首页 > Python资料 博客日记
【python】pyarrow.parquet+pandas:读取及使用parquet文件
2024-03-23 08:00:06Python资料围观1209次
文章【python】pyarrow.parquet+pandas:读取及使用parquet文件分享给大家,欢迎收藏Python资料网,专注分享技术知识
文章目录
Parquet是一种用于列式存储和压缩数据的文件格式,广泛应用于大数据处理和分析中。Python提供了多个库来处理Parquet文件,例如pyarrow和fastparquet。
本文将介绍如何使用pyarrow.parquet+pandas库操作Parquet文件。
一、前言
1. 所需的库
import pyarrow.parquet as pq
import pandas as pd
pyarrow.parquet模块,可以读取和写入Parquet文件,以及进行一系列与Parquet格式相关的操作。例如,可以使用该模块读取Parquet文件中的数据,并转换为pandas DataFrame来进行进一步的分析和处理。同时,也可以使用这个模块将DataFrame的数据保存为Parquet格式。
2. 终端指令
conda create -n DL python==3.11
conda activate DL
conda install pyarrow
或
pip install pyarrow
二、pyarrow.parquet
当使用pyarrow.parquet模块时,通常的操作包括读取和写入Parquet文件,以及对Parquet文件中的数据进行操作和转换。以下是一些常见的使用方法:
1. 读取Parquet文件
import pyarrow.parquet as pq
