首页 > Python资料 博客日记
保姆级随机森林算法Python教学
2024-05-09 21:00:05Python资料围观255次
摘要
机器学习算法是数据挖掘、数据能力分析和数学建模必不可少的一部分,而随机森林算法和决策树算法是其中较为常用的两种算法,本文将会对随机森林算法的Python实现进行保姆级教学。
0 绪论
数据挖掘和数学建模等比赛中,除了算法的实现,还需要对数据进行较为合理的预处理,包括缺失值处理、异常值处理、特征值的特征编码等等,本文默认读者的数据均已完成数据预处理,如有需要,后续会将数据预处理的方法也进行发布。
一、材料准备
Python编译器: Pycharm社区版或个人版等
训练数据集: 此处使用2022年数维杯国际大学生数学建模竞赛C题的附件数据为例。
数据处理: 经过初步数据清洗和相关性分析得到初步的特征,并利用决策树进行特征重要性分析,完成二次特征降维,得到’CDRSB_bl’, ‘PIB_bl’, 'FBB_bl’三个自变量特征,DX_bl为分类特征。
二、算法原理
随机森林算法是一种机器学习算法,它通过构建多棵决策树并将它们的预测结果结合起来来预测目标变量。
随机森林是一种典型的Bagging模型,是基于多种决策树的分类智能算法。首先,在处理后的数据集中进行随机抽样,形成n种不同的样本数据集。
然后,根据数据集构建不同的决策树模型,再将测试集代入决策树中,得到分类结果,最后通过投票进行预测分类,具体的流程图如下图1所示:
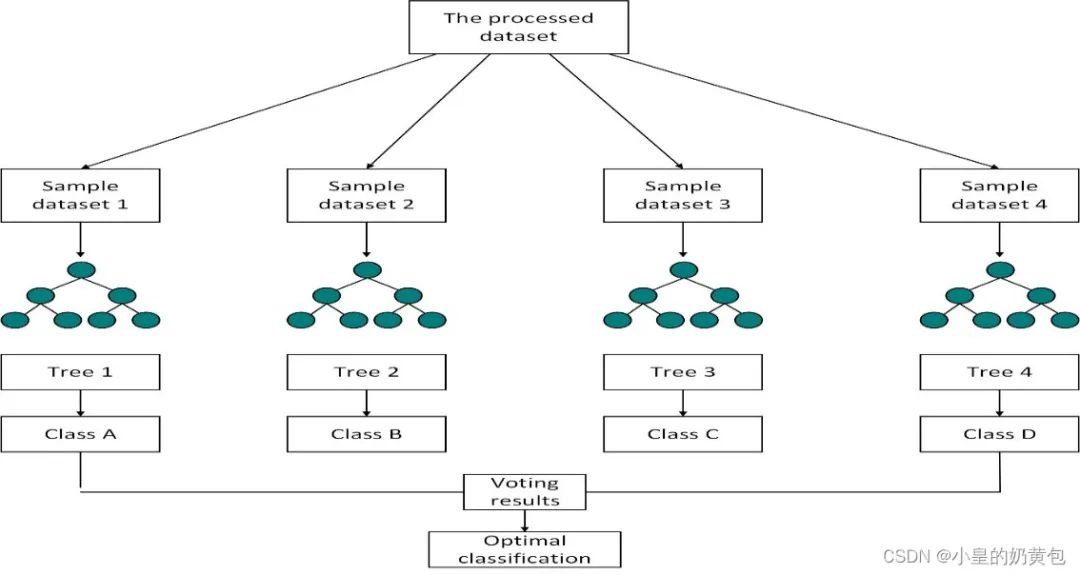
Figure 1 随机森林分类流程图
三、算法Python实现
3.1 数据加载
import pandas as pd
# 加载数据
X = pd.DataFrame(pd.read_excel('DataX.xlsx')).values # 输入特征
y = pd.DataFrame(pd.read_excel('DataY.xlsx')).values # 目标变量
此处将自变量存放在DataX中,因变量存放在DataY中,如需进行样本预测,可另存一个文件(格式与DataX一致),在后文predict中进行替换。
3.2 创建随机森林分类器
from sklearn.ensemble import RandomForestClassifier
# 创建随机森林分类器
clf = RandomForestClassifier(n_estimators=100)
本文将迭代次数设为100
3.3 创建ShuffleSplit对象,用于执行自动洗牌
from sklearn.model_selection import ShuffleSplit
# 创建ShuffleSplit对象,用于执行自动洗牌
ss = ShuffleSplit(n_splits=1, train_size=0.7, test_size=0.3, random_state=0)
此处使用70%的样本数据作为训练集,30%的样本数据作为测试集,如果在国际比赛中,可通过调整其测试训练比,来进行模型的敏感性和稳定性分析。
3.4 循环遍历每个拆分,并使用随机森林分类器对每个拆分进行训练和评估
from sklearn.metrics import confusion_matrix, classification_report, accuracy_score
# 循环遍历每个拆分,并使用随机森林分类器对每个拆分进行训练和评估
for train_index, test_index in ss.split(X, y):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print("Confusion Matrix:")
print(confusion_matrix(y_test, y_pred)) # 输出分类结果矩阵
print("Classification Report:")
print(classification_report(y_test, y_pred)) # 输出混淆矩阵
print("Accuracy:")
print(accuracy_score(y_test, y_pred))
print(clf.predict(X_train)) # 此处用作预测,预测数据可以用另一个文件导入,格式与DataX相同
print(clf.score(X_test, y_test))
一个分类器的好坏、是否适用,离不开模型的评估,常用的方法就是混淆矩阵和F1-Score,博主建议直接使用F1-Score即可,如果时间充足,可以使用多种机器学习算法的对比,说明你选择随机森林或者其他机器学习算法的原因,这是加分项。
此处将结果矩阵、分类的准确性、F1-Score值均输出,可适当采用,建议弄成表格放进论文里。
3.5 计算特征重要性
# 计算特征重要性
importances = clf.feature_importances_
print(importances)
如何判断选择的特征是否需要再次降维,得到的特征重要性非常低,即说明这个指标在该算法分类中不起明显作用,可将该特征进行删除。
3.6 将特征重要性可视化
import matplotlib.pyplot as plt
# 画条形图
plt.barh(range(len(importances)), importances)
# 添加标题
plt.title("Feature Importances")
feature_names = ['CDRSB_bl', 'PIB_bl', 'FBB_bl']
# 添加特征名称
plt.yticks(range(len(importances)), feature_names)
# 显示图像
# plt.show()
plt.savefig('feature_importance.png')
对特征重要性进行可视化,可以提高论文的辨识度,也算是加分项,比单纯弄成表格的要好。
3.7 生成决策树可视化图形
from sklearn.tree import export_graphviz
import graphviz
# 使用 export_graphviz 函数将决策树保存为 dot 文件
dot_data = export_graphviz(clf.estimators_[0], out_file=None,
feature_names=['CDRSB_bl', 'PIB_bl',
'FBB_bl'])
# 使用 graphviz 库读取 dot 文件并生成决策树可视化图形
graph = graphviz.Source(dot_data)
graph.render('decision_tree')
这里将随机森林的算法过程进行可视化,一般来说很长,图片不美观,可以不放进论文里,简单说明即可。
3.8 完整实现代码
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import confusion_matrix, classification_report, accuracy_score
from sklearn.model_selection import ShuffleSplit
import pandas as pd
from sklearn.tree import export_graphviz
import graphviz
import matplotlib.pyplot as plt
# 加载数据
X = pd.DataFrame(pd.read_excel('DataX.xlsx')).values # 输入特征
y = pd.DataFrame(pd.read_excel('DataY.xlsx')).values # 目标变量
# 创建随机森林分类器
clf = RandomForestClassifier(n_estimators=100)
# 创建ShuffleSplit对象,用于执行自动洗牌
ss = ShuffleSplit(n_splits=1, train_size=0.7, test_size=0.3, random_state=0)
# 循环遍历每个拆分,并使用随机森林分类器对每个拆分进行训练和评估
for train_index, test_index in ss.split(X, y):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print("Confusion Matrix:")
print(confusion_matrix(y_test, y_pred)) # 输出分类结果矩阵
print("Classification Report:")
print(classification_report(y_test, y_pred)) # 输出混淆矩阵
print("Accuracy:")
print(accuracy_score(y_test, y_pred))
print(clf.predict(X_train)) # 此处用作预测,预测数据可以用另一个文件导入,格式与DataX相同
print(clf.score(X_test, y_test))
importances = clf.feature_importances_ # 计算特征重要性
print(importances)
# 画条形图
plt.barh(range(len(importances)), importances)
# 添加标题
plt.title("Feature Importances")
feature_names = ['CDRSB_bl', 'PIB_bl', 'FBB_bl']
# 添加特征名称
plt.yticks(range(len(importances)), feature_names)
# 显示图像
# plt.show()
plt.savefig('feature_importance.png')
# 使用 export_graphviz 函数将决策树保存为 dot 文件
dot_data = export_graphviz(clf.estimators_[0], out_file=None,
feature_names=['CDRSB_bl', 'PIB_bl',
'FBB_bl'])
# 使用 graphviz 库读取 dot 文件并生成决策树可视化图形
graph = graphviz.Source(dot_data)
graph.render('decision_tree')
四、 结论
对随机森林进行Python的实现,并计算了结果矩阵、评估矩阵和准确率,可支持对模型的准确性、适用性、敏感性和稳定性进行分析。
并通过对特征重要性和随机森林算法实现过程的可视化,很好地完成了一趟完整的随机森林算法的演示。
感兴趣的小伙伴,赠送全套Python学习资料,包含面试题、简历资料等具体看下方。

