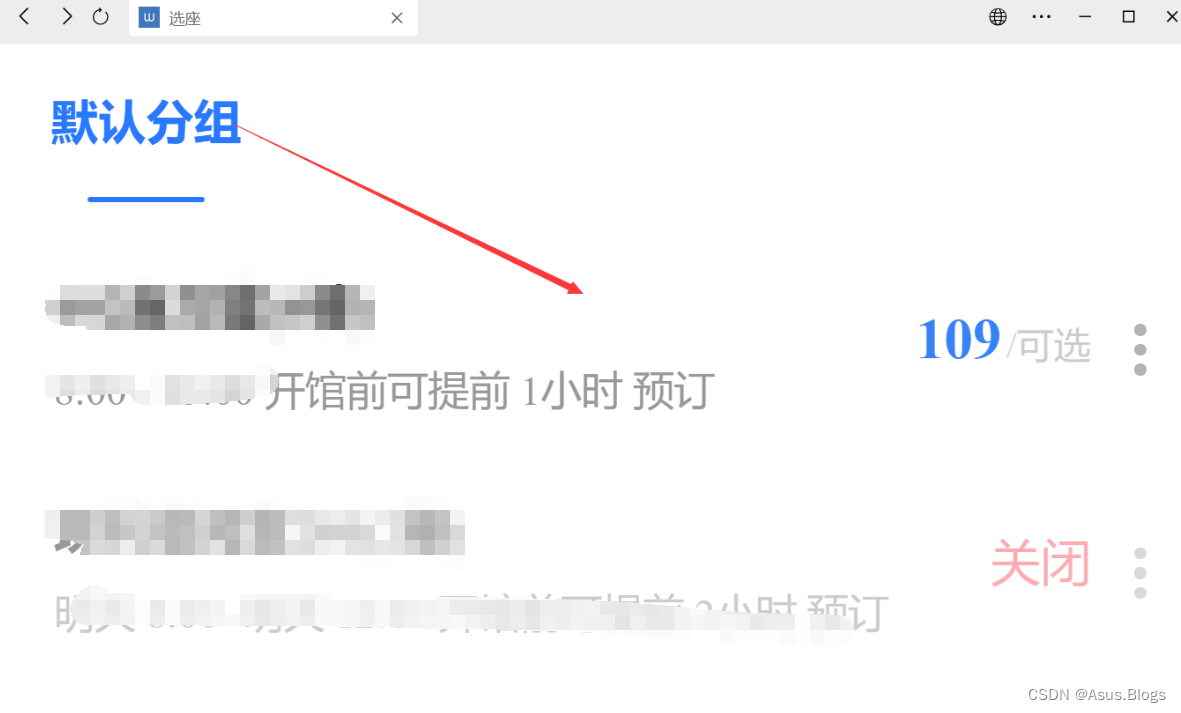
到这个页面,注意fldder发送的请求


一定要找准呀大家,这个没有就换一个看看,别死脑筋
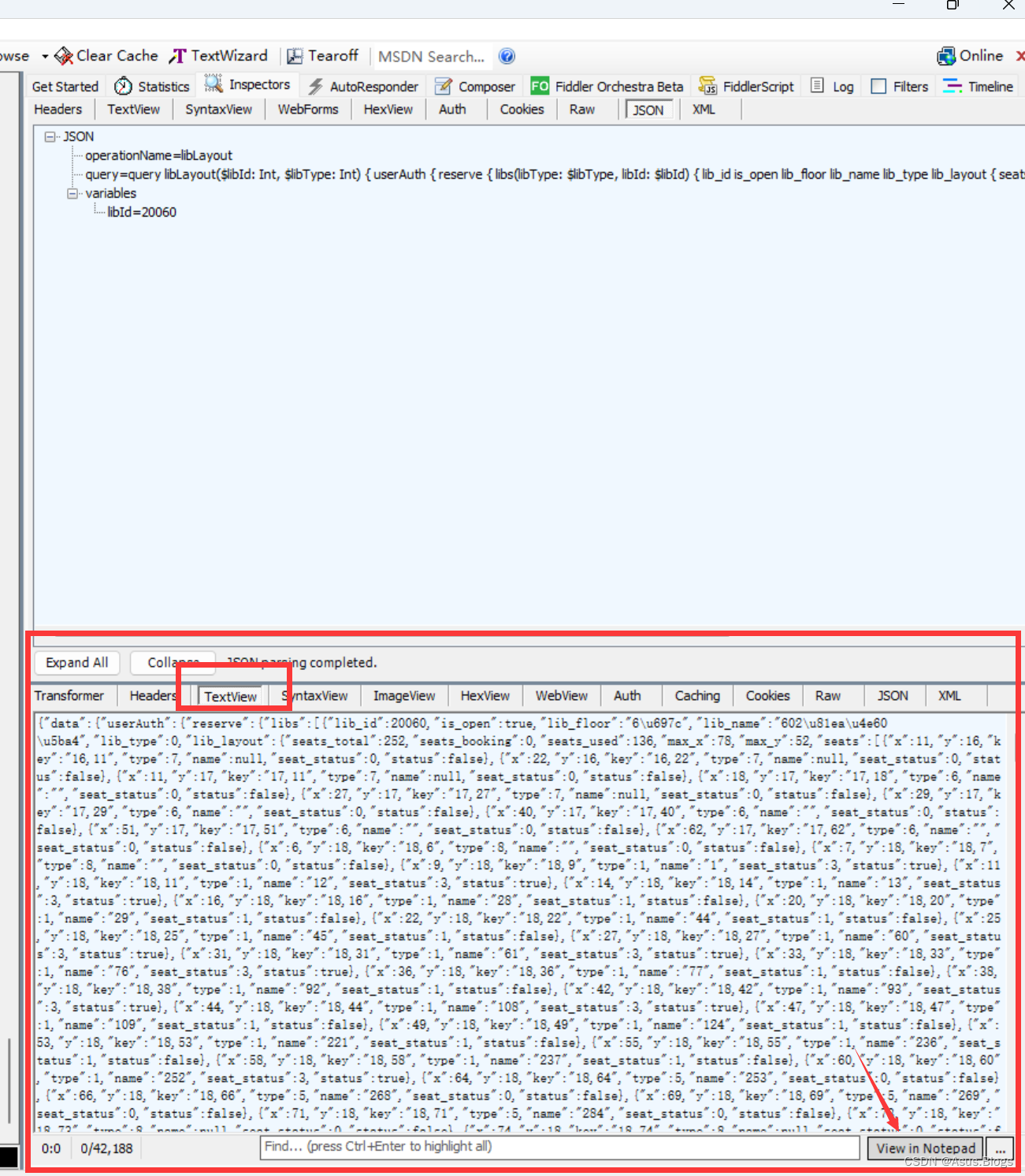
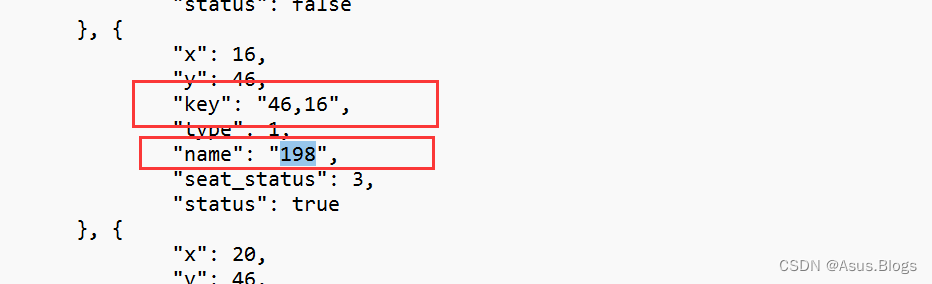
点这个打开就行了,大家可以找个json解析网站,这样好看一点,在弹出的txt文件中Ctrl+F搜索你想去的座位号 找到对应的key就行了,有可能每个学校的对应方式不一样 大家自己看着来,思路都是一样的。
2023-9-16日第十次更新(完整代码+抓包步骤整理)