parquet_file = pq.ParquetFile('file.parquet')
data = parquet_file.read().to_pandas()
- 使用
pq.ParquetFile打开Parquet文件; - 使用
read().to_pandas()方法将文件中的数据读取为pandas DataFrame。
2. 写入Parquet文件
import pandas as pd
import pyarrow as pa
import pyarrow.parquet as pq
df = pd.DataFrame({'col1': [1, 2, 3], 'col2': ['a', 'b', 'c']})
table = pa.Table.from_pandas(df)
pq.write_table(table, 'output.parquet')
- 将pandas DataFrame转换为Arrow的Table格式;
- 使用
pq.write_table方法将Table写入为Parquet文件。
parquet_file = pq.ParquetFile('output.parquet')
data = parquet_file.read().to_pandas()
print(data)
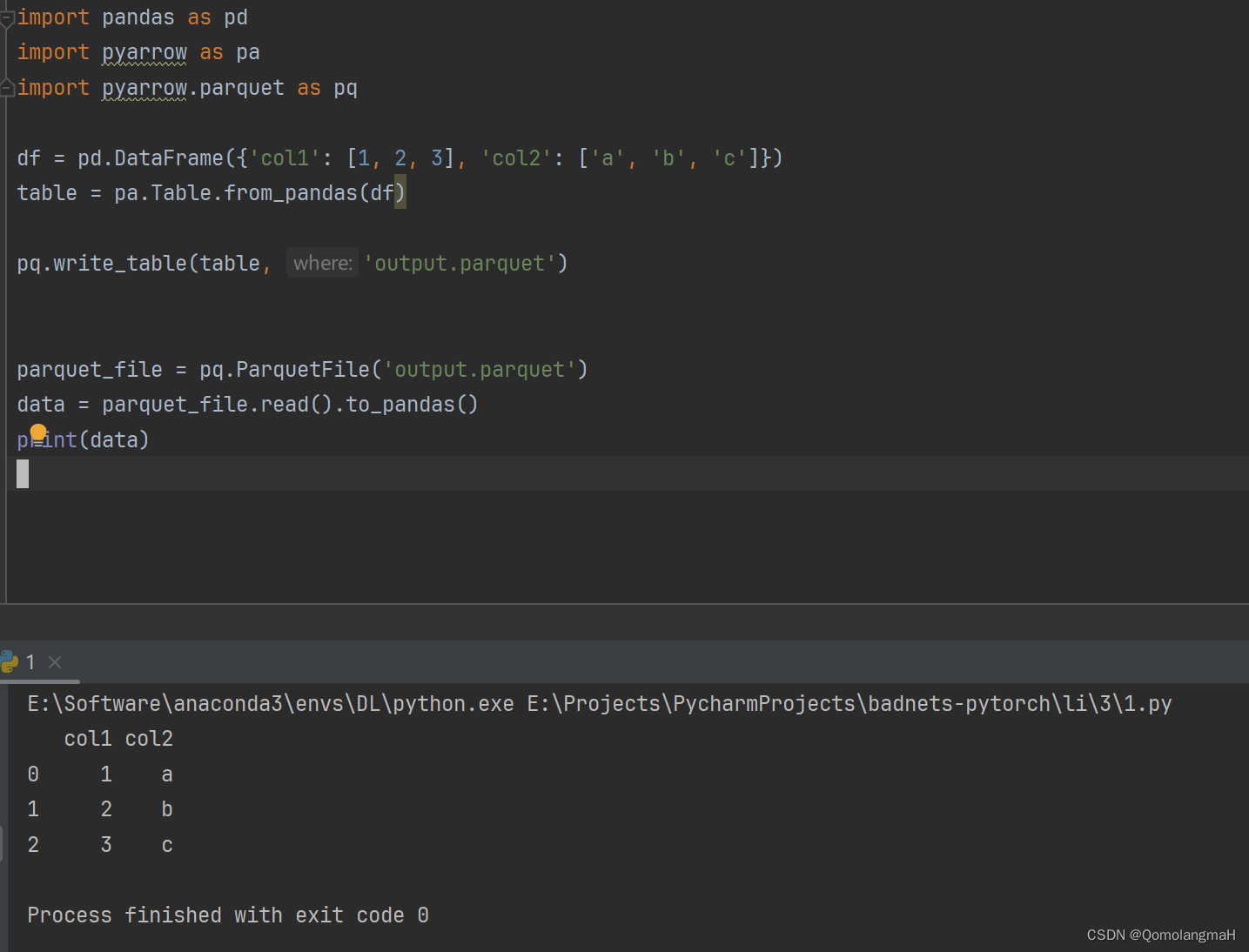
3. 对数据进行操作
import pyarrow.parquet as pq
# 读取Parquet文件
parquet_file = pq.ParquetFile('output.parquet')
data = parquet_file.read().to_pandas()
# 对数据进行筛选和转换
filtered_data = data[data['col1'] > 1] # 筛选出col1大于1的行
