首页 > Python资料 博客日记
Scrapy和Selenium整合(一文搞定)
2024-03-17 14:00:06Python资料围观197次
文章Scrapy和Selenium整合(一文搞定)分享给大家,欢迎收藏Python资料网,专注分享技术知识
文章目录
前言
scrapy和selenium的整合使用
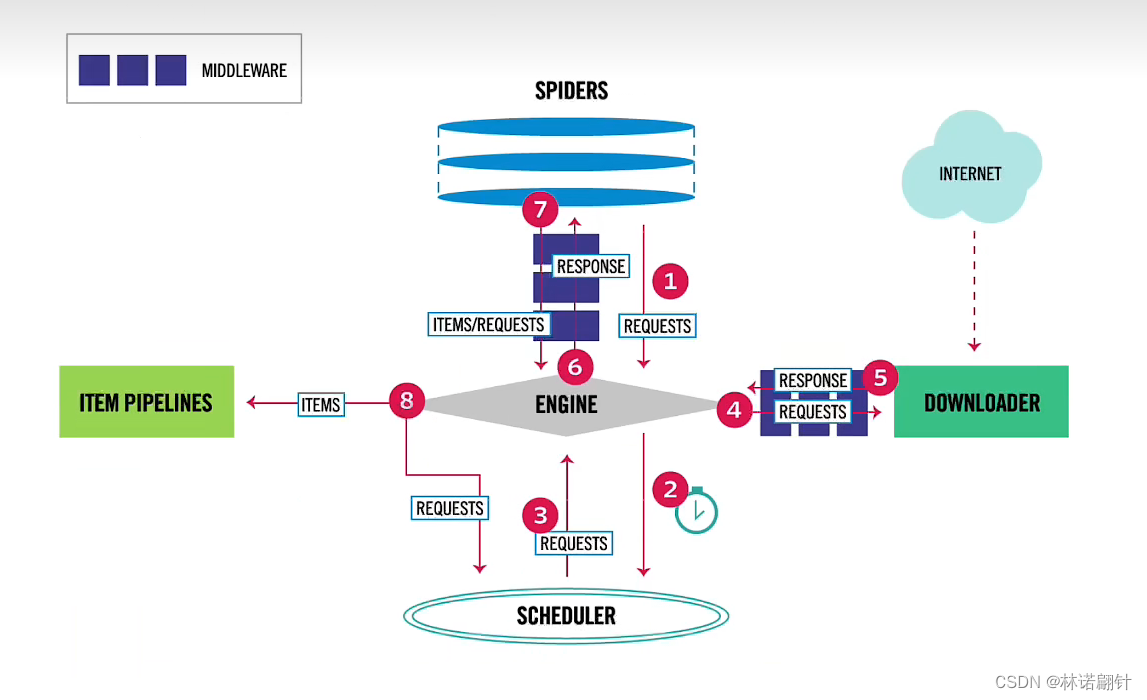
先定个小目标实现万物皆可爬!我们是用scrapy框架来快速爬取页面上的数据,它是自带并发的,速度是可以的。但是一些ajax异步的请求我们不能这么爬取。我们要视同selenium来进行lazy loading,也就是懒加载,渲染到页面加载数据。
一、开始准备
1. 包管理和安装chrome驱动
首先你要安装以下包:
pip install scrapy
pip install selenium == 3.0.0
pip install pymysql
pip install bs4
- selenium新版本有bug,用3.0的版本。
- chrome驱动的exe执行文件,放到你项目的根目录即可。下载地址:驱动
2. 爬虫项目的创建(举个栗子)
- 创建项目
scrapy startproject cnki
- 您爬取的目标网站
scrapy genspider cnki https://www.cnki.net
- 运行爬虫
# 运行不导出(一般在pipelines做导出操作)
scrapy crawl cnki
# 针对不同的选择可以导出为xlsx、json等格式文件
scrapy crawl demo -o demo.csv
3. setting.py的配置
- 配置数据源,如下:
DB_HOST = 'localhost'
DB_PORT = 3306
DB_USER = 'root'
DB_PASSWORD ='123456'
DB_DATABASE = 'spider'
- 防止打印log日志信息
LOG_LEVEL = 'WARNING'
- 配置USER_AGENT(浏览器控制台找一个)
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36
- 配置DEFAULT_REQUEST_HEADERS(浏览器控制台找一个)
{
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
}
- 随机延迟
DOWNLOAD_DELAY = 3
RANDOMIZE_DOWNLOAD_DELAY=True
- 中间件权重配置(这些中间件给他打开 并且按照项目实际需求配置权重,越小越先执行)
SPIDER_MIDDLEWARES # 蜘蛛中间件
DOWNLOADER_MIDDLEWARES # 下载中间件
ITEM_PIPELINES # 管道
二、代码演示
1. 主爬虫程序
- 初始化selenium (如果您不需要selenium,可以忽略这个 )
def __init__(self, *args,**kwargs):
option = webdriver.ChromeOptions() # 实例化一个浏览器对象
option.add_argument('--headless') # 添加参数,option可以是headless,--headless,-headless
self.driver = webdriver.Chrome(options=option) # 创建一个无头浏览器
# self.driver = webdriver.Chrome() # 创建一个无头浏览器
time.sleep(3)
super(CnkiSpider, self).__init__(*args, **kwargs)
dispatcher.connect(self.close_driver,signals.spider_closed)
- 定义开始请求页面
下面我只放了一个url,其实可以定义一组的然后进行遍历(一般是分页url使用)
还有cookie、代理也可以在这里配置,详情请看进去看源码(不过一般在中间件配置)
def start_requests(self):
for url in self.start_urls:
yield scrapy.Request(
# 这里可以设置多个页面,一般用于分页的
url=url,
)
- 关闭selenium(一定要关掉)
def close_driver(self):
print("爬虫正在退出,执行关闭浏览器哦")
time.sleep(2)
self.driver.quit()
- 解析页面
这里就不多说,八仙过海各显神通
def parse(self,response: HtmlResponse):
sel = Selector(response)
dds = sel.css('.journal > .main-w1 > dl > dd')
