首页 > Python资料 博客日记
【Python从入门到进阶】54、使用Python轻松操作SQLite数据库
2024-08-04 07:00:05Python资料围观126次
一、引言
1、什么是SQLite
SQLite的起源可以追溯到2000年,由D. Richard Hipp(理查德·希普)所创建。作为一个独立的开发者,Hipp在寻找一个能够在嵌入式系统中使用的轻量级数据库时,发现现有的解决方案要么过于庞大,要么无法满足他的需求。因此,他决定自己开发一个简单、高效、可靠的数据库引擎,这就是SQLite的雏形。

SQLite的创始理念是提供一个无服务器的、零配置的、自给自足的数据库引擎,以解决嵌入式系统和移动设备的存储和查询问题。与传统的关系型数据库管理系统(RDBMS)不同,SQLite不需要独立的服务器进程,也不需要进行繁琐的配置和管理。它只需要一个数据库文件,就可以开始使用,极大地简化了数据库的使用和管理。
随着SQLite的不断发展,它逐渐成为了嵌入式系统和移动应用中的首选数据库。由于其小巧的体积、高效的性能和稳定的性能,SQLite被广泛应用于各种领域,如智能家居、医疗设备、移动设备、游戏等。同时,由于其开源免费的特性,SQLite也吸引了大量的开发者和用户,形成了一个庞大的社区。
在SQLite的发展过程中,Hipp一直致力于提高数据库的性能和稳定性,同时也不断扩展其功能。SQLite支持标准的SQL92语言,并且提供了丰富的API接口,使得开发者可以轻松地与数据库进行交互。此外,SQLite还支持事务处理、并发访问、索引、触发器等多种高级特性,为开发者提供了更加灵活和强大的数据存储和查询能力。
2、为什么Python是操作SQLite的理想选择
SQLite以其小巧的体积和出色的性能,成为了开发者们的得力助手。无论是快速搭建一个原型系统,还是作为移动应用的数据存储后端,SQLite都能提供稳定可靠的数据支持。而且,由于其开源免费的特性,SQLite得到了广大开发者的青睐。
