首页 > Python资料 博客日记
Python解析Word文档的自动编号
2024-08-14 18:00:08Python资料围观191次
关于自动编号的知识可以参考《在 Open XML WordprocessingML 中使用编号列表》
链接:https://learn.microsoft.com/zh-cn/previous-versions/office/ee922775(v=office.14)
python-docx库并不能直接解析出Word文档的自动编号,因为原理较为复杂,但我们希望python能够读取自动编号对应的文本。
基本解析原理
为了测试验证,我们创建一个带有编号的文档进行测试,例如:
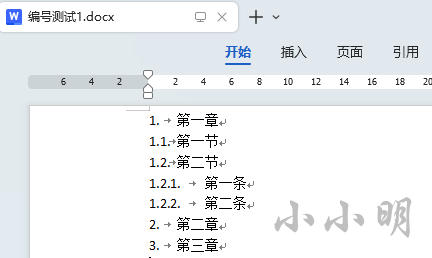
然后我们先看看主文档中,对应的xml存储:
from docx import Document
doc = Document(r"编号测试1.docx")
for paragraph in doc.paragraphs:
print(paragraph._element.xml)
break
结果:
<w:p ...>
<w:pPr>
<w:numPr>
<w:ilvl w:val="0"/>
<w:numId w:val="1"/>
</w:numPr>
<w:bidi w:val="0"/>
<w:ind w:left="0" w:leftChars="0" w:firstLine="0" w:firstLineChars="0"/>
<w:rPr>
<w:rFonts w:hint="eastAsia"/>
<w:lang w:val="en-US" w:eastAsia="zh-CN"/>
</w:rPr>
</w:pPr>
<w:r>
<w:rPr>
<w:rFonts w:hint="eastAsia"/>
<w:lang w:val="en-US" w:eastAsia="zh-CN"/>
</w:rPr>
<w:t>第一章</w:t>
</w:r>
</w:p>
在微软的文档中,说明了最重要的部分:
w:numPr 元素包含自动编号元素。w:ilvl 元素从零开始表示编号等级,w:numId 元素是编号部件的索引。
w:numId 为 0 值时 ,表示编号已经被删除段落不含列表项。
所以我们可以根据段落是否存在w:numPr并且w:numId的值不为0判断段落是否存在自动编号。
然后我们需要获取每个w:numId对应的自动编号状态,这个信息存储在zip压缩包的\word\numbering.xml文件中,可以参考微软文档的示例:

w:numbering同时包含w:num和w:abstractNum两种节点,其中w:num记录了 每个numId对应的abstractNumId,而w:abstractNum记录了每个abstractNumId对应的编号格式,包含了每个级别的编号样式信息。对于w:num,python-docx库已经帮我们解析好,可以直接读取,但w:abstractNum节点python-docx库却并未进行解析,只能我们自己进行xml解析。
可以通过如下代码获取每个numId对应的abstractNumId:
from docx import Document
doc = Document(r"编号测试1.docx")
numbering_part = doc.part.numbering_part._element
numId2abstractId = {
num.numId: num.abstractNumId.val for num in numbering_part.num_lst
}
接下来我们需要解析w:abstractNum节点,查阅python-docx库的源码可以知道,它使用lxml的etree进行xml解析。
初步解析代码为:
from docx.oxml.ns import qn
abstractNumId2style = {}
for abstractNumIdTag in numbering_part.findall(qn("w:abstractNum")):
abstractNumId = abstractNumIdTag.get(qn("w:abstractNumId"))
for lvlTag in abstractNumIdTag.findall(qn("w:lvl")):
ilvl = lvlTag.get(qn("w:ilvl"))
style = {tag.tag[tag.tag.rfind("}") + 1:]: tag.get(qn("w:val"))
for tag in lvlTag.xpath("./*[@w:val]", namespaces=numbering_part.nsmap)}
abstractNumId2style[(int(abstractNumId), int(ilvl))] = style
print(abstractNumId2style)
注意:docx.oxml.ns的qn函数可以将w:转换为对应的命名空间名称,但对于xpath表达式却无法正确处理,所以对于xpath表达式使用namespaces传入对应的命名空间。
除了上面的解析方法以外,还可以事先将节点的所有命名空间清除后再解析,清除代码如下:
def remove_namespace(node): node_tag = node.tag if '}' in node_tag: node.tag = node_tag[node_tag.rfind("}") + 1:] for attr_key in list(node.attrib): if '}' in attr_key: new_attr_key = attr_key[attr_key.rfind("}") + 1:] node.attrib[new_attr_key] = node.attrib.pop(attr_key) for child in node: remove_namespace(child) return node这样可以递归消除目标节点所有子节点的命名空间。
可以每个类别每个级别的自动编号的属性信息:
{(0, 0): {'start': '1', 'numFmt': 'decimal', 'lvlText': '%1.', 'lvlJc': 'left'}, (0, 1): {'start': '1', 'numFmt': 'decimal', 'lvlText': '%1.%2.', 'lvlJc': 'left'}, (0, 2): {'start': '1', 'numFmt': 'decimal', 'lvlText': '%1.%2.%3.', 'lvlJc': 'left'}, (0, 3): {'start': '1', 'numFmt': 'decimal', 'lvlText': '%1.%2.%3.%4.', 'lvlJc': 'left'}, (0, 4): {'start': '1', 'numFmt': 'decimal', 'lvlText': '%1.%2.%3.%4.%5.', 'lvlJc': 'left'}, (0, 5): {'start': '1', 'numFmt': 'decimal', 'lvlText': '%1.%2.%3.%4.%5.%6.', 'lvlJc': 'left'}, (0, 6): {'start': '1', 'numFmt': 'decimal', 'lvlText': '%1.%2.%3.%4.%5.%6.%7.', 'lvlJc': 'left'}, (0, 7): {'start': '1', 'numFmt': 'decimal', 'lvlText': '%1.%2.%3.%4.%5.%6.%7.%8.', 'lvlJc': 'left'}, (0, 8): {'start': '1', 'numFmt': 'decimal', 'lvlText': '%1.%2.%3.%4.%5.%6.%7.%8.%9.', 'lvlJc': 'left'}}
当然我们只测试了最基本的数值型自动编号,有些自动编号对应的节点没有直接的w:numFmt节点,解析代码还需针对性调整。
微软的文档中提到,对多级列表的某一级列表进行特殊设定时,w:num内会出现w:lvlOverride节点,但本人使用wps反复测试过后并没有出现。估计这种格式的xml只会在老版的office中出现,而且我们也不会故意在多级列表的某一级进行特殊设定,所以我们不考虑这种情况。
还需要考虑 w:suff 元素控制的列表后缀,即列表项与段落之间的空白内容,有可能为制表符和空格,也可以什么都没有。处理代码为:
{"space": " ", "nothing": ""}.get(style.get("suff"), "\t")
多级编号处理
首先尝试读取每个段落对应的自动编号样式:
for paragraph in doc.paragraphs:
numpr = paragraph._element.pPr.numPr
if numpr is not None and numpr.numId.val != 0:
numId = numpr.numId.val
ilvl = numpr.ilvl.val
abstractId = numId2abstractId[numId]
style = abstractNumId2style[(abstractId, ilvl)]
print(style)
print(paragraph.text)
结果:
{'start': '1', 'numFmt': 'decimal', 'lvlText': '%1.', 'lvlJc': 'left'}
第一章
{'start': '1', 'numFmt': 'decimal', 'lvlText': '%1.%2.', 'lvlJc': 'left'}
第一节
{'start': '1', 'numFmt': 'decimal', 'lvlText': '%1.%2.', 'lvlJc': 'left'}
第二节
{'start': '1', 'numFmt': 'decimal', 'lvlText': '%1.%2.%3.', 'lvlJc': 'left'}
第一条
{'start': '1', 'numFmt': 'decimal', 'lvlText': '%1.%2.%3.', 'lvlJc': 'left'}
第二条
{'start': '1', 'numFmt': 'decimal', 'lvlText': '%1.', 'lvlJc': 'left'}
第二章
{'start': '1', 'numFmt': 'decimal', 'lvlText': '%1.', 'lvlJc': 'left'}
第三章
我们需要一个计数器来记录每个样式出现的次数,从而生成其对应的编号。
cache = {}
for paragraph in doc.paragraphs:
numpr = paragraph._element.pPr.numPr
lvlText = ""
if numpr is not None and numpr.numId.val != 0:
numId = numpr.numId.val
ilvl = numpr.ilvl.val
abstractId = numId2abstractId[numId]
style = abstractNumId2style[(abstractId, ilvl)]
if (abstractId, ilvl) in cache:
cache[(abstractId, ilvl)] += 1
else:
cache[(abstractId, ilvl)] = int(style["start"])
lvlText = style.get("lvlText")
for i in range(0, ilvl + 1):
lvlText = lvlText.replace(f'%{i + 1}', str(cache[(abstractId, i)]))
suff_text = {"space": " ", "nothing": ""}.get(style.get("suff"), "\t")
lvlText += suff_text
print(lvlText + paragraph.text)
结果:
1. 第一章
1.1. 第一节
1.2. 第二节
1.2.1. 第一条
1.2.2. 第二条
2. 第二章
3. 第三章
各种其他类型的编号生成
为了尽量多的支持更多类型的编号,我创建了如下测试文件:

我们没有必要获取对应的圆圈数字,圆圈就获取对应的整数。