for dd in dds:
title = dd.css('h6 > a::attr(title)').extract_first()
link = dd.css('h6 > a::attr(href)').extract_first()
link = response.urljoin(link)
author = dd.css('.baseinfo > span > #author::attr(title)').extract_first()
abstract = dd.css('.abstract::text').extract_first()
count = dd.css('.opts > .opts-count > li > em::text').extract_first()
count = int(count)
date = dd.css('.opts > .opts-count > .date::text').extract_first()
date = date.split(':')[1]
date = datetime.datetime.strptime(date,"%Y-%m-%d")
rc = Recommend()
rc['title'] = title
rc['link'] = link
rc['author'] = author
rc['abstract'] = abstract
rc['count'] = count
rc['date'] = date
yield rc
这里要注意我们yield可以返回不仅是item,也可以是Request,进行页面详情的请求(套娃)
yield Request(
url=link, # 这是上面页面上的链接,用来进一步请求
callback=self.parse_detail, # 这是回调函数
cb_kwargs={'item':rc} # 这是把上面的item传递下来
)
2. 中间件的配置
- 针对selenium
没有selenium请忽略
class SeleniumDownloaderMiddleware:
def process_request(self, request , spider):
if spider.name == 'cnki':
spider.driver.get(request.url)
time.sleep(2)
print(f"当前访问{request.url}")
spider.driver.refresh()
time.sleep(3)
return HtmlResponse(url=spider.driver.current_url,body=spider.driver.page_source,encoding='utf-8')
- SpiderMiddleware保持默认配置即可
- DownloaderMiddleware可以配置cookie和代理之类的。如:
# 我自定义的解析cookie方法
def get_cookie_dict():
cookie_str = 填上你的cookie
cookie_dict = {}
for item in cookie_str.split(';'):
key, value = item.split('=',maxsplit=1)
cookie_dict[key] = value
return cookie_dict
COOKIES_DICT = get_cookie_dict()
# 这是DownloaderMiddleware这是自带的方法哈
def process_request(self, request : Request, spider):
request.cookies = COOKIES_DICT
return None
3. 定义item对象
用来接受爬虫到的数据
class Recommend(scrapy.Item):
title = scrapy.Field()
author = scrapy.Field()
abstract = scrapy.Field()
link = scrapy.Field()
count = scrapy.Field()
date = scrapy.Field()
4. 定义管道
实现对数据库的导入(你也可以写excel的)
class RecommendPipeline:
@classmethod
def from_crawler(cls, crawler: Crawler):
host = crawler.settings['DB_HOST']
port = crawler.settings['DB_PORT']
username = crawler.settings['DB_USER']
password = crawler.settings['DB_PASSWORD']
database = crawler.settings['DB_DATABASE']