print(filtered_data)
transformed_data = filtered_data.assign(col3=filtered_data['col1'] * 2) # 添加一个新列col3,值为col1的两倍
# 打印处理后的数据
print(transformed_data)
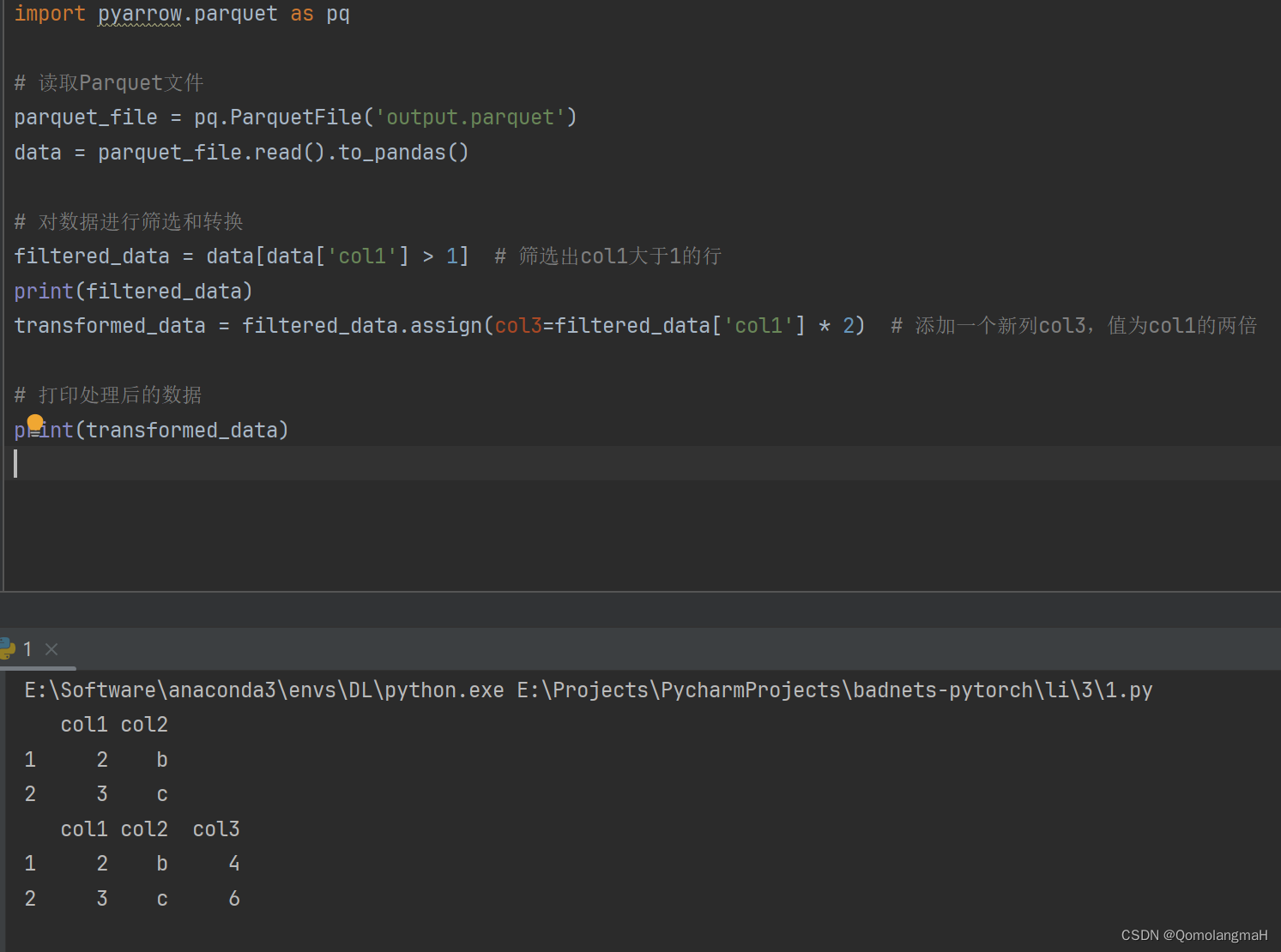
4. 导出数据为csv
import pyarrow.parquet as pq
import pandas as pd
parquet_file = pq.ParquetFile('output.parquet')
data = parquet_file.read().to_pandas()
df = pd.DataFrame(data)
csv_path = './data.csv'
df.to_csv(csv_path)
print(f'数据已保存到 {csv_path}')
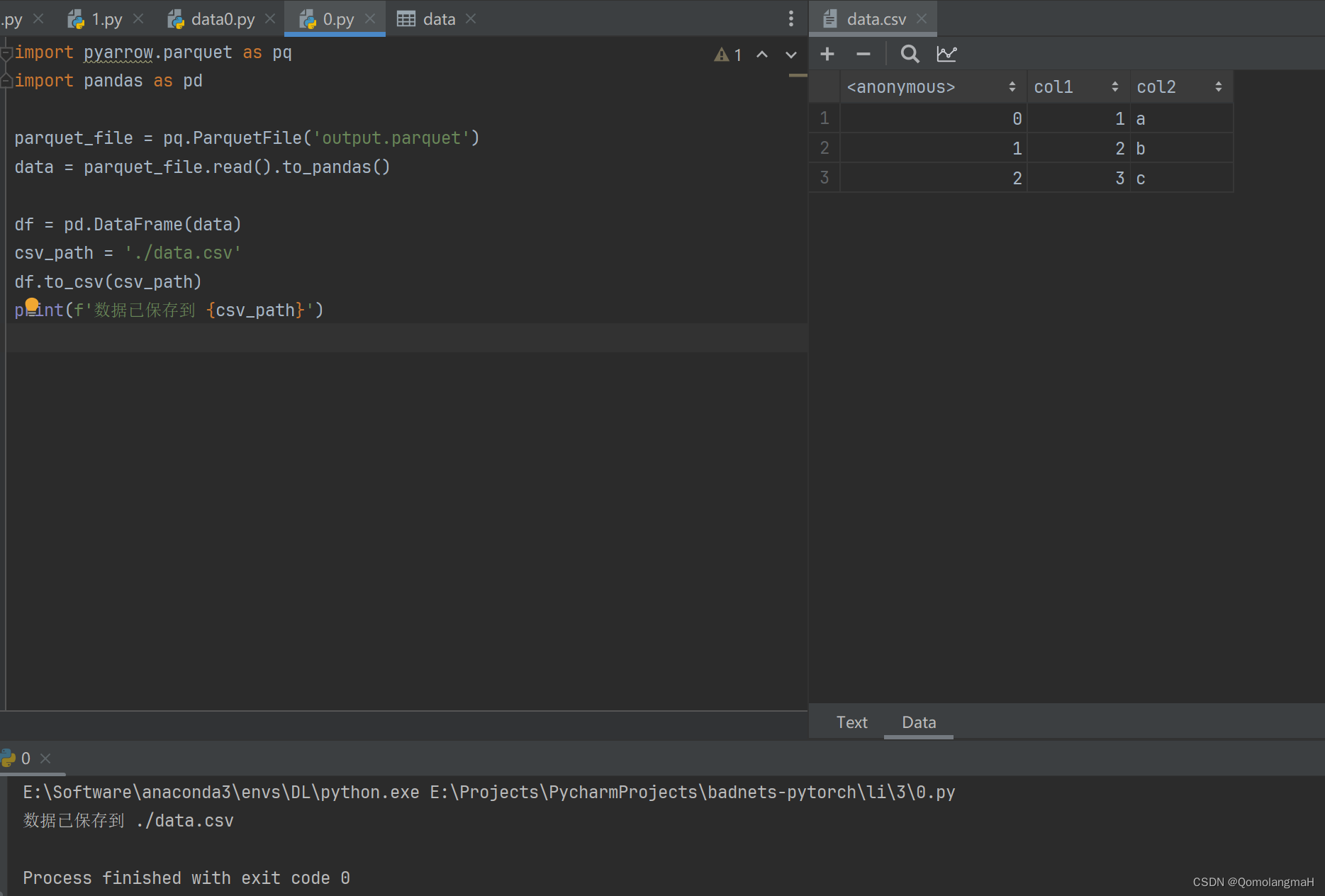
三、实战
1. 简单读取
import pyarrow.parquet as pq
import pandas as pd
parquet_file = pq.ParquetFile('./train_parquet/part-00014-918feee1-1ad5-4b08-8876-4364cc996930-c000.snappy.parquet')
data = parquet_file.read().to_pandas()
df = pd.DataFrame(data)
csv_path = './data2.csv'
df.to_csv(csv_path)