Python作为一种流行的高级编程语言,凭借其简洁的语法、丰富的库和强大的扩展性,成为了众多开发者的首选。而Python内置的sqlite3模块,则为我们提供了与SQLite数据库交互的便利。通过Python,我们可以轻松地连接到SQLite数据库,执行SQL语句,进行数据的增删改查等操作。
在本文中,我们将介绍如何使用Python操作SQLite数据库,包括连接数据库、创建和操作表、查询数据等基础知识,希望通过本文的介绍,读者能够掌握Python操作SQLite的基本技能,为日后的项目开发打下坚实的基础。
二、安装SQLite和Python的SQLite库
1、安装SQLite
SQLite不需要一个单独的服务器进程或操作系统级别的配置,因为它只是一个磁盘文件上的库,并且可以在多种编程语言中直接使用。
我们可以从SQLite的官方网站(https://www.sqlite.org/download.html)下载并安装。
在官网的【download】菜单下,找到“Precompiled Binaries for Windows”区域,下载相关版本(我这里是Windows的64位操作系统,所以选择x64版本):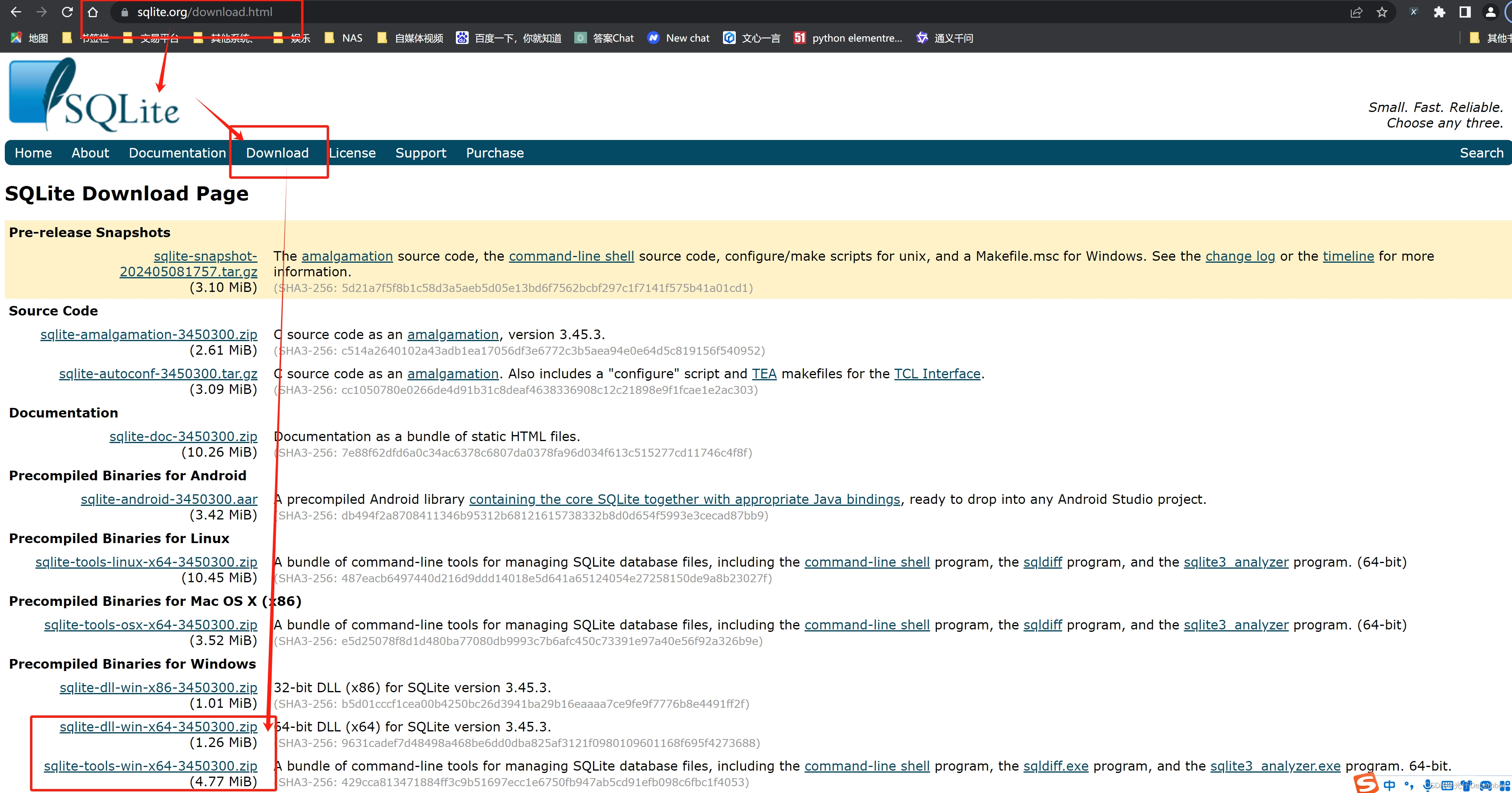
这里下载数据库和命令行工具两个压缩包
下载完毕之后,解压压缩包: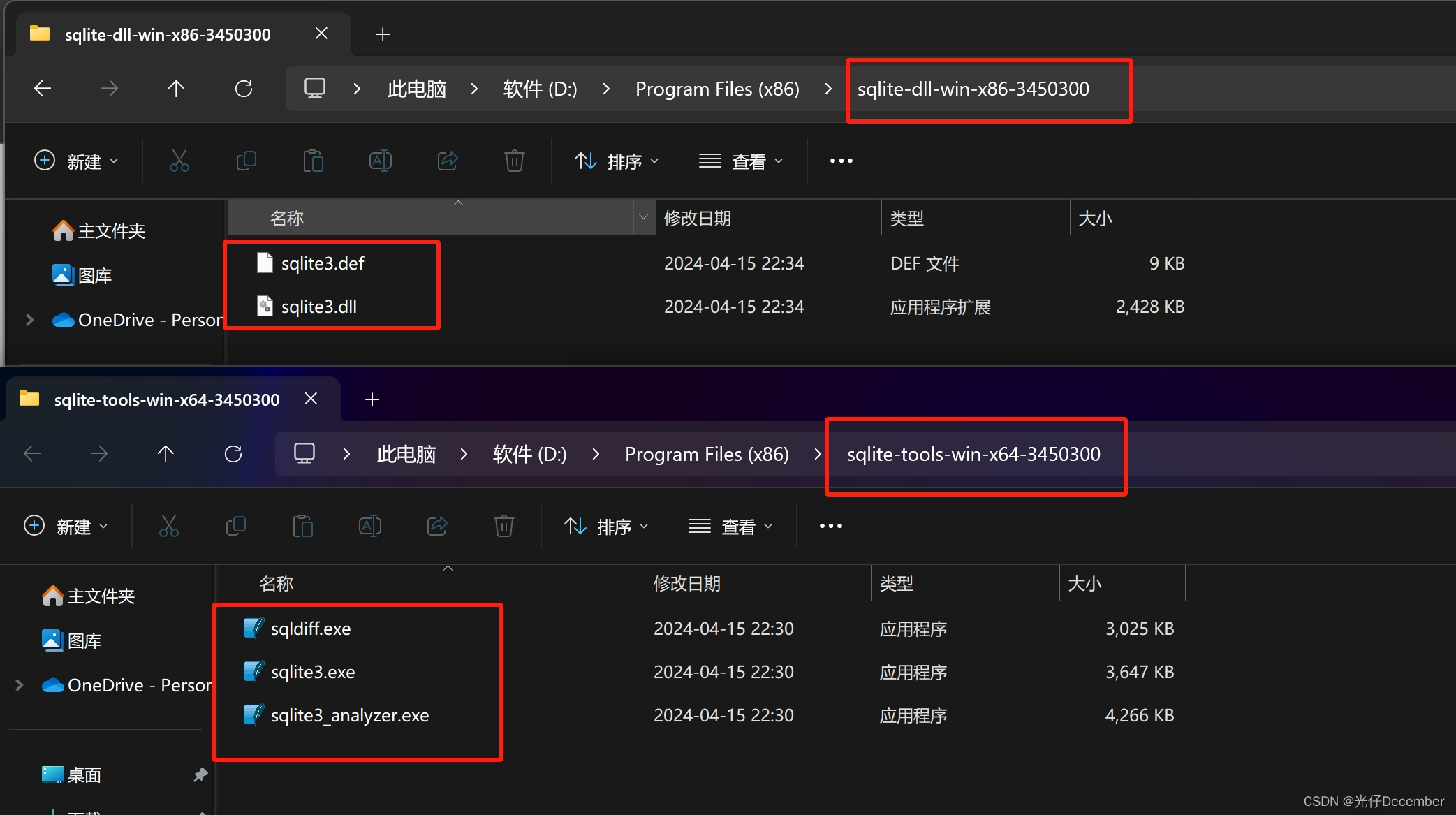
可以看到sqlite-dll-win-x64-3450300.zip里面只有两个文件,分别是“sqlite3.def”和“sqlite3.dll”。sqlite-tools-win-x64-3450300.zip中是一个“”文件,我们新建一个sqlite3文件夹,将这些文件放在一个文件夹中: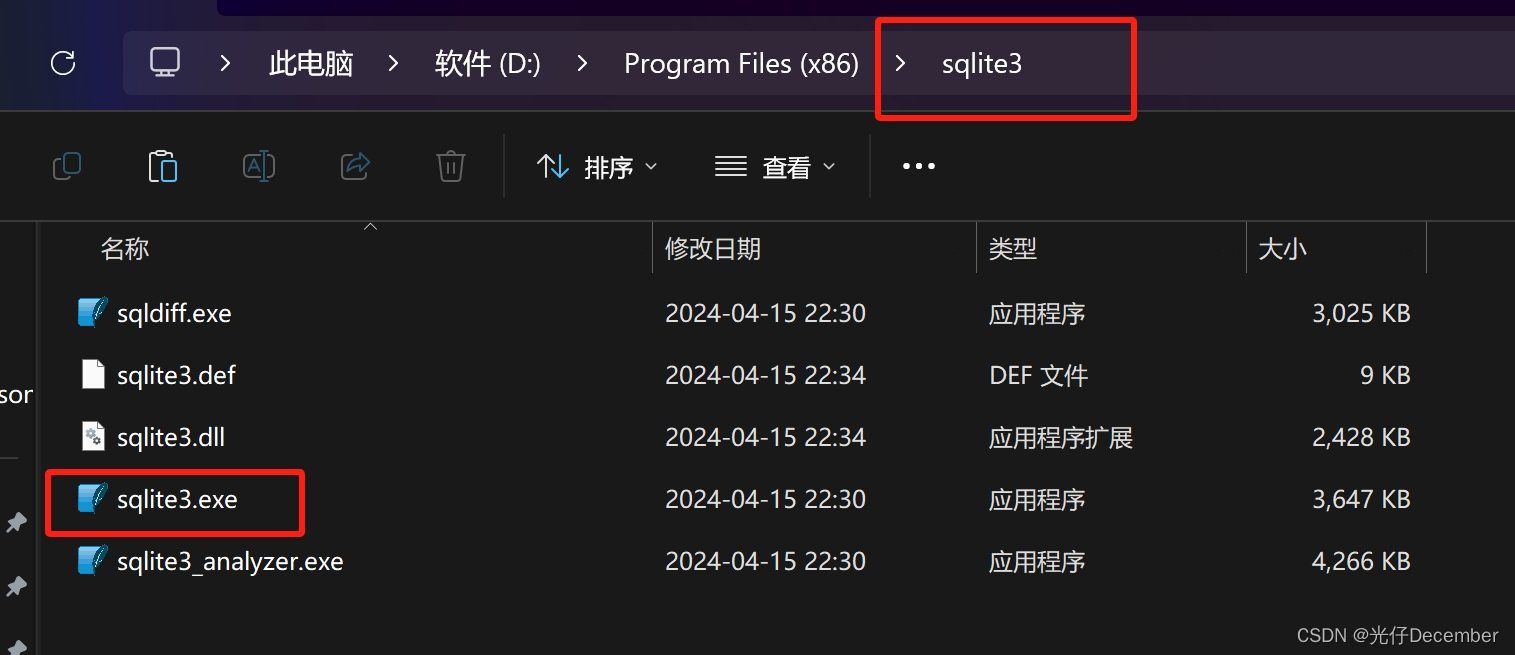
添加“D:\Program Files (x86)\sqlite3”到电脑的PATH环境变量:
最后在命令提示符下,使用sqlite3命令,将显示如下结果: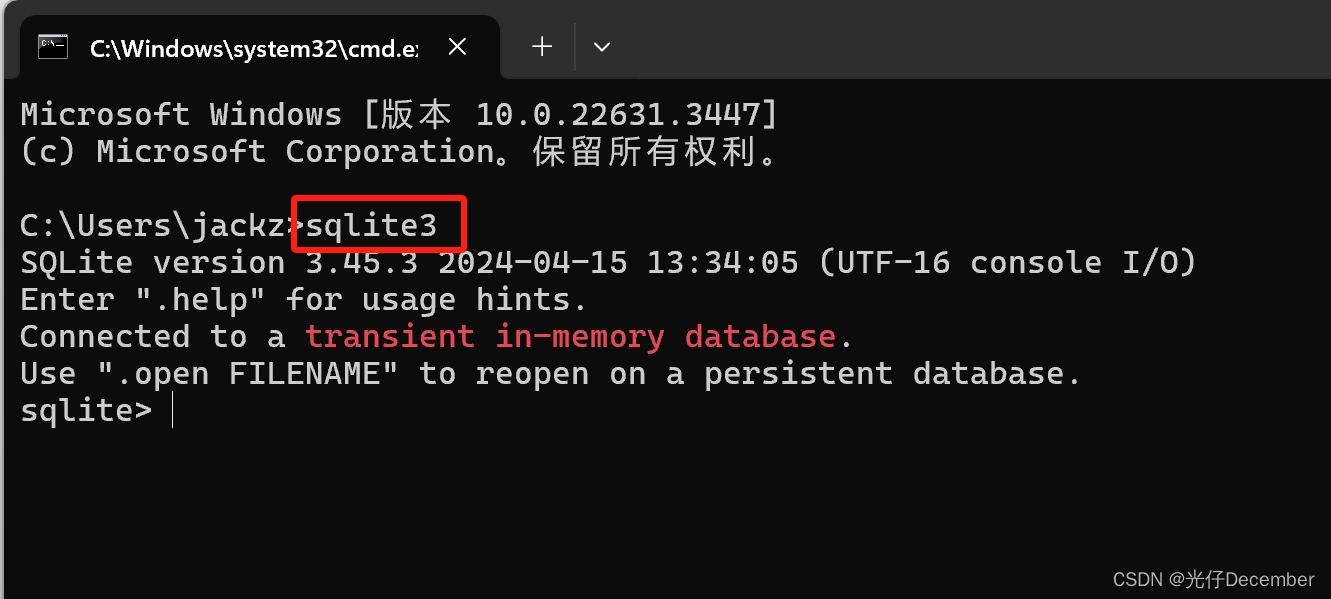
这就证明咱们的sqlite安装成功。
2、安装Python的SQLite库