一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、Python必备开发工具
工具都帮大家整理好了,安装就可直接上手!
三、最新Python学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。

四、Python视频合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

六、面试宝典


简历模板
 若有侵权,请联系删除
若有侵权,请联系删除
标签:
相关文章
最新发布
- 光流法结合深度学习神经网络的原理及应用(完整代码都有Python opencv)
- Python 图像处理进阶:特征提取与图像分类
- 大数据可视化分析-基于python的电影数据分析及可视化系统_9532dr50
- 【Python】入门(运算、输出、数据类型)
- 【Python】第一弹---解锁编程新世界:深入理解计算机基础与Python入门指南
- 华为OD机试E卷 --第k个排列 --24年OD统一考试(Java & JS & Python & C & C++)
- Python已安装包在import时报错未找到的解决方法
- 【Python】自动化神器PyAutoGUI —告别手动操作,一键模拟鼠标键盘,玩转微信及各种软件自动化
- Pycharm连接SQL Sever(详细教程)
- Python编程练习题及解析(49题)
点击排行
- 版本匹配指南:Numpy版本和Python版本的对应关系
- 版本匹配指南:PyTorch版本、torchvision 版本和Python版本的对应关系
- Anaconda版本和Python版本对应关系(持续更新...)
- 相关性分析——Pearson相关系数+热力图(附data和Python完整代码)
- Python 可视化 web 神器:streamlit、Gradio、dash、nicegui;低代码 Python Web 框架:PyWebIO
- Windows上安装 Python 环境并配置环境变量 (超详细教程)
- Python与PyTorch的版本对应
- 安装spacy+zh_core_web_sm避坑指南
本站推荐