除了三种日文编号,上面的示例几乎包含所有的编号类型。需要注意三位数以上的数字格式,其xml有些特殊,例如:
<w:lvl>
<w:start w:val="1"/>
<mc:AlternateContent>
<mc:Choice Requires="w14">
<w:numFmt w:val="custom" w:format="001, 002, 003, ..."/>
</mc:Choice>
<mc:Fallback>
<w:numFmt w:val="decimal"/>
</mc:Fallback>
</mc:AlternateContent>
<w:suff w:val="space"/>
<w:lvlText w:val="%1"/>
<w:lvlJc w:val="left"/>
<w:pPr>
<w:tabs>
<w:tab w:val="left" w:pos="0"/>
</w:tabs>
</w:pPr>
<w:rPr>
<w:rFonts w:hint="default"/>
</w:rPr>
</w:lvl>
基于此,解析格式的代码也作出如下调整:
abstractNumId2style = {}
for abstractNumIdTag in numbering_part.findall(qn("w:abstractNum")):
abstractNumId = abstractNumIdTag.get(qn("w:abstractNumId"))
for lvlTag in abstractNumIdTag.findall(qn("w:lvl")):
ilvl = lvlTag.get(qn("w:ilvl"))
style = {tag.tag[tag.tag.rfind("}") + 1:]: tag.get(qn("w:val"))
for tag in lvlTag.xpath("./*[@w:val]", namespaces=numbering_part.nsmap)}
if "numFmt" not in style:
numFmtVal = lvlTag.xpath("./mc:AlternateContent/mc:Fallback/w:numFmt/@w:val",
namespaces=numbering_part.nsmap)
if numFmtVal and numFmtVal[0] == "decimal":
numFmt_format = lvlTag.xpath("./mc:AlternateContent/mc:Choice/w:numFmt/@w:format",
namespaces=numbering_part.nsmap)
if numFmt_format:
style["numFmt"] = "decimal" + numFmt_format[0].split(",")[0]
if style.get("numFmt") == "decimalZero":
style["numFmt"] = "decimal01"
abstractNumId2style[(int(abstractNumId), int(ilvl))] = style
目前只发现这种基于decimal的格式,所以只针对这种自定义格式处理,其他类型的统一认为是没有自动编号。另外既然三位数的整数格式已经被我们命名为decimal001,那么也将二位数的decimalZero修改为decimal01。
目前测试出这个文件有以下这些numFmt:
bullet,cardinalText,chineseCounting,chineseLegalSimplified,decimal,decimalEnclosedCircleChinese,ideographTraditional,ideographZodiac,lowerLetter,lowerRoman,ordinal,ordinalText,upperLetter,upperRoman
下面我们预先选择一些可能比较复杂的转换编写相应的函数:
正整数转换为大写字母
代码如下:
def int2upperLetter(num):
result = []
while num > 0:
num -= 1
remainder = num % 26
result.append(chr(remainder + ord('A')))
num //= 26
return "".join(reversed(result))
正整数转换为罗马数字
def int2upperRoman(num):
t = [
(1000, 'M'), (900, 'CM'), (500, 'D'),
(400, 'CD'), (100, 'C'), (90, 'XC'),
(50, 'L'), (40, 'XL'), (10, 'X'),
(9, 'IX'), (5, 'V'), (4, 'IV'), (1, 'I')
]
roman_num = ''
i = 0
while num > 0:
val, syb = t[i]
for _ in range(num // val):
roman_num += syb
num -= val
i += 1
return roman_num
正整数转换为英文基数字
def int2cardinalText(num):
if not isinstance(num, int) or num < 0 or num > 999999999999:
raise ValueError(
"Invalid number: must be a positive integer within four digits")
base = ["Zero", "One", "Two", "Three", "Four", "Five", "Six",
"Seven", "Eight", "Nine", "Ten", "Eleven", "Twelve", "Thirteen", "Fourteen",
"Fifteen", "Sixteen", "Seventeen", "Eighteen", "Nineteen"]
tens = ["", "", "Twenty", "Thirty", "Fourty",
"Fifty", "Sixty", "Seventy", "Eighty", "Ninety"]