import json
import time
import requests
import websocket
# 本代码初衷只为了测试post单次请求,并不会对服务器造成伤害,恶意修改请求与作者本人无关
# 以下代码需要自己动手的全用XXXX注释掉了,已测可用!
# -2.去抓url 参考第四次更新
# -1.去抓pre_header参考第四次更新,也就是url那次,我红框画出来了,直接填上‘XXXX’对应的就行(具体已大家自己抓的为准,少参数就补上,多参数就删除)queue_header里面的参数同pre_header中的一致。
# 0.去抓座位表 修改key 参考第九次更新
# 1.获取cookie 一定要使用十分钟内获取的新cookie!(这个可以用上面第七次更新的github上大佬写好的(前提是用的官方服务器哈,自己学校部署的话只能自己去fiddler抓了,随便找个登录的请求就含这个cookie的,很简单))
# 2.修改时间
# 3.开始运行代码
# 4.有bug评论区反馈,或者留言都可,看到回复,也有成功的小伙伴在帮助大家!
cookieStr = 'Authorization=eyJ0eXAiOiJKV1QiLCJhbGciOiJSUzI1NiJ9.eyJ1c2VySWQiOjM4NDQyNDU3LCJzY2hJZCI6MTMyLCJleHBpcmVBdCI6MTY5NDYyMTkzMH0.ZOkbMn1pQlUeUgix4OCXD6QZ1xf1Qkm7sJEavOdY3XjENj4mRAq5ovSaIQFcipNYE--QDNctWuK9YrH6EN6O-djiQZl_3p-X4Rnr52TAmA61tgkI2JUv8grqFVpPjCGIEPAWKbuTmvsMeIDNXdNTYOkA0GnWjskbkHRvpFGDienG8e8PD0nFw65N_XffWmdneMe7UR8Ut3kJV0nayzNsDgDzC2QIR1lf_oSORvcREKWFevwOikUpUbBXOvUA59u1_geuPw4f_yxD7bIgpyZ8lqnBgTUcGZyGhth2aeWwNDWuv6JY6mmFDLVTf-lvtJeIDN_lDlfKGtFaIxsyLqOvhg'
# cookies = []
queue_header = {
'Host': 'XXXX',
'Connection': 'Upgrade',
'Pragma': 'no-cache',
'Cache-Control': 'no-cache',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36 NetType/WIFI MicroMessenger/7.0.20.1781(0x6700143B) WindowsWechat(0x63090551) XWEB/6945 Flue',
'Upgrade': 'websocket',
'Origin': 'XXXX',
'Sec-WebSocket-Version': '13',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh',
'Sec-WebSocket-Key': 'eTYh3AZI8PuXyuPRr65Zbg==',
'Sec-WebSocket-Extensions': 'permessage-deflate; client_max_window_bits',
'Cookie': cookieStr
}
pre_header = {
'Host': 'XXXX',
'Connection': 'keep-alive',
'Content-Length': '307',
'User-Agent': 'User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36 NetType/WIFI MicroMessenger/7.0.20.1781(0x6700143B) WindowsWechat(0x63090551) XWEB/6945 Flue',
'Content-Type': 'application/json',
'Accept': '*/*',
'X-Requested-With': 'com.tencent.mm',
'Origin': 'XXXX',
'Sec-Fetch-Site': 'same-origin',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Dest': 'empty',
'Referer': 'XXXX',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh',
'Cookie': cookieStr
}
# 预约data
data = {"operationName": "save",
"query": "mutation save($key: String!, $libid: Int!, $captchaCode: String, $captcha: String) {\n userAuth {\n prereserve {\n save(key: $key, libId: $libid, captcha: $captcha, captchaCode: $captchaCode)\n }\n }\n}",
"variables": {"key": "35,18", "libid": 525, "captchaCode": "", "captcha": ""}}
# 抢座data
data3 = \
{"operationName": "reserveSeat",