对于Python来说,SQLite库(sqlite3)是内置的,这意味着咱们不需要额外安装任何包来使用它。从Python2.5开始,sqlite3模块就被包含在Python的标准库中。要验证你的Python环境中是否包含了sqlite3模块,可以打开Python解释器并尝试导入它:
import sqlite3
# 如果没有报错,说明sqlite3模块已经成功导入
print("sqlite3 module is available.")效果: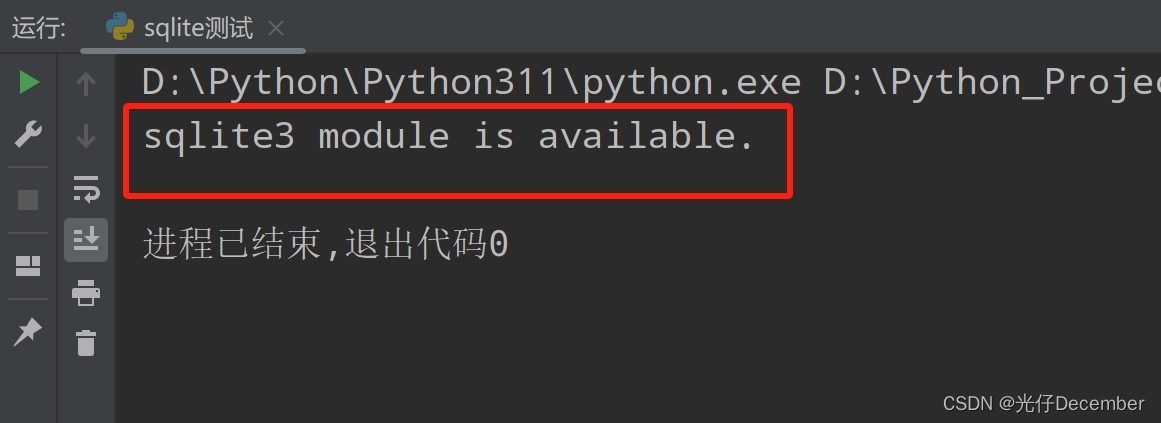
如果输出显示“sqlite3 module is available.”,那么你就可以开始使用Python来操作SQLite数据库了。如果你遇到任何导入错误,那么可能是因为你的Python环境有问题,或者你的Python版本太旧(低于2.5)。在这种情况下,需要更新Python环境或安装一个更新的版本。
三、连接到SQLite数据库
在Python中,我们可以使用内置的sqlite3模块来连接SQLite数据库。SQLite数据库文件实际上就是一个磁盘上的文件,通过这个文件,我们可以对数据进行存储、查询、更新和删除等操作。
1. 导入sqlite3模块
首先,我们需要在Python脚本中导入sqlite3模块。这个模块提供了与SQLite数据库交互的所有必要功能。
import sqlite32. 连接到SQLite数据库
然后,我们使用sqlite3.connect()函数来连接SQLite数据库。这个函数接受一个参数,即数据库文件的路径。如果指定的数据库文件不存在,SQLite会自动创建一个新的数据库文件。
# 连接到SQLite数据库文件,如果不存在则创建它
conn = sqlite3.connect('example.db')在上面的代码中,我们尝试连接到名为example.db的SQLite数据库文件。如果该文件不存在于指定的位置,SQLite将创建一个新的数据库文件。
3. 创建游标对象
在连接到数据库之后,我们需要创建一个游标(cursor)对象。游标对象用于执行SQL命令和获取查询结果。