return cls(host, port, username, password, database)
def __init__(self, host, port, username, password, database):
# 1、与数据库建立连接
self.conn = pymysql.connect(host=host, port=port, user=username, password=password, database=database,
charset='utf8mb4')
# 2、创建游标
self.cursor = self.conn.cursor()
# 3、批处理需要的容器
self.data = []
def process_item(self, item, spider):
title = item.get('title', '')
author = item.get('author', '')
abstract = item.get('abstract', '')
link = item.get('link', '')
count = item.get('count', '')
date = item.get('date', '')
# 如果要实现批处理:
self.data.append((title,author,abstract,link,count,date))
# 如果存够了10条就进数据库
if len(self.data) == 10:
self._to_write_db()
# 然后再清空
self.data.clear()
return item
def close_spider(self, spider):
# 如果最后不满足10条
if len(self.data) > 0:
self._to_write_db()
self.conn.close()
def _to_write_db(self):
# 作为一个实时的推荐,我希望将查到的数据作为一个temp
# 'delete from tb_recommend where 1 = 1' 删除满,并且主键自增不会从1开始
self.cursor.execute(
'truncate table tb_recommend'
)
self.cursor.executemany(
'insert into tb_recommend (title,author,abstract,link,count,date) values (%s, %s, %s, %s, %s, %s)',
self.data
)
self.conn.commit()
记得写入setting.py,设置其权重。
*接下来您就可以按照这种方法‘愉’ ‘快’的进行爬虫啦!!! *
总结
这是scrapy和selenium的具体整合使用,scrapy框架的内容还有很多方法还没用到,都有待开发。其次就是selenium的填充之类的操作还没有使用,还需要去复习selenium的api。
版权声明:本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若内容造成侵权/违法违规/事实不符,请联系邮箱:jacktools123@163.com进行投诉反馈,一经查实,立即删除!
标签:
相关文章
最新发布
- 光流法结合深度学习神经网络的原理及应用(完整代码都有Python opencv)
- Python 图像处理进阶:特征提取与图像分类
- 大数据可视化分析-基于python的电影数据分析及可视化系统_9532dr50
- 【Python】入门(运算、输出、数据类型)
- 【Python】第一弹---解锁编程新世界:深入理解计算机基础与Python入门指南
- 华为OD机试E卷 --第k个排列 --24年OD统一考试(Java & JS & Python & C & C++)
- Python已安装包在import时报错未找到的解决方法
- 【Python】自动化神器PyAutoGUI —告别手动操作,一键模拟鼠标键盘,玩转微信及各种软件自动化
- Pycharm连接SQL Sever(详细教程)
- Python编程练习题及解析(49题)
点击排行
- 版本匹配指南:Numpy版本和Python版本的对应关系
- 版本匹配指南:PyTorch版本、torchvision 版本和Python版本的对应关系
- Python 可视化 web 神器:streamlit、Gradio、dash、nicegui;低代码 Python Web 框架:PyWebIO
- 相关性分析——Pearson相关系数+热力图(附data和Python完整代码)
- Anaconda版本和Python版本对应关系(持续更新...)
- Python与PyTorch的版本对应
- Windows上安装 Python 环境并配置环境变量 (超详细教程)
- Python pyinstaller打包exe最完整教程
本站推荐