"query": "mutation reserveSeat($libId: Int!, $seatKey: String!, $captchaCode: String, $captcha: String!) {\n userAuth {\n reserve {\n reserveSeat(\n libId: $libId\n seatKey: $seatKey\n captchaCode: $captchaCode\n captcha: $captcha\n )\n }\n }\n}",
"variables": {"seatKey": "35,18", "libId": 525, "captchaCode": "", "captcha": ""}}
url = 'XXXX'
def pass_queue():
print("================================")
print("开始排队。。。")
ws = websocket.WebSocket()
# ws.connect("wss://XXXX/ws?ns=prereserve/queue", header=headers)
ws.connect("wss://XXXX/ws?ns=prereserve/queue", header=queue_header) # 这里的XXXX和Host内容是一致的
if ws.connected:
print('test pass queue connect')
while True:
ws.send('{"ns":"prereserve/queue","msg":""}')
a = ws.recv()
if a.find('u6392') != -1: # 排队成功返回的第一个字符
break
if a.find('u6210') != -1: # 已经抢座成功的返回
print("rsp msg:{}".format(json.loads(str(a))["msg"]))
time.sleep(5)
break
print("排队中,rsp:{}".format(a))
# time.sleep(0.01)
# 关闭连接
ws.close()
# time.sleep(0.01)
print("排队结束。。。")
print("================================")
struct_openTime = "2023-8-29 22:00:00"
openTime = time.strptime(struct_openTime, "%Y-%m-%d %H:%M:%S")
openTime = time.mktime(openTime)
request_cnt = 0
while True:
timestamp = time.time()
# 转换成localtime
time_local = time.localtime(timestamp)
# 转换成新的时间格式(2016-05-05 20:28:54)
dt = time.strftime("%Y-%m-%d %H:%M:%S", time_local)
print(dt, struct_openTime)
if time.time() >= openTime:
print("------------------------------")
print("ok Try to grab seat!")
grab_time = time.localtime(timestamp)
ts = time.strftime("%Y-%m-%d %H:%M:%S", grab_time)
request_cnt += 1
try:
pass_queue()
pass_queue()
print('test pass queue ==> ok!')
res = requests.post(url=url, headers=pre_header, json=data)
print('test request ==> ok!')
unicode = str(res.text).encode('utf-8').decode('unicode_escape')
print(unicode)
if str(res.text).count("true"):
print("******************************")
print("恭喜你!预定成功!程序即将结束......")
print("******************************\n")
break
else:
# print('---睡眠0.3s---')
pass_queue()
pass_queue()
time.sleep(0.3)
except Exception as e:
time.sleep(0.3)
print(e)
# print('test Exception continue.')
# break
print("------------------------------\n\n")
if request_cnt >= 100: # 防止请求过多 被老师XX 所以这里我只敢 “最多” 请求10次
break # 另一个作用是避免图书馆服务器有延迟 加上上面的sleep 延迟时间可以控制在 10*0.3s = 3s 内 而且避免了过多的请求(程序1秒内发送的请求是很可怕的数量)
print("程序结束成功!")
bug反馈区,持续更新…
大家有bug私信我留言就好了,我有时间就看一下。
关于pycharm运行报错误(已解决)

环境问题 只安装了webscoket而没有安装websocket-client 移步 这篇
webscoket 和 websocket-client # 都需要安装
pip install webscoket
pip install websocket-client
下面这个错误 两种可能:
①cookie失效 返回msg1000
②擅自修改排队逻辑!

post返回请刷新页面 原因是只调用了一次queue请求,需要调用两次!