thousands = ["", "Thousand", "Million", "Billion"]
def two_digits(n):
if n < 20:
return base[n]
ten, unit = divmod(n, 10)
if unit == 0:
return f"{tens[ten]}"
else:
return f"{tens[ten]}-{base[unit]}"
def three_digits(n):
hundred, rest = divmod(n, 100)
if hundred == 0:
return two_digits(rest)
result = f"{base[hundred]} hundred "
if rest > 0:
result += two_digits(rest)
return result.strip()
if num < 99:
return two_digits(num)
chunks = []
while num > 0:
num, remainder = divmod(num, 1000)
chunks.append(remainder)
words = []
for i in range(len(chunks) - 1, -1, -1):
if chunks[i] == 0:
continue
chunk_word = three_digits(chunks[i])
if thousands[i]:
chunk_word += f" {thousands[i]}"
words.append(chunk_word)
words = " ".join(words).lower()
return words[0].upper()+words[1:]
正整数转换为英文序数字
def int2ordinalText(num):
if not isinstance(num, int) or num < 0 or num > 999999:
raise ValueError(
"Invalid number: must be a positive integer within four digits")
base = ["Zero", "One", "Two", "Three", "Four", "Five", "Six",
"Seven", "Eight", "Nine", "Ten", "Eleven", "Twelve", "Thirteen", "Fourteen",
"Fifteen", "Sixteen", "Seventeen", "Eighteen", "Nineteen"]
baseth = ['Zeroth', 'First', 'Second', 'Third', 'Fourth', 'Fifth', 'Sixth', 'Seventh',
'Eighth', 'Ninth', 'Tenth', 'Eleventh', 'Twelfth', 'Thirteenth', 'Fourteenth',
'Fifteenth', 'Sixteenth', 'Seventeenth', 'Eighteenth', 'Nineteenth', 'Twentieth']
tens = ["", "", "Twenty", "Thirty", "Fourty",
"Fifty", "Sixty", "Seventy", "Eighty", "Ninety"]
tensth = ["", "", "Twentieth", "Thirtieth", "Fortieth",
"Fiftieth", "Sixtieth", "Seventieth", "Eightieth", "Ninetieth"]
def two_digits(n):
if n <= 20:
return baseth[n]
ten, unit = divmod(n, 10)
result = tensth[ten]
if unit != 0:
result = f"{tens[ten]}-{baseth[unit]}"
return result
thousand, num = divmod(num, 1000)
result = []
if thousand > 0:
if num == 0:
return f"{int2cardinalText(thousand)} thousandth"
result.append(f"{int2cardinalText(thousand)} thousand")
hundred, num = divmod(num, 100)
if hundred > 0:
if num == 0:
result.append(f"{base[hundred]} hundredth")
return " ".join(result)
result.append(f"{base[hundred]} hundred")
result.append(two_digits(num))
result = " ".join(result).lower()
return result[0].upper() + result[1:]
会复用前面的基数字转换规则。
正整数转换为中文数字
import re
def int2Chinese(num, ch_num, units):
if not (0 <= num <= 99999999):
raise ValueError("仅支持小于一亿以内的正整数")
def int2Chinese_in(num, ch_num, units):
if not (0 <= num <= 9999):
raise ValueError("仅支持小于一万以内的正整数")
result = [ch_num[int(i)] + unit for i, unit in zip(reversed(str(num).zfill(4)), units)]
result = "".join(reversed(result))
zero_char = ch_num[0]
result = re.sub(f"(?:{zero_char}[{units}])+", zero_char, result)
result = result.rstrip(units[0])
if result != zero_char:
result = result.rstrip(zero_char)
