首页 > Python资料 博客日记
安装spacy+zh_core_web_sm避坑指南
2024-03-23 05:00:04Python资料围观2041次
文章安装spacy+zh_core_web_sm避坑指南分享给大家,欢迎收藏Python资料网,专注分享技术知识
目录
一、spacy简介
spacy是Python自然语言处理(NLP)软件包,可以对自然语言文本做词性分析、命名实体识别、依赖关系刻画,以及词嵌入向量的计算和可视化等。
二、安装spacy
使用“pip install spacy"报错, 或者安装完spacy,无法正常调用,可以通过以下链接将whl文件下载到本地,然后 cd 到文件路径下,通过 pip 安装。
下载链接:
Archived: Python Extension Packages for Windows - Christoph Gohlke (uci.edu)
选择对应的版本:

三、安装zh_core_web_sm
通过下方链接下载 whl 文件到本地:
zh_core_web_sm · Releases · explosion/spacy-models (github.com)
选择对应的版本:
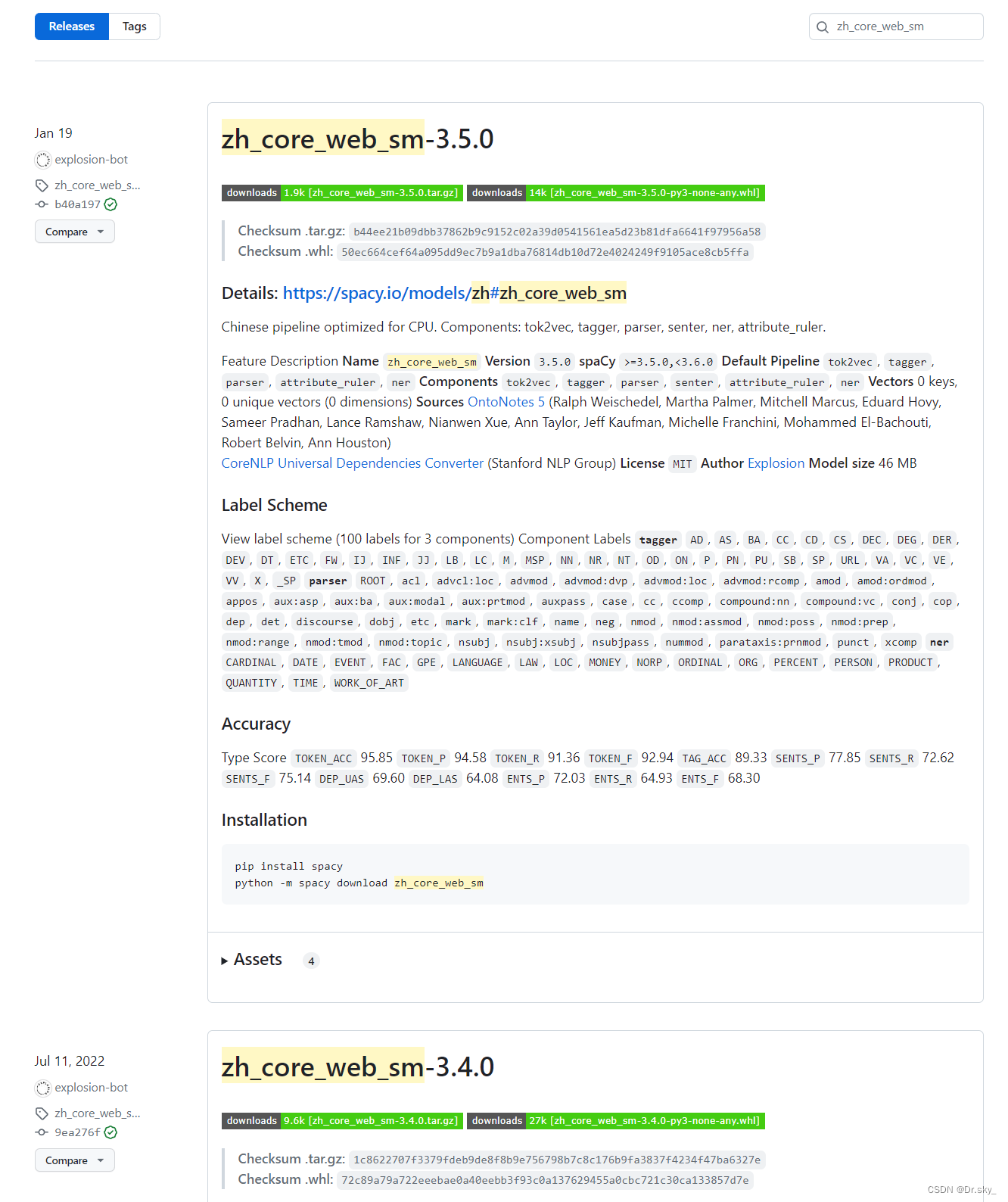
下载好对应版本的zh_core_web_sm.whl文件,cd 文件保存目录,然后通过pip安装。
安装成功提示:

四、安装en_core_web_sm
通过下方链接下载 whl 文件到本地:
en_core_web_sm · Releases · explosion/spacy-models (github.com)
选择对应的版本:
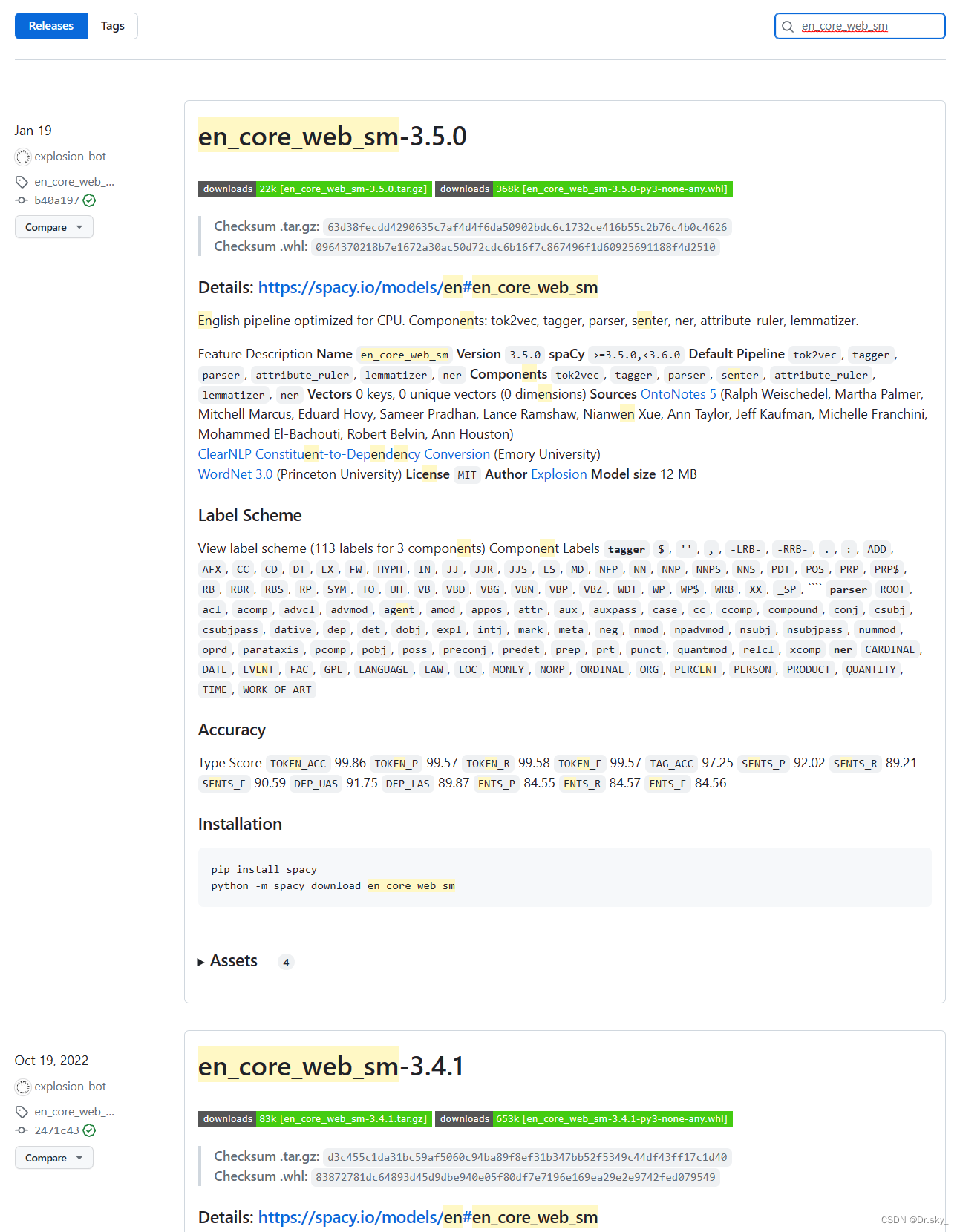
下载好对应版本的zh_core_web_sm.whl文件,cd 文件保存目录,然后通过pip安装。
五、效果测试
5.1 英文测试
# 导入英文类
from spacy.lang.en import English
# 实例化一个nlp类对象,包含管道pipeline
nlp = English()
# print(nlp)
doc = nlp("December is excited!")
# 迭代tokens
for token in doc:
print(token.text)
token = doc[1]
print(token.text)输出结果:
December
is
excited
!
is5.2 中文测试
# 处理文本
nlp = spacy.load('zh_core_web_sm')
doc = nlp("微软准备用十亿美金买下这家英国的创业公司。")
# 遍历识别出的实体
for ent in doc.ents:
# 打印实体文本及其标注
print(ent.text, ent.label_)输出结果:
微软 ORG
十亿美金 MONEY
英国 NORP版权声明:本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若内容造成侵权/违法违规/事实不符,请联系邮箱:jacktools123@163.com进行投诉反馈,一经查实,立即删除!
标签:
相关文章
最新发布
- 光流法结合深度学习神经网络的原理及应用(完整代码都有Python opencv)
- Python 图像处理进阶:特征提取与图像分类
- 大数据可视化分析-基于python的电影数据分析及可视化系统_9532dr50
- 【Python】入门(运算、输出、数据类型)
- 【Python】第一弹---解锁编程新世界:深入理解计算机基础与Python入门指南
- 华为OD机试E卷 --第k个排列 --24年OD统一考试(Java & JS & Python & C & C++)
- Python已安装包在import时报错未找到的解决方法
- 【Python】自动化神器PyAutoGUI —告别手动操作,一键模拟鼠标键盘,玩转微信及各种软件自动化
- Pycharm连接SQL Sever(详细教程)
- Python编程练习题及解析(49题)
点击排行
- 版本匹配指南:Numpy版本和Python版本的对应关系
- 版本匹配指南:PyTorch版本、torchvision 版本和Python版本的对应关系
- Anaconda版本和Python版本对应关系(持续更新...)
- 相关性分析——Pearson相关系数+热力图(附data和Python完整代码)
- Python 可视化 web 神器:streamlit、Gradio、dash、nicegui;低代码 Python Web 框架:PyWebIO
- Windows上安装 Python 环境并配置环境变量 (超详细教程)
- Python与PyTorch的版本对应
- 安装spacy+zh_core_web_sm避坑指南
本站推荐
