首页 > Python资料 博客日记
【python】python二手房数据抓取分析可视化(源码)【独一无二】
2024-06-29 15:00:04Python资料围观201次
Python资料网推荐【python】python二手房数据抓取分析可视化(源码)【独一无二】这篇文章给大家,欢迎收藏Python资料网享受知识的乐趣
👉博__主👈:米码收割机
👉技__能👈:C++/Python语言
👉公众号👈:测试开发自动化【获取源码+商业合作】
👉荣__誉👈:阿里云博客专家博主、51CTO技术博主
👉专__注👈:专注主流机器人、人工智能等相关领域的开发、测试技术。

python二手房数据抓取分析可视化(源码)
一、功能描述
代码是一个爬虫程序,旨在抓取链家网站 上的二手房数据,并进行数据处理和可视化展示。
-
爬取数据:使用
requests库向链家网站发送HTTP请求,获取网页的HTML内容,然后使用lxml库解析HTML,提取出房屋的标题、价格、地段、面积和户型等信息。 -
数据存储:将爬取的房屋数据存储到CSV文件中,方便后续的数据处理和分析。
-
数据清洗:对爬取的数据进行清洗,去除空格行和不规范的数据,并将清洗后的数据写回CSV文件。
-
数据统计与可视化:
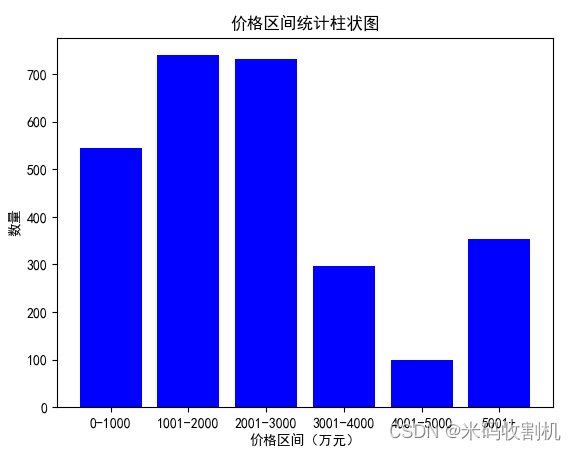
- 价格区间统计柱状图:将房屋价格分组到不同的价格区间,并统计每个价格区间的房屋数量,然后使用matplotlib库绘制柱状图进行可视化展示。
- 面积筛选:筛选出面积大于100平方米的房屋,并将结果保存到新的CSV文件中。
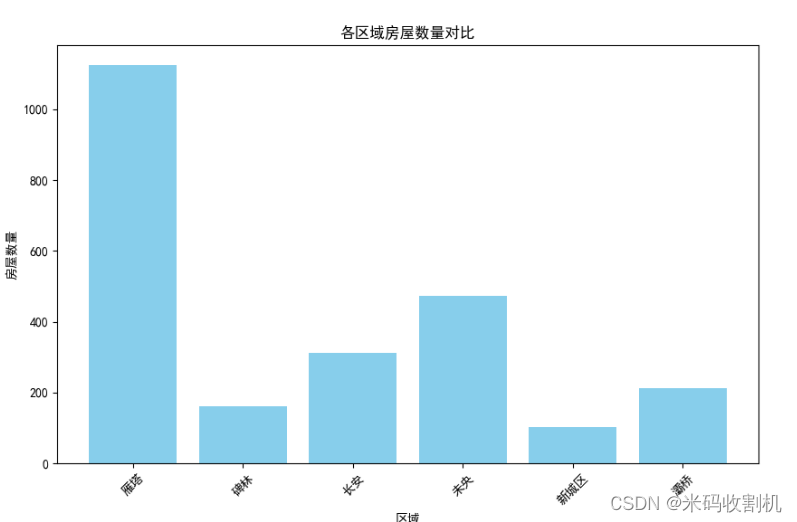
- 区域房屋数量统计:统计各个区域的房屋数量,并使用柱状图和饼图进行可视化展示,以便比较各个区域的房屋数量占比。
通过这些功能,用户可以快速获取链家网站上的二手房数据,并进行数据分析和可视化,帮助他们更好地了解房屋市场的情况和趋势。
👇👇👇 关注公众号,回复 “链家爬虫” 获取源码👇👇👇
二、数据抓取展示