if result.lstrip(zero_char).startswith("一十"):
result = result.replace("一", "")
return result
if num < 10000:
result = int2Chinese_in(num, ch_num, units)
else:
left = num // 10000
right = num % 10000
result = int2Chinese_in(left, ch_num, units) + "万" + int2Chinese_in(right, ch_num, units)
if result != ch_num[0]:
result = result.strip(ch_num[0])
return result
def int2ChineseCounting(num):
return int2Chinese(num, ch_num='〇一二三四五六七八九', units='个十百千')
def int2ChineseLegalSimplified(num):
return int2Chinese(num, ch_num='零壹贰叁肆伍陆柒捌玖', units='个拾佰仟')
整体封装并改进
最终封装成为一个类:
import logging
import re
from io import BytesIO
from PIL import Image
from docx import Document, ImagePart
from docx.oxml.ns import qn, nsmap
from docx.text.paragraph import Paragraph
from functools import lru_cache
class WithNumberDocxReader:
ideographTraditional = "甲乙丙丁戊己庚辛壬癸"
ideographZodiac = "子丑寅卯辰巳午未申酉戌亥"
def __init__(self, docx, gap_text="\t"):
self.parts = []
self.docx = Document(docx)
nsmap.update(self.docx.element.nsmap)
self.numId2style = self.get_style_data()
self.gap_text = gap_text
self.cnt = {}
self.cache = {}
self.result = []
@property
def texts(self):
if self.result:
return self.result.copy()
self.clear()
for paragraph in self.paragraphs:
number_text = self.get_number_text(paragraph)
line = number_text + paragraph.text.strip()
if not line:
continue
self.result.append(line)
return self.result.copy()
def clear(self):
self.result.clear()
self.cnt.clear()
self.cache.clear()
@property
@lru_cache
def paragraphs(self):
body = self.docx.element.body
result = []
for p in body.xpath('w:p | w:sdt/w:sdtContent/w:p | w:p//v:textbox//w:p'):
result.append(Paragraph(p, body))
return result
@property
def images(self):
if self.parts:
return self.parts.copy()
related_parts = self.docx.part.related_parts
for i, paragraph in enumerate(self.paragraphs, 1):
for run in paragraph.runs:
for drawing in run.element.drawing_lst:
rid = drawing.xpath(".//a:blip/@r:embed")
if not rid or rid[0] not in related_parts:
continue
part = related_parts[rid[0]]
if isinstance(part, ImagePart):
self.parts.append((i, part.partname, part.blob))
return self.parts
def get_style_data(self):
try:
numbering_part = self.docx.part.numbering_part._element
abstractId2numId = {num.abstractNumId.val: num.numId for num in numbering_part.num_lst}
numId2style = {}
for abstractNumIdTag in numbering_part.findall(qn("w:abstractNum")):
abstractNumId = abstractNumIdTag.get(qn("w:abstractNumId"))
numId = abstractId2numId[int(abstractNumId)]
for lvlTag in abstractNumIdTag.findall(qn("w:lvl")):
ilvl = lvlTag.get(qn("w:ilvl"))
style = {tag.tag[tag.tag.rfind("}") + 1:]: tag.get(qn("w:val"))
for tag in lvlTag.xpath("./*[@w:val]", namespaces=nsmap)}
if "numFmt" not in style:
numFmtVal = lvlTag.xpath("./mc:AlternateContent/mc:Fallback/w:numFmt/@w:val",
namespaces=nsmap)
if numFmtVal and numFmtVal[0] == "decimal":
numFmt_format = lvlTag.xpath("./mc:AlternateContent/mc:Choice/w:numFmt/@w:format",
namespaces=nsmap)
if numFmt_format:
style["numFmt"] = "decimal" + numFmt_format[0].split(",")[0]
if style.get("numFmt") == "decimalZero":
style["numFmt"] = "decimal01"
numId2style[(numId, int(ilvl))] = style
return numId2style
except Exception as e:
logging.warning("读取自动编号出错:" + e.__class__.__name__)
@staticmethod
def int2upperLetter(num):
result = []
while num > 0:
num -= 1
remainder = num % 26
result.append(chr(remainder + ord('A')))
num //= 26
return "".join(reversed(result))
@staticmethod
def int2upperRoman(num):
t = [
(1000, 'M'), (900, 'CM'), (500, 'D'),
(400, 'CD'), (100, 'C'), (90, 'XC'),
(50, 'L'), (40, 'XL'), (10, 'X'),
(9, 'IX'), (5, 'V'), (4, 'IV'), (1, 'I')
]
roman_num = ''
i = 0
while num > 0:
val, syb = t[i]
for _ in range(num // val):
roman_num += syb
num -= val
i += 1
return roman_num
@staticmethod
def int2cardinalText(num):
if not isinstance(num, int) or num < 0 or num > 999999999:
raise ValueError(
"Invalid number: must be a positive integer within four digits")
base = ["Zero", "One", "Two", "Three", "Four", "Five", "Six",
"Seven", "Eight", "Nine", "Ten", "Eleven", "Twelve", "Thirteen", "Fourteen",
"Fifteen", "Sixteen", "Seventeen", "Eighteen", "Nineteen"]
tens = ["", "", "Twenty", "Thirty", "Fourty",
"Fifty", "Sixty", "Seventy", "Eighty", "Ninety"]
thousands = ["", "Thousand", "Million", "Billion"]
def two_digits(n):
if n < 20:
return base[n]
ten, unit = divmod(n, 10)
if unit == 0:
return f"{tens[ten]}"
else:
return f"{tens[ten]}-{base[unit]}"
def three_digits(n):
hundred, rest = divmod(n, 100)
if hundred == 0:
return two_digits(rest)
result = f"{base[hundred]} hundred "
if rest > 0:
result += two_digits(rest)
return result.strip()
if num < 99:
return two_digits(num)
chunks = []
while num > 0:
num, remainder = divmod(num, 1000)
chunks.append(remainder)
words = []
for i in range(len(chunks) - 1, -1, -1):
if chunks[i] == 0:
continue
chunk_word = three_digits(chunks[i])
if thousands[i]:
chunk_word += f" {thousands[i]}"
words.append(chunk_word)
words = " ".join(words).lower()
return words[0].upper() + words[1:]
@staticmethod
def int2ordinalText(num):
if not isinstance(num, int) or num < 0 or num > 999999:
raise ValueError(
"Invalid number: must be a positive integer within four digits")
base = ["Zero", "One", "Two", "Three", "Four", "Five", "Six",
"Seven", "Eight", "Nine", "Ten", "Eleven", "Twelve", "Thirteen", "Fourteen",
"Fifteen", "Sixteen", "Seventeen", "Eighteen", "Nineteen"]
baseth = ['Zeroth', 'First', 'Second', 'Third', 'Fourth', 'Fifth', 'Sixth', 'Seventh',