关于大家反馈的 返回true 没有预约成功的问题解决方案
这个问题我这边从来没遇到过,但是挺多小伙伴反馈的,我也没法debug,不过评论区还是有大佬的,附上大佬主页 具体我没分析,直接给代码吧,你们自己看一下。


import json
import time
import requests
import websocket
cookieStr = 'FROM_TYPE=weixin; v=5.5; wechatSESS_ID=3249adb14bbfaa3696a3ba10b07bf6d22e1f3308eaf53a7d; Authorization=eyJ0eXAiOiJKV1QiLCJhbGciOiJSUzI1NiJ9.eyJ1c2VySWQiOjMzNTA3NDIxLCJzY2hJZCI6MTI1LCJleHBpcmVBdCI6MTY5NTU2NDU3NX0.t-_qmL3psd4iFt_i1qTkvzkZN6bw3ndrC37YmfM4kLbWkRPmtkr7tkdaEuJlc8thPaGLbeW9wjtgJ40HyLvT9XA1ftfEN3PiGma-ecp3DRmu14TRzdizYSA5-x2cQyGpvsqHKx9Cui_hUvvHkFoEZ9nB-OjsTqtV4qbAONAHr6LNjP1_uj6WWzZfjPlzas9jluJ1CT1l9ZGM6W7PHphii6J43iktBdvo5pDrjdGkRsSInrhgKLsKmrlCPJpVmZkutNHWCprkVXXC_OakDi1csTlFhpxijGr6V-x3p4WrlevLDf1iGpC4_5Waw4e2hjY67X8rP_ZCPR1lBeLR7jHEiA; Hm_lvt_7ecd21a13263a714793f376c18038a87=1695393717,1695468036,1695481400,1695557376; SERVERID=82967fec9605fac9a28c437e2a3ef1a4|1695560173|1695560031; Hm_lpvt_7ecd21a13263a714793f376c18038a87=1695560174'
queue_header = {
'Host': 'XXXX',
'Connection': 'Upgrade',
'Pragma': 'no-cache',
'Cache-Control': 'no-cache',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36 NetType/WIFI MicroMessenger/7.0.20.1781(0x6700143B) WindowsWechat(0x63090719) XWEB/8391 Flue',
'Upgrade': 'websocket',
'Origin': 'XXXX',
'Sec-WebSocket-Version': '13',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh',
'Sec-WebSocket-Key': 'h/hkRDGbwZ1VCVfpL54B8w==',
'Sec-WebSocket-Extensions': 'permessage-deflate; client_max_window_bits',
'Cookie': cookieStr
}
# 先自己抓包,然后填入请求头中的每一个参数
pre_header = {
'Host': 'XXXX',
'Connection': 'keep-alive',
'Content-Length': '309',
'App-Version': '2.0.14',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36 NetType/WIFI MicroMessenger/7.0.20.1781(0x6700143B) WindowsWechat(0x63090719) XWEB/8391 Flue',
'Content-Type': 'application/json',
'Accept': '*/*',
'Origin': 'XXXX',
'Sec-Fetch-Site': 'same-origin',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Dest': 'empty',
'Referer': 'XXXX',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh',
'Cookie': cookieStr
}
# 预约data
data = {
"operationName": "save",
"query": "mutation save($key: String!, $libid: Int!, $captchaCode: String, $captcha: String) {\n userAuth {\n prereserve {\n save(key: $key, libId: $libid, captcha: $captcha, captchaCode: $captchaCode)\n }\n }\n}",
"variables": {
# "key": "35,4.",
# "libid": 122202,
# "key": "16,20",
# "libid": 122188,
# "key": "4,16",
# "libid": 122265,
# often seat
"key": "24,26", #这里要加个.? 你们自己看上面的聊天记录调吧
"libid": 490,
# "key": "20,26",
# "libid": 490,
"captchaCode": "",
"captcha": ""
}
}
# # 抢座data
# data3 = \
# {"operationName": "reserveSeat",
# "query": "mutation reserveSeat($libId: Int!, $seatKey: String!, $captchaCode: String, $captcha: String!) {\n userAuth {\n reserve {\n reserveSeat(\n libId: $libId\n seatKey: $seatKey\n captchaCode: $captchaCode\n captcha: $captcha\n )\n }\n }\n}",
# "variables": {"seatKey": "35,18", "libId": 525, "captchaCode": "", "captcha": ""}}
data2 = {"operationName": "prereserve",