print(f'数据已保存到 {csv_path}')
关于PyCharm调试操作可参照:PyCharm基础调试功能详解
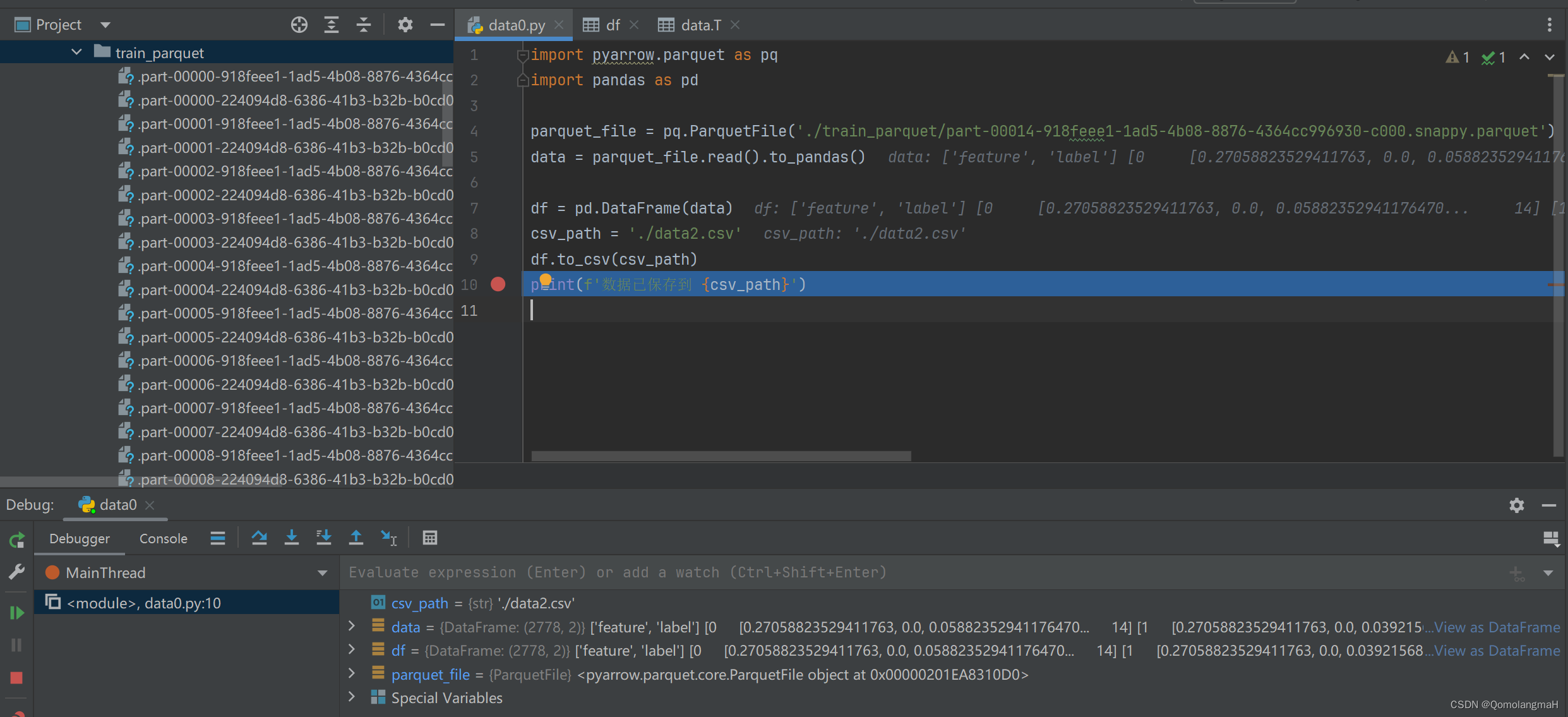
点击右侧蓝色的View as DataFrame
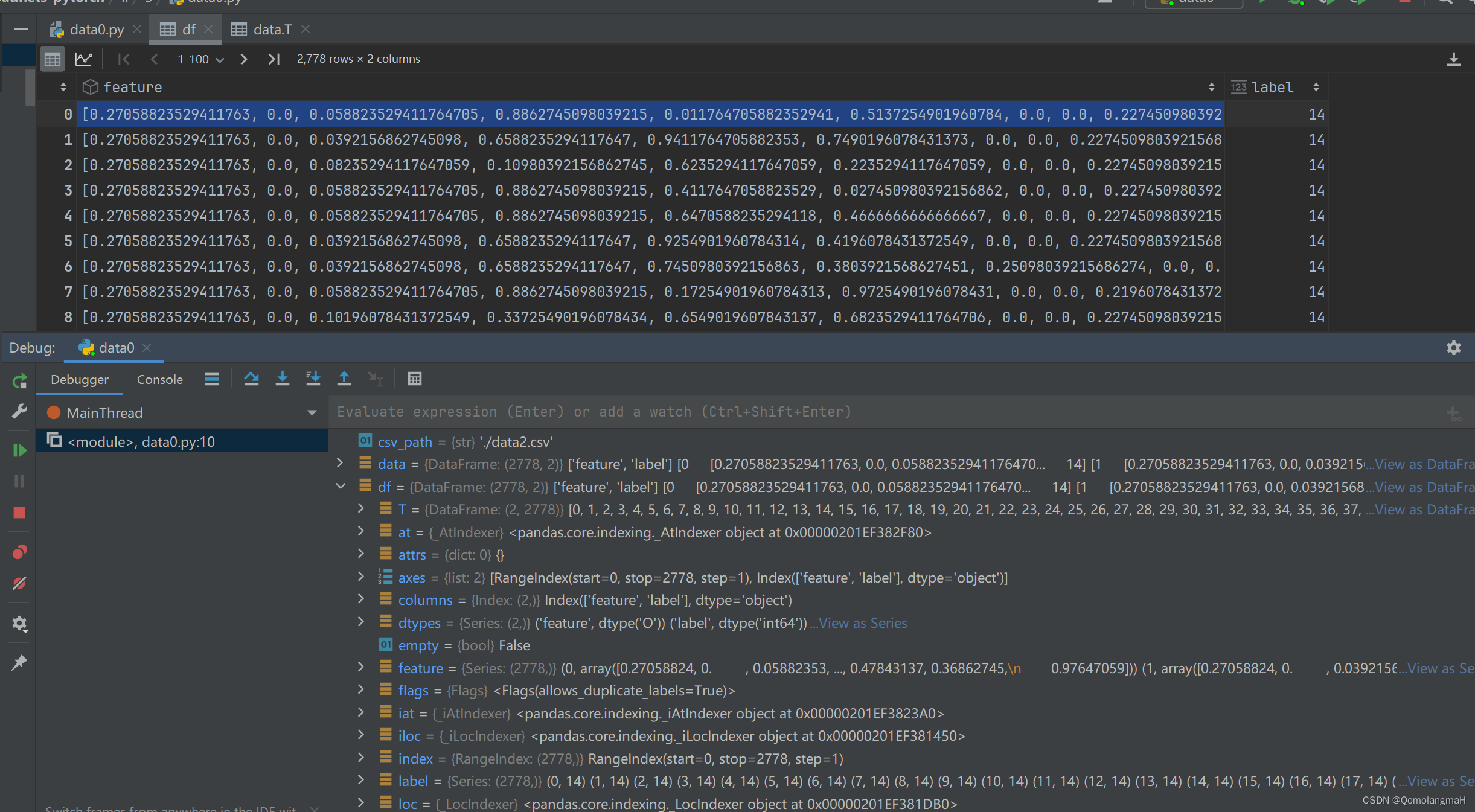
如图所示,feature在同一个格内,导出为:
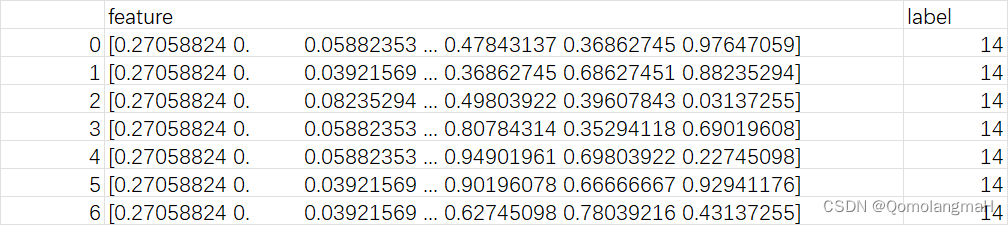
注意看,省略号...位置真的就是省略号字符,没有数字,即
[0.27058824 0. 0.05882353 ... 0.47843137 0.36862745 0.97647059]
2. 数据操作(分割feature)
import pyarrow.parquet as pq
import pandas as pd
parquet_file = pq.ParquetFile('./train_parquet/part-00014-918feee1-1ad5-4b08-8876-4364cc996930-c000.snappy.parquet')
data = parquet_file.read().to_pandas()
# 将feature列中的列表拆分成单独的特征值
split_features = data['feature'].apply(lambda x: pd.Series(x))
# 将拆分后的特征添加到DataFrame中
data = pd.concat([data, split_features], axis=1)
print(data.head(2))
# 删除原始的feature列
data = data.drop('feature', axis=1)