'Eighth', 'Ninth', 'Tenth', 'Eleventh', 'Twelfth', 'Thirteenth', 'Fourteenth',
'Fifteenth', 'Sixteenth', 'Seventeenth', 'Eighteenth', 'Nineteenth', 'Twentieth']
tens = ["", "", "Twenty", "Thirty", "Fourty",
"Fifty", "Sixty", "Seventy", "Eighty", "Ninety"]
tensth = ["", "", "Twentieth", "Thirtieth", "Fortieth",
"Fiftieth", "Sixtieth", "Seventieth", "Eightieth", "Ninetieth"]
def two_digits(n):
if n <= 20:
return baseth[n]
ten, unit = divmod(n, 10)
result = tensth[ten]
if unit != 0:
result = f"{tens[ten]}-{baseth[unit]}"
return result
thousand, num = divmod(num, 1000)
result = []
if thousand > 0:
if num == 0:
return f"{WithNumberDocxReader.int2cardinalText(thousand)} thousandth"
result.append(f"{WithNumberDocxReader.int2cardinalText(thousand)} thousand")
hundred, num = divmod(num, 100)
if hundred > 0:
if num == 0:
result.append(f"{base[hundred]} hundredth")
return " ".join(result)
result.append(f"{base[hundred]} hundred")
result.append(two_digits(num))
result = " ".join(result).lower()
return result[0].upper() + result[1:]
@staticmethod
def int2Chinese(num, ch_num, units):
if not (0 <= num <= 99999999):
raise ValueError("仅支持小于一亿以内的正整数")
def int2Chinese_in(num, ch_num, units):
if not (0 <= num <= 9999):
raise ValueError("仅支持小于一万以内的正整数")
result = [ch_num[int(i)] + unit for i, unit in zip(reversed(str(num).zfill(4)), units)]
result = "".join(reversed(result))
zero_char = ch_num[0]
result = re.sub(f"(?:{zero_char}[{units}])+", zero_char, result)
result = result.rstrip(units[0])
if result != zero_char:
result = result.rstrip(zero_char)
if result.lstrip(zero_char).startswith("一十"):
result = result.replace("一", "")
return result
if num < 10000:
result = int2Chinese_in(num, ch_num, units)
else:
left = num // 10000
right = num % 10000
result = int2Chinese_in(left, ch_num, units) + "万" + int2Chinese_in(right, ch_num, units)
if result != ch_num[0]:
result = result.strip(ch_num[0])
return result
@staticmethod
def int2ChineseCounting(num):
return WithNumberDocxReader.int2Chinese(num, ch_num='〇一二三四五六七八九', units='个十百千')
@staticmethod
def int2ChineseLegalSimplified(num):
return WithNumberDocxReader.int2Chinese(num, ch_num='零壹贰叁肆伍陆柒捌玖', units='个拾佰仟')
def get_number_text(self, paragraph):
if self.numId2style is None:
return ""
pr = paragraph._element.pPr
if pr is None:
return ""
numpr = pr.numPr
if numpr is None or numpr.numId.val == 0:
return ""
numId = numpr.numId.val
ilvl = numpr.ilvl.val
style = self.numId2style[(numId, ilvl)]
numFmt: str = style.get("numFmt")
lvlText = style.get("lvlText")
isTxbxContent = paragraph._element.getparent().tag.endswith("txbxContent")
for a, b, c in list(self.cnt.keys()):
if a == numId and c == isTxbxContent and b > ilvl:
del self.cnt[(a, b, c)]
pos_key = (numId, ilvl, isTxbxContent)