# 创建一个游标对象
cursor = conn.cursor()4. 执行SQL命令
现在,我们可以使用游标对象来执行SQL命令了。例如,我们可以使用cursor.execute()方法创建一个新的表,或者向表中插入数据。
# 创建一个示例表
cursor.execute('''
CREATE TABLE IF NOT EXISTS users (
id INTEGER PRIMARY KEY,
name TEXT,
age INTEGER
)
''')
# 插入一条数据
cursor.execute("INSERT INTO users (name, age) VALUES (?, ?)", ("魏大勋", 30))在上面的代码中,我们首先使用CREATE TABLE语句创建了一个名为users的表(如果该表已经存在,则不会执行创建操作)。然后,我们使用INSERT INTO语句向表中插入了一条数据。注意,我们使用参数化查询来插入数据,这样可以防止SQL注入攻击。
5. 提交事务并关闭连接
在执行完SQL命令后,我们需要调用conn.commit()方法来提交事务,以确保数据被保存到数据库中。最后,我们使用conn.close()方法来关闭数据库连接。
# 提交事务
conn.commit()
# 关闭连接
conn.close()6. 完整的示例代码
下面是一个完整的示例代码,展示了如何连接到SQLite数据库、创建表、插入数据、提交事务并关闭连接:
import sqlite3
# 连接到SQLite数据库文件,如果不存在则创建它
conn = sqlite3.connect('example.db')
# 创建一个游标对象
cursor = conn.cursor()
# 创建一个示例表
cursor.execute('''
CREATE TABLE IF NOT EXISTS users (
id INTEGER PRIMARY KEY,
name TEXT,
age INTEGER
)
''')
# 插入一条数据
cursor.execute("INSERT INTO users (name, age) VALUES (?, ?)", ("魏大勋", 30))