存储内容如下:
👇👇👇 关注公众号,回复 “链家爬虫” 获取源码👇👇👇

三、数据可视化分析
价格区间分析
👇👇👇 关注公众号,回复 “链家爬虫” 获取源码👇👇👇
各区域房屋数量对比分析
各区房屋数量占比

👇👇👇 关注公众号,回复 “链家爬虫” 获取源码👇👇👇
部分代码展示
import requests
import matplotlib.pyplot as plt
import pandas as pd
plt.rcParams['font.sans-serif'] = ['SimHei']
def write_csv(csv_file_path):
with open('data.csv', 'a+', newline='') as csvfile:
csv_writer = csv.writer(csvfile)
csv_writer.writerow(csv_file_path)
# 爬虫部分代码(略...)👇👇👇 关注公众号,回复 “链家爬虫” 获取源码👇👇👇
# 爬虫部分代码(略...)👇👇👇 关注公众号,回复 “链家爬虫” 获取源码👇👇👇
# 读取数据
csv_file_path = 'new_data.csv'
df = pd.read_csv(csv_file_path, encoding='gbk')
# 数据清洗部分代码(略...) 👇👇👇 关注公众号,回复 “链家爬虫” 获取源码👇👇👇
# 数据清洗部分代码(略...) 👇👇👇 关注公众号,回复 “链家爬虫” 获取源码👇👇👇
# 定义价格区间
price_bins = [0, 1000, 2000, 3000, 4000, 5000, math.inf]
price_labels = ['0-1000', '1001-2000', '2001-3000', '3001-4000', '4001-5000', '5001+']
# 将价格分组到价格区间
df['Price Range'] = pd.cut(df['价格'], bins=price_bins, labels=price_labels, right=False)
# 统计每个价格区间的数量
price_counts = df['Price Range'].value_counts().sort_index()
# 绘制柱状图
plt.bar(price_counts.index, price_counts.values, color='blue')
plt.xlabel('价格区间(万元)')
plt.ylabel('数量')
plt.title('价格区间统计柱状图')
plt.show()
# 面积筛选
# 读取CSV文件
csv_file_path = 'new_data.csv'
df = pd.read_csv(csv_file_path, encoding='gbk')
# 将'面积'列转换为数值型,忽略无法转换的值
df['面积'] = pd.to_numeric(df['面积'], errors='coerce')
# 筛选出面积大于100的房子
filtered_df = df[df['面积'] > 100]
print(filtered_df)
# 保存结果到area100.csv
filtered_df.to_csv('area100.csv')
print("已成功保存面积大于100的房子到 area100.csv 文件。")
# 占比统计
csv_file_path = 'new_data.csv'
df = pd.read_csv(csv_file_path, encoding='gbk')
# 区域名称
areas = ["雁塔", "碑林", "长安", "未央", "新城区", "灞桥"]
# 计算每个区域的房屋数量
counts = {area: 0 for area in areas}
for index, row in df.iterrows():
for area in areas:
if area in row['地段']:
counts[area] += 1
break # 假设每个记录只属于一个区域
# 柱状图
plt.figure(figsize=(10, 6))
# 略...
plt.xlabel('区域')
plt.ylabel('房屋数量')
plt.title('各区域房屋数量对比')
plt.xticks(rotation=45) # 旋转x轴标签,以便更清楚地显示
plt.show()
# 饼图
plt.figure(figsize=(8, 8))
# 略...
plt.title('各区域房屋数量占比')
plt.show()
👇👇👇 关注公众号,回复 “链家爬虫” 获取源码👇👇👇
版权声明:本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若内容造成侵权/违法违规/事实不符,请联系邮箱:jacktools123@163.com进行投诉反馈,一经查实,立即删除!
标签:
相关文章
最新发布
- 光流法结合深度学习神经网络的原理及应用(完整代码都有Python opencv)
- Python 图像处理进阶:特征提取与图像分类
- 大数据可视化分析-基于python的电影数据分析及可视化系统_9532dr50
- 【Python】入门(运算、输出、数据类型)
- 【Python】第一弹---解锁编程新世界:深入理解计算机基础与Python入门指南
- 华为OD机试E卷 --第k个排列 --24年OD统一考试(Java & JS & Python & C & C++)
- Python已安装包在import时报错未找到的解决方法
- 【Python】自动化神器PyAutoGUI —告别手动操作,一键模拟鼠标键盘,玩转微信及各种软件自动化
- Pycharm连接SQL Sever(详细教程)
- Python编程练习题及解析(49题)
点击排行
- 版本匹配指南:Numpy版本和Python版本的对应关系
- 版本匹配指南:PyTorch版本、torchvision 版本和Python版本的对应关系
- Anaconda版本和Python版本对应关系(持续更新...)
- 相关性分析——Pearson相关系数+热力图(附data和Python完整代码)
- Python 可视化 web 神器:streamlit、Gradio、dash、nicegui;低代码 Python Web 框架:PyWebIO
- Windows上安装 Python 环境并配置环境变量 (超详细教程)
- Python与PyTorch的版本对应
- 安装spacy+zh_core_web_sm避坑指南
本站推荐