"query": "query prereserve {\n userAuth {\n prereserve {\n prereserve {\n day\n lib_id\n seat_key\n seat_name\n is_used\n user_mobile\n id\n lib_name\n }\n }\n }\n}"}
data3 = {"operationName": "index",
"query": "query index {\n userAuth {\n user {\n prereserveAuto: getSchConfig(extra: true, fields: \"prereserve.auto\")\n }\n currentUser {\n sch {\n isShowCommon\n }\n }\n prereserve {\n libs {\n is_open\n lib_floor\n lib_group_id\n lib_id\n lib_name\n num\n seats_total\n }\n }\n oftenseat {\n prereserveList {\n id\n info\n lib_id\n seat_key\n status\n }\n }\n }\n}"}
data4 = {"operationName": "prereserveCheckMsg",
"query": "query prereserveCheckMsg {\n userAuth {\n prereserve {\n prereserveCheckMsg\n }\n }\n}"}
data_lib_chosen = {
"operationName": "libLayout",
"query": "query libLayout($libId: Int!) {\n userAuth {\n prereserve {\n libLayout(libId: $libId) {\n max_x\n max_y\n seats_booking\n seats_total\n seats_used\n seats {\n key\n name\n seat_status\n status\n type\n x\n y\n }\n }\n }\n }\n}",
"variables": {
"libId": 490
}
}
url = 'XXXX'
def pass_queue():
print("================================")
print("开始排队。。。")
ws = websocket.WebSocket()
# ws.connect("wss://XXXX/ws?ns=prereserve/queue", header=headers)
ws.connect('wss://XXXX/ws?ns=prereserve/queue', header=queue_header, verify=False) # 这里的XXXX和Host内容是一致的
if ws.connected:
print('test pass queue connect')
while True:
ws.send('{"ns":"prereserve/queue","msg":""}')
a = ws.recv()
if a.find('u6392') != -1: # 排队成功返回的第一个字符
break
if a.find('u6210') != -1: # 已经抢座成功的返回
print("rsp msg:{}".format(json.loads(str(a))["msg"]))
time.sleep(5)
break
print("排队中,rsp:{}".format(a))
# time.sleep(0.01)
# 关闭连接
ws.close()
# time.sleep(0.01)
print("排队结束。。。")
print("================================")
def time_update():
# struct_openTime = "****-**-** 21:00:00"
now = time.gmtime()
return now.tm_year.__str__() + '-' + now.tm_mon.__str__() + '-' + now.tm_mday.__str__() + ' 21:00:00'
# 开始时间
struct_openTime = "2023-9-25 21:00:00"
# struct_openTime = time_update()
openTime = time.strptime(struct_openTime, "%Y-%m-%d %H:%M:%S")
openTime = time.mktime(openTime)
request_cnt = 0
while True:
timestamp = time.time()
# 转换成localtime
time_local = time.localtime(timestamp)
# 转换成新的时间格式(2016-05-05 20:28:54)
dt = time.strftime("%Y-%m-%d %H:%M:%S", time_local)
print(dt, struct_openTime)
if time.time() >= openTime:
print("------------------------------")
print("ok Try to grab seat!")
grab_time = time.localtime(timestamp)
ts = time.strftime("%Y-%m-%d %H:%M:%S", grab_time)
request_cnt += 1
try:
pass_queue()
pass_queue()
print('test pass queue ==> ok!')