# 保存到csv文件
csv_path = './data1.csv'
data.to_csv(csv_path, index=False)
print(f'数据已保存到 {csv_path}')
- 调试打开:
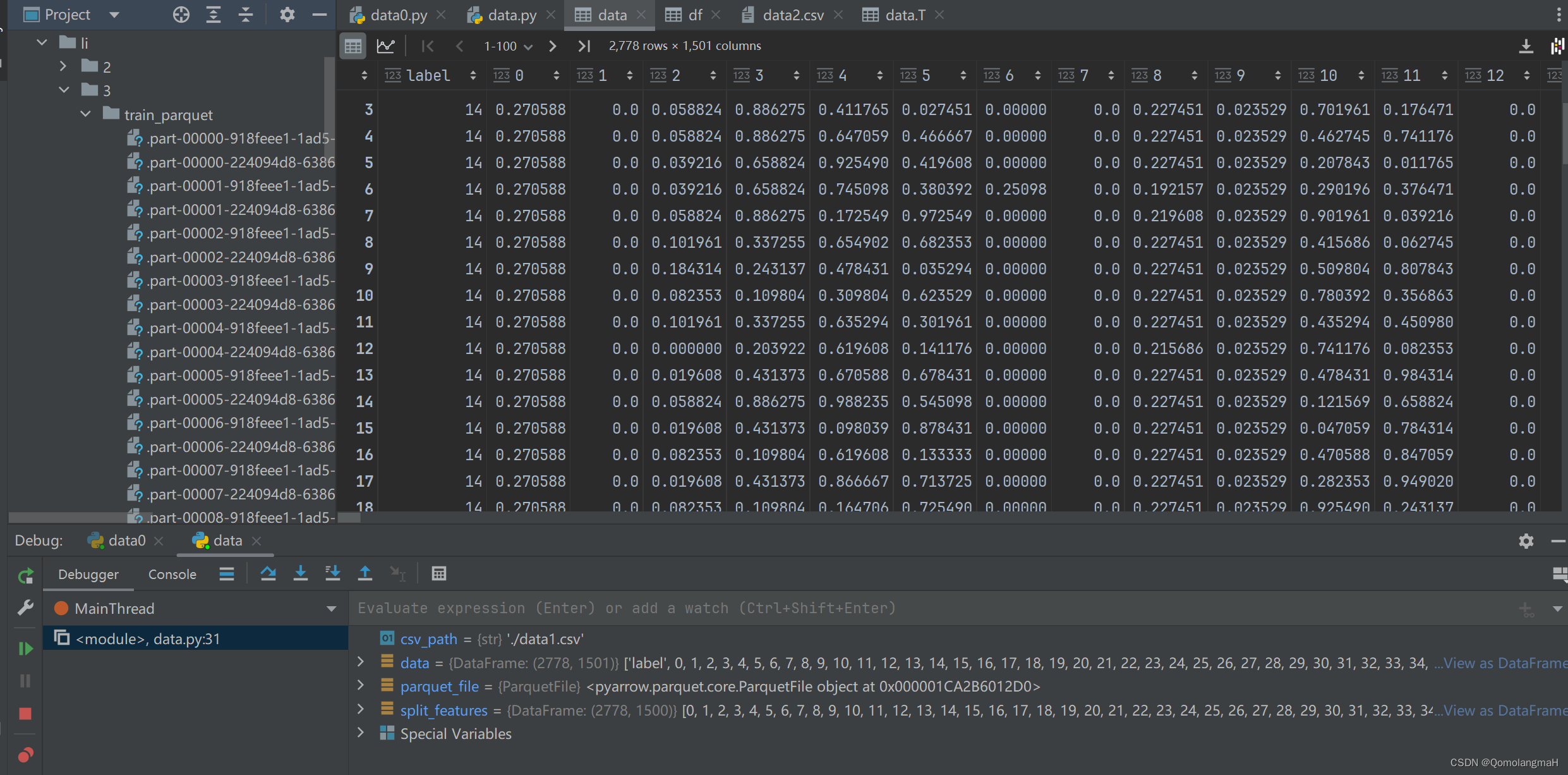
- excel打开:
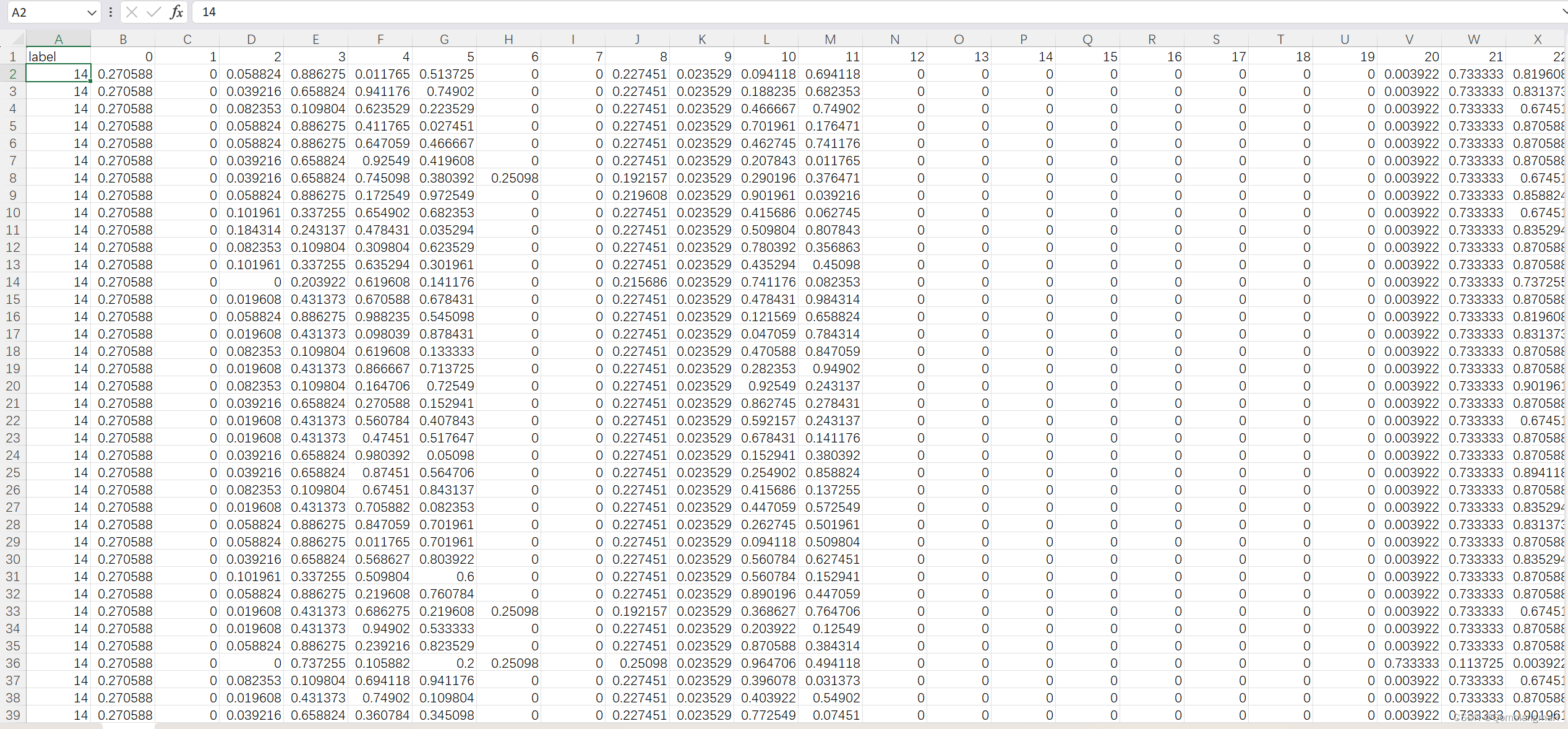
- 文件大小对比

部分内容援引自博客:使用python打开parquet文件
3. 迭代方式来处理Parquet文件
如果Parquet文件非常大,可能会占用大量的内存。在处理大型数据时,建议使用迭代的方式来处理Parquet文件,以减少内存的占用。以下是一种更加内存友好的方式来处理Parquet文件:
import pyarrow.parquet as pq
import pandas as pd
import time
start_time = time.time() # 记录开始时间
# 使用迭代器迭代读取Parquet文件中的数据
data_iterator = pq.ParquetFile(
'./train_parquet/part-00014-918feee1-1ad5-4b08-8876-4364cc996930-c000.snappy.parquet').iter_batches(batch_size=100)
# 初始化空的DataFrame用于存储数据
data = pd.DataFrame()
# 逐批读取数据并进行处理
for batch in data_iterator:
# 将RecordBatch转换为Pandas DataFrame
df_batch = batch.to_pandas()