# 提交事务
conn.commit()
# 关闭连接
conn.close()四、创建和操作SQLite表
在SQLite数据库中,表是存储数据的基本结构。通过表,我们可以定义数据的结构和关系。在Python中,我们可以使用sqlite3模块来创建和操作SQLite表。
1. 创建表
要创建一个新的表,我们需要使用CREATE TABLE语句,并通过游标对象执行该语句。下面是一个创建表的示例:
import sqlite3
# 连接到SQLite数据库(如果数据库不存在,会自动在当前目录创建)
conn = sqlite3.connect('test.db')
# 创建一个游标对象
cursor = conn.cursor()
# 创建一个名为users的表
create_table_sql = '''
CREATE TABLE IF NOT EXISTS users (
id INTEGER PRIMARY KEY AUTOINCREMENT,
name TEXT NOT NULL,
age INTEGER,
email TEXT UNIQUE
)
'''
cursor.execute(create_table_sql)
# 提交事务(在创建表时通常不需要,但在这里为了保持一致性)
conn.commit()
# 关闭游标和连接
cursor.close()
conn.close()在这个示例中,我们创建了一个名为users的表,它包含四个字段:id(作为主键并自动增长)、name(不能为空)、age(可以为空)和email(必须是唯一的)。
2. 插入数据
要向表中插入数据,我们可以使用INSERT INTO语句。下面是一个插入数据的示例:
import sqlite3
# 连接到SQLite数据库
conn = sqlite3.connect('test.db')
# 创建一个游标对象
cursor = conn.cursor()
# 插入一条数据
insert_sql = "INSERT INTO users (name, age, email) VALUES (?, ?, ?)"