if pos_key in self.cnt:
self.cnt[pos_key] += 1
else:
self.cnt[pos_key] = int(style["start"])
pos = self.cnt[pos_key]
num_text = str(pos)
if numFmt.startswith('decimal'):
num_text = num_text.zfill(numFmt.count("0") + 1)
elif numFmt == 'upperRoman':
num_text = self.int2upperRoman(pos)
elif numFmt == 'lowerRoman':
num_text = self.int2upperRoman(pos).lower()
elif numFmt == 'upperLetter':
num_text = self.int2upperLetter(pos)
elif numFmt == 'lowerLetter':
num_text = self.int2upperLetter(pos).lower()
elif numFmt == 'ordinal':
num_text = f"{pos}{'th' if 11 <= pos <= 13 else {1: 'st', 2: 'nd', 3: 'rd'}.get(pos % 10, 'th')}"
elif numFmt == 'cardinalText':
num_text = self.int2cardinalText(pos)
elif numFmt == 'ordinalText':
num_text = self.int2ordinalText(pos)
elif numFmt == 'ideographTraditional':
if 1 <= pos <= 10:
num_text = self.ideographTraditional[pos - 1]
elif numFmt == 'ideographZodiac':
if 1 <= pos <= 12:
num_text = self.ideographZodiac[pos - 1]
elif numFmt == 'chineseCounting':
num_text = self.int2ChineseCounting(pos)
elif numFmt == 'chineseLegalSimplified':
num_text = self.int2ChineseLegalSimplified(pos)
elif numFmt == 'decimalEnclosedCircleChinese':
pass
self.cache[pos_key] = num_text
for i in range(0, ilvl + 1):
lvlText = lvlText.replace(f'%{i + 1}', self.cache.get((numId, i, isTxbxContent), ""))
suff_text = {"space": " ", "nothing": ""}.get(style.get("suff"), self.gap_text)
lvlText += suff_text
return lvlText
if __name__ == '__main__':
doc = WithNumberDocxReader(r"编号测试1.docx", " ")
for text in doc.texts:
print(text)
for i, name, image_bytes in doc.images:
print(i, name)
image = Image.open(BytesIO(image_bytes))
image.show()
调用测试:
if __name__ == '__main__':
doc = WithNumberDocxReader(r"编号测试2.docx", "")
for text in doc.texts:
print(text)
顺利达到打印出对应的字符:
点符
1.十进制数
01.零加十进制数
001 零零加十进制数
0001 零零零加十进制数
I 大写罗马数字 (I)
II 大写罗马数字 (II)
i 小写罗马数字
A.大写字母A
a 小写字母 (a)
0th 序数 (1st, 2nd, 3rd)
Twelve 基数字 (One, Two Three)
First 序数字 (First, Second, Third)
癸 甲乙丙丁戊己庚辛壬癸
壹 中文大写数字
10 圆圈数字
子 子丑寅卯辰巳午未申酉戌亥
第一章 中文数字
标签:
相关文章
最新发布
- 光流法结合深度学习神经网络的原理及应用(完整代码都有Python opencv)
- Python 图像处理进阶:特征提取与图像分类
- 大数据可视化分析-基于python的电影数据分析及可视化系统_9532dr50
- 【Python】入门(运算、输出、数据类型)
- 【Python】第一弹---解锁编程新世界:深入理解计算机基础与Python入门指南
- 华为OD机试E卷 --第k个排列 --24年OD统一考试(Java & JS & Python & C & C++)
- Python已安装包在import时报错未找到的解决方法
- 【Python】自动化神器PyAutoGUI —告别手动操作,一键模拟鼠标键盘,玩转微信及各种软件自动化
- Pycharm连接SQL Sever(详细教程)
- Python编程练习题及解析(49题)
点击排行
- 版本匹配指南:Numpy版本和Python版本的对应关系
- 版本匹配指南:PyTorch版本、torchvision 版本和Python版本的对应关系
- Anaconda版本和Python版本对应关系(持续更新...)
- 相关性分析——Pearson相关系数+热力图(附data和Python完整代码)
- Python 可视化 web 神器:streamlit、Gradio、dash、nicegui;低代码 Python Web 框架:PyWebIO
- Windows上安装 Python 环境并配置环境变量 (超详细教程)
- Python与PyTorch的版本对应
- 安装spacy+zh_core_web_sm避坑指南
本站推荐