# 将feature列中的列表拆分成单独的特征值
split_features = df_batch['feature'].apply(lambda x: pd.Series(x))
# 将拆分后的特征添加到DataFrame中
df_batch = pd.concat([df_batch, split_features], axis=1)
# 将处理后的数据追加到DataFrame中
data = data._append(df_batch, ignore_index=True)
# 删除原始的feature列
data = data.drop('feature', axis=1)
# 保存到csv文件
csv_path = './data3.csv'
data.to_csv(csv_path, index=False)
end_time = time.time() # 记录结束时间
print(f'数据已保存到 {csv_path}')
print(f'总运行时间: {end_time - start_time} 秒')
输出:
数据已保存到 ./data3.csv
总运行时间: 4.251184940338135 秒
4. 读取同一文件夹下多个parquet文件
import os
import pyarrow.parquet as pq
import pandas as pd
import time
start_time = time.time() # 记录开始时间
folder_path = './train_parquet/'
parquet_files = [f for f in os.listdir(folder_path) if f.endswith('.parquet')]
# 初始化空的DataFrame用于存储数据
data = pd.DataFrame()
# 逐个读取Parquet文件中的数据并进行处理
for file in parquet_files:
file_path = os.path.join(folder_path, file)
data_iterator = pq.ParquetFile(file_path).iter_batches(batch_size=1024)
for batch in data_iterator:
# 将RecordBatch转换为Pandas DataFrame
df_batch = batch.to_pandas()
# 将feature列中的列表拆分成单独的特征值
split_features = df_batch['feature'].apply(lambda x: pd.Series(x))
# 将拆分后的特征添加到DataFrame中
df_batch = pd.concat([df_batch, split_features], axis=1)
# 将处理后的数据追加到DataFrame中
data = data._append(df_batch, ignore_index=True)
# 删除原始的feature列
data = data.drop('feature', axis=1)
# 保存到csv文件
csv_path = './data.csv'
data.to_csv(csv_path, index=False)
end_time = time.time() # 记录结束时间
print(f'数据已保存到 {csv_path}')
print(f'总运行时间: {end_time - start_time} 秒')