data = ('魏大勋', 30, 'weidaxun@example.com')
cursor.execute(insert_sql, data)
# 提交事务
conn.commit()
# 关闭游标和连接
cursor.close()
conn.close()在这个示例中,我们使用参数化查询来插入数据,这不仅可以提高代码的可读性,还可以防止SQL注入攻击。
3. 查询数据
要从表中查询数据,我们可以使用SELECT语句。下面是一个查询数据的示例:
import sqlite3
# 连接到SQLite数据库
conn = sqlite3.connect('test.db')
# 创建一个游标对象
cursor = conn.cursor()
# 查询所有数据
query_sql = "SELECT * FROM users"
cursor.execute(query_sql)
# 获取查询结果
results = cursor.fetchall()
for row in results:
print(row)
# 关闭游标和连接
cursor.close()
conn.close()在这个示例中,我们使用fetchall()方法获取查询结果的所有行。我们还可以使用fetchone()方法逐行获取结果,或者使用fetchmany(size)方法一次获取多行结果。查询结果: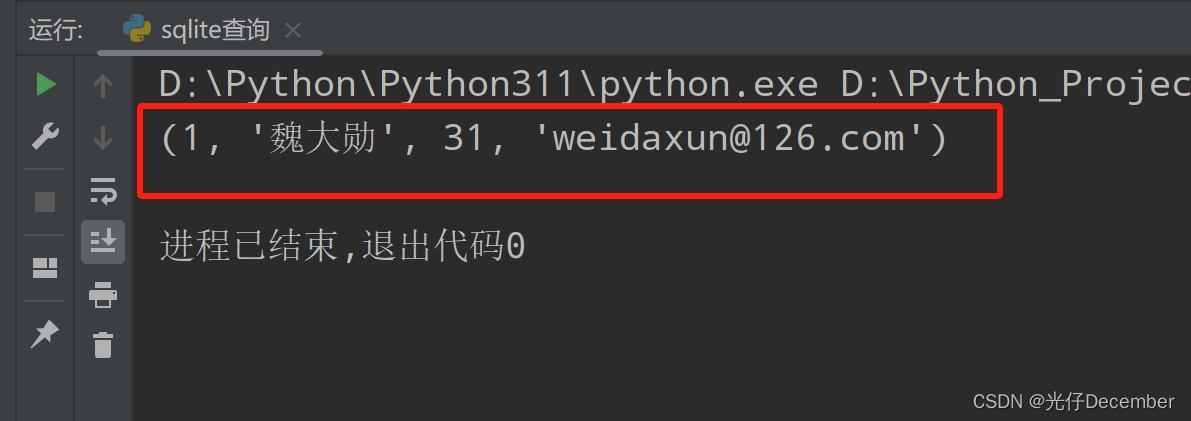
4. 更新数据
要更新表中的数据,我们可以使用UPDATE语句。下面是一个更新数据的示例:
import sqlite3
# 链接到SQLite数据库
conn = sqlite3.connect("test.db")
# 创建一个游标对象
cursor = conn.cursor()
# 查询更新前数据
query_sql = "select * from users where name = ?"
query_data = ("魏大勋",) # 就算只有一个值,也必须用元组包裹
cursor.execute(query_sql, query_data)
results = cursor.fetchall()
print("[更新前数据]:", results)
# 更新一条数据
update_sql = "update users set age = ? where name = ?"
update_data = (30, "魏大勋")
cursor.execute(update_sql, update_data)
# 提交事务
conn.commit()
# 查询更新后数据
cursor.execute(query_sql, query_data)
results = cursor.fetchall()
print("[更新后数据]:", results)
# 关闭游标和连接
cursor.close()
conn.close()在这个示例中,我们将名为'魏大勋'的用户的年龄更新为30。运行效果:
5. 删除数据
要从表中删除数据,我们可以使用DELETE语句。下面是一个删除数据的示例:
import sqlite3
# 连接到SQLite数据库
conn = sqlite3.connect('test.db')
# 创建一个游标对象
cursor = conn.cursor()
# 删除一条数据
delete_sql = "DELETE FROM users WHERE name = ?"
data = ('魏大勋',)
cursor.execute(delete_sql, data)
# 提交事务
conn.commit()
# 关闭游标和连接
cursor.close()
conn.close()在这个示例中,我们删除了名为'魏大勋'的用户。请注意,在执行删除操作时要特别小心,因为删除的数据将不可恢复。
五、使用Python的sqlite3模块高级功能
Python的sqlite3模块不仅提供了基本的数据库操作功能,如创建表、插入数据、查询数据等,还提供了一些高级功能,可以帮助我们更高效地管理和使用SQLite数据库。下面将介绍一些sqlite3模块的高级功能。
1. 参数化查询
参数化查询是一种防止SQL注入攻击的有效方法。在sqlite3中,我们可以使用问号(?)作为占位符,并将实际参数作为元组或列表传递给execute()方法。这样做不仅可以确保数据的安全性,还可以提高查询的性能。
import sqlite3
# 连接到SQLite数据库
conn = sqlite3.connect('test.db')
cursor = conn.cursor()
# 参数化查询
name = 'Alice'
query = "SELECT * FROM users WHERE name = ?"