# 重要!如果不是放在常用座位,需要先请求对应的阅览室的所有座位,libLayout!!
requests.post(url=url, headers=pre_header, json=data_lib_chosen, verify=False)
# 抢座的post请求,core code
res = requests.post(url=url, headers=pre_header, json=data, verify=False)
print('test request ==> ok!')
print(res.text)
text_Res = requests.post(url=url, headers=pre_header, json=data2, verify=False).text
unicode = str(res.text).encode('utf-8').decode('unicode_escape')
text_uni = str(text_Res).encode('utf-8').decode('unicode_escape')
print(text_uni)
print(unicode)
if str(res.text).count("true") and text_Res.count('user_mobile'):
print("******************************")
print("恭喜你!预定成功!程序即将结束......")
print("******************************\n")
else:
# print('---睡眠0.3s---')
pass_queue()
pass_queue()
time.sleep(0.3)
except Exception as e:
time.sleep(0.3)
print(e)
# print('test Exception continue.')
# break
print("------------------------------\n\n")
if request_cnt >= 25: # 防止请求过多 被老师XX 所以这里我只敢 “最多” 请求10次
break # 另一个作用是避免图书馆服务器有延迟 加上上面的sleep 延迟时间可以控制在 10*0.3s = 3s 内 而且避免了过多的请求(程序1秒内发送的请求是很可怕的数量)
print("程序结束成功!")
上面这个是大佬修改后的,我没仔细看,应该是没问题的,大家自己看着优化吧,跑了跑了~。
写在最后 本次更新后估计很少再对程序优化了,虽然没有达到全自动抢座(是指由程序自动获取cookie 然后定时提交登录)甚至基本的UI界面都没有。毕竟考研年没太多时间精力再去优化了,因为手动抓取cookie也就几秒的时间,而且本程序初衷也是为了避免自己喜欢的座位被抢掉,现在通过半自动已经达到目的了,另外也总不能天天有人给你抢座吧,所以大家平时还是在手机上选座提交就行啦。
2023-6-30 23:27更: 无论是抢座还是明日预约 本博客已全部实现,可能方法比较low但是都能准时抢,至于更多的优化交给各位吧!
2023-9-10 22:44更:大家注意,所有的源码都在文章里了,可能比较乱,其实就是比较乱,不过大家以最后一次更新的完整代码为准,其中我把很多关键用**代替了,大家直接跑是不行的!而且大家要运行肯定是要自己去抓地址和座位的,所以直接跑也是没有任何意义的。
综上,祝好!
标签:
相关文章
最新发布
- 光流法结合深度学习神经网络的原理及应用(完整代码都有Python opencv)
- Python 图像处理进阶:特征提取与图像分类
- 大数据可视化分析-基于python的电影数据分析及可视化系统_9532dr50
- 【Python】入门(运算、输出、数据类型)
- 【Python】第一弹---解锁编程新世界:深入理解计算机基础与Python入门指南
- 华为OD机试E卷 --第k个排列 --24年OD统一考试(Java & JS & Python & C & C++)
- Python已安装包在import时报错未找到的解决方法
- 【Python】自动化神器PyAutoGUI —告别手动操作,一键模拟鼠标键盘,玩转微信及各种软件自动化
- Pycharm连接SQL Sever(详细教程)
- Python编程练习题及解析(49题)
点击排行
- 版本匹配指南:Numpy版本和Python版本的对应关系
- 版本匹配指南:PyTorch版本、torchvision 版本和Python版本的对应关系
- Python 可视化 web 神器:streamlit、Gradio、dash、nicegui;低代码 Python Web 框架:PyWebIO
- 相关性分析——Pearson相关系数+热力图(附data和Python完整代码)
- Anaconda版本和Python版本对应关系(持续更新...)
- Python与PyTorch的版本对应
- Windows上安装 Python 环境并配置环境变量 (超详细教程)
- Python pyinstaller打包exe最完整教程
本站推荐