版权声明:本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若内容造成侵权/违法违规/事实不符,请联系邮箱:jacktools123@163.com进行投诉反馈,一经查实,立即删除!
标签:
相关文章
最新发布
- 光流法结合深度学习神经网络的原理及应用(完整代码都有Python opencv)
- Python 图像处理进阶:特征提取与图像分类
- 大数据可视化分析-基于python的电影数据分析及可视化系统_9532dr50
- 【Python】入门(运算、输出、数据类型)
- 【Python】第一弹---解锁编程新世界:深入理解计算机基础与Python入门指南
- 华为OD机试E卷 --第k个排列 --24年OD统一考试(Java & JS & Python & C & C++)
- Python已安装包在import时报错未找到的解决方法
- 【Python】自动化神器PyAutoGUI —告别手动操作,一键模拟鼠标键盘,玩转微信及各种软件自动化
- Pycharm连接SQL Sever(详细教程)
- Python编程练习题及解析(49题)
点击排行
- 版本匹配指南:Numpy版本和Python版本的对应关系
- 版本匹配指南:PyTorch版本、torchvision 版本和Python版本的对应关系
- Anaconda版本和Python版本对应关系(持续更新...)
- 相关性分析——Pearson相关系数+热力图(附data和Python完整代码)
- Python 可视化 web 神器:streamlit、Gradio、dash、nicegui;低代码 Python Web 框架:PyWebIO
- Windows上安装 Python 环境并配置环境变量 (超详细教程)
- Python与PyTorch的版本对应
- 安装spacy+zh_core_web_sm避坑指南
本站推荐