cursor.execute(query, (name,))
results = cursor.fetchall()
for row in results:
print(row)
# 关闭游标和连接
cursor.close()
conn.close()2. 执行事务
在SQLite中,事务是一组作为单个逻辑单元执行的SQL语句。使用事务可以确保数据的一致性,即使在出现错误时也可以回滚到事务开始之前的状态。在sqlite3中,我们可以使用commit()方法提交事务,使用rollback()方法回滚事务。
import sqlite3
# 连接到SQLite数据库
conn = sqlite3.connect('test.db')
cursor = conn.cursor()
try:
# 开始一个事务
cursor.execute("INSERT INTO users (name, age) VALUES (?, ?)", ('白敬亭', 25))
cursor.execute("UPDATE users SET age = ? WHERE name = ?", (26, '白敬亭'))
# 提交事务
conn.commit()
except Exception as e:
# 发生异常时回滚事务
print(f"An error occurred: {e}")
conn.rollback()
# 关闭游标和连接
cursor.close()
conn.close()如果我们重复插入这个数据(我们设置email为唯一的),就会报错: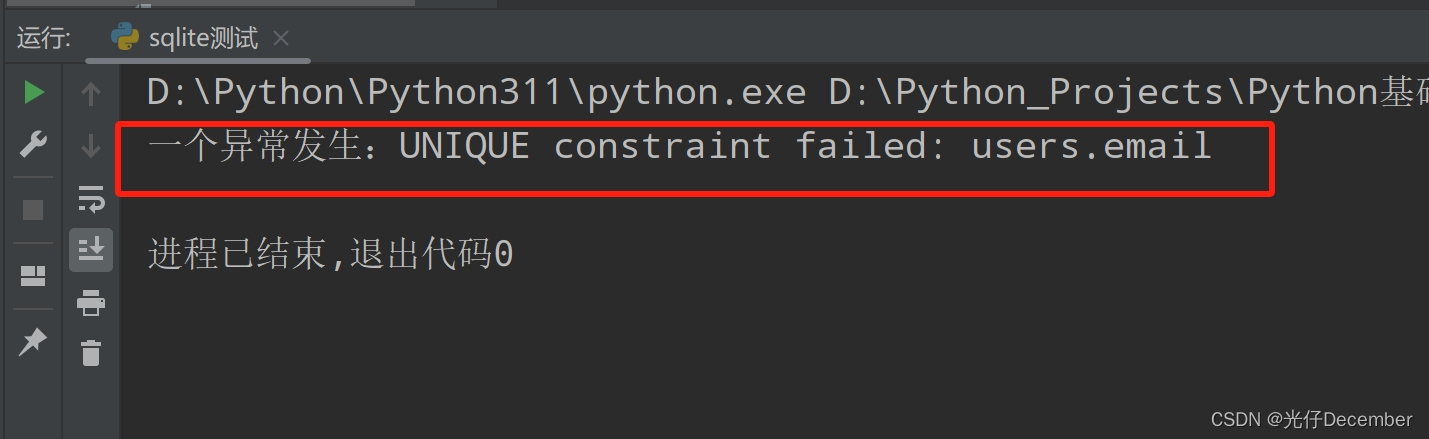
报的就是唯一策略的字段被重复插入了。
3. 使用ROWID
SQLite中的每个表都有一个特殊的ROWID列,它是一个64位整数,用于唯一标识表中的每一行。即使我们没有在表中明确指定主键列,SQLite也会自动为我们创建一个隐藏的ROWID列。我们可以使用ROWID来访问和操作表中的行。
import sqlite3
# 连接到SQLite数据库
conn = sqlite3.connect('test.db')
cursor = conn.cursor()
# 插入一条数据并获取ROWID
cursor.execute("INSERT INTO users (name, age) VALUES (?, ?)", ('彭昱畅', 28))
rowid = cursor.lastrowid
print(f"Inserted row with ROWID: {rowid}")
# 使用ROWID查询数据
query = "SELECT * FROM users WHERE rowid = ?"
cursor.execute(query, (rowid,))
result = cursor.fetchone()
print(result)
# 关闭游标和连接
cursor.close()
conn.close()效果: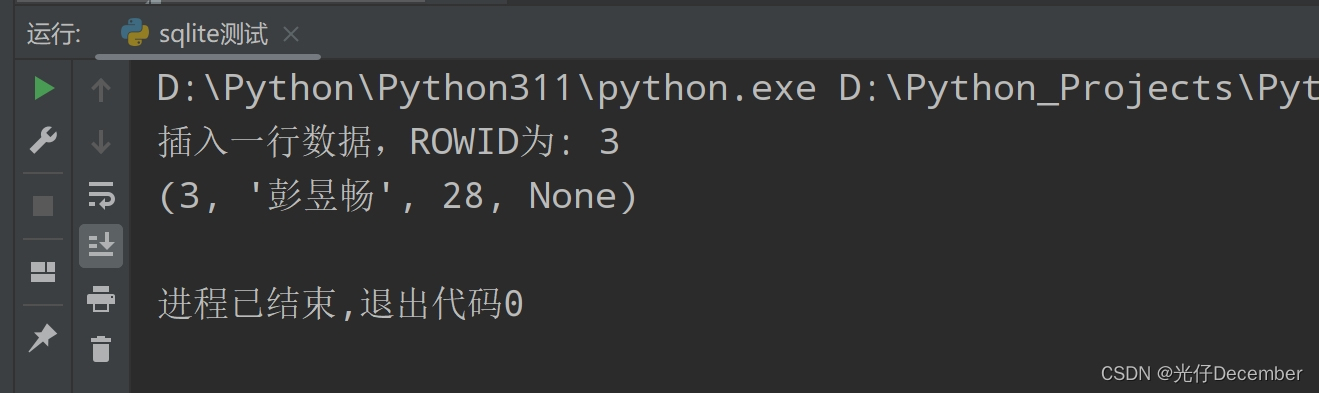
4. 使用内存数据库
除了磁盘上的文件数据库外,SQLite还支持内存数据库。内存数据库将数据存储在RAM中,因此读写速度非常快,但数据在关闭连接后会丢失。要创建内存数据库,只需将数据库文件名设置为:memory:即可。
import sqlite3
# 连接到内存数据库
conn = sqlite3.connect(':memory:')
cursor = conn.cursor()
# 在内存数据库中创建表并插入数据
cursor.execute('''
CREATE TABLE users (
id INTEGER PRIMARY KEY AUTOINCREMENT,
name TEXT NOT NULL,
age INTEGER
)
''')
cursor.execute("INSERT INTO users (name, age) VALUES (?, ?)", ('彭昱畅', 28))
# 查询并打印数据
cursor.execute("SELECT * FROM users")
for row in cursor.fetchall():
print(row)
# 关闭游标和连接(数据将丢失)
cursor.close()
conn.close()效果: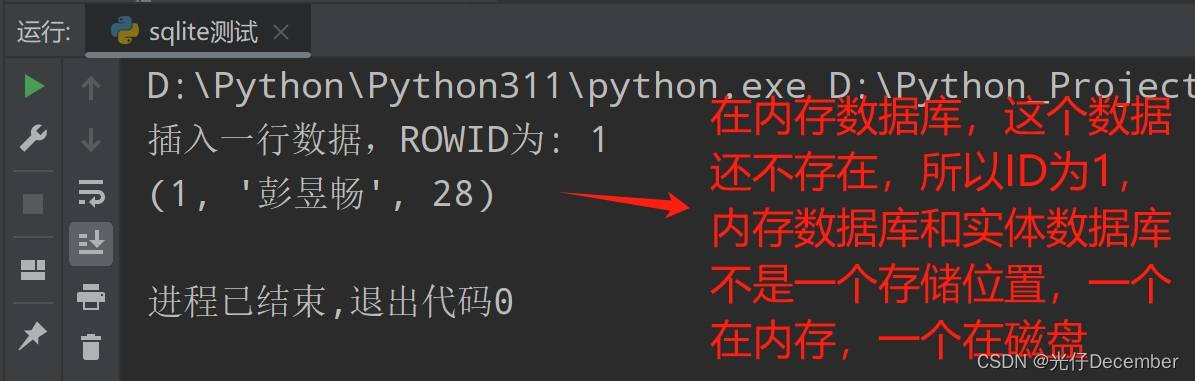
5. 使用自定义数据类型
SQLite支持多种数据类型,但默认情况下,它可能无法直接处理某些复杂的数据结构(如列表、字典等)。然而,我们可以通过Python的序列化机制(如pickle)将这些数据结构转换为字节字符串,并在SQLite中将其存储为BLOB(二进制大对象)类型。然后,我们可以使用反序列化机制将这些字节字符串还原为原始数据结构。
请注意,使用这种方法存储复杂数据结构可能会增加数据处理的复杂性和安全风险,因此应谨慎使用。
转载请注明出处:https://guangzai.blog.csdn.net/article/details/138764428
标签:
相关文章
最新发布
- 光流法结合深度学习神经网络的原理及应用(完整代码都有Python opencv)
- Python 图像处理进阶:特征提取与图像分类
- 大数据可视化分析-基于python的电影数据分析及可视化系统_9532dr50
- 【Python】入门(运算、输出、数据类型)
- 【Python】第一弹---解锁编程新世界:深入理解计算机基础与Python入门指南
- 华为OD机试E卷 --第k个排列 --24年OD统一考试(Java & JS & Python & C & C++)
- Python已安装包在import时报错未找到的解决方法
- 【Python】自动化神器PyAutoGUI —告别手动操作,一键模拟鼠标键盘,玩转微信及各种软件自动化
- Pycharm连接SQL Sever(详细教程)
- Python编程练习题及解析(49题)
点击排行
- 版本匹配指南:Numpy版本和Python版本的对应关系
- 版本匹配指南:PyTorch版本、torchvision 版本和Python版本的对应关系
- Anaconda版本和Python版本对应关系(持续更新...)
- 相关性分析——Pearson相关系数+热力图(附data和Python完整代码)
- Python 可视化 web 神器:streamlit、Gradio、dash、nicegui;低代码 Python Web 框架:PyWebIO
- Windows上安装 Python 环境并配置环境变量 (超详细教程)
- Python与PyTorch的版本对应
- 安装spacy+zh_core_web_sm避坑指南
本站推荐
