首页 > Python资料 博客日记
Python中random函数用法整理
2024-02-26 00:00:07Python资料围观223次
目录
1. random.random(): 返回随机生成的一个浮点数,范围在[0,1)之间
2. random.uniform(a, b): 返回随机生成的一个浮点数,范围在[a, b)之间
3. random.randint(a,b):生成指定范围内的整数
4. random.randrange([start],stop[,step]):用于从指定范围内按指定基数递增的集合中获取一个随机数。
5. random.choice():从指定的序列中获取一个随机元素
6. random.shuffle(x[,random]):用于将一个列表中的元素打乱,随机排序
7. random.sample(sequence,k):用于从指定序列中随机获取指定长度的片段,sample()函数不会修改原有序列。
8. np.random.rand(d0, d1, …, dn): 返回一个或一组浮点数,范围在[0, 1)之间
9. np.random.normal(loc=a, scale=b, size=()): 返回满足条件为均值=a, 标准差=b的正态分布(高斯分布)的概率密度随机数
10 np.random.randn(d0, d1, … dn): 返回标准正态分布(均值=0,标准差=1)的概率密度随机数
11. np.random.standard_normal(size=()): 返回标准正态分布(均值=0,标准差=1)的概率密度随机数
12. np.random.randint(a, b, size=(), dtype=int): 返回在范围在[a, b)中的随机整数(含有重复值)
首先我们需要导入random模块
1. random.random(): 返回随机生成的一个浮点数,范围在[0,1)之间
import random
print(random.random())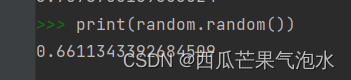
2. random.uniform(a, b): 返回随机生成的一个浮点数,范围在[a, b)之间
import random
print(random.uniform(1,5))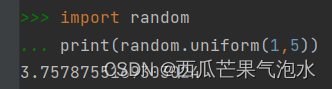
3. random.randint(a,b):生成指定范围内的整数
import random
print(random.randint(1,10))
4. random.randrange([start],stop[,step]):用于从指定范围内按指定基数递增的集合中获取一个随机数。
例如random.randrange(10,100,2),结果相当于从 [10,12,14,16...96,98] 序列中获取一个随机数。random.randrange (10,100,2) 的结果上与 random.choice(range(10,100,2)) 等效。
import random
print(random.randrange(10,22,3))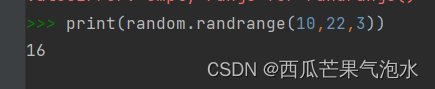
5. random.choice():从指定的序列中获取一个随机元素
random.choice()从序列中获取一个随机元素,其原型为random.choice(sequence),参数sequence表示一个有序类型。这里说明一下,sequence在Python中不是一种特定的类型,而是泛指序列数据结构。列表,元组,字符串都属于sequence。
import random
print(random.choice('学习python')) # 从字符串中随机取一个字符
print(random.choice(['good', 'hello', 'is', 'hi', 'boy'])) # 从list列表中随机取
print(random.choice(('str', 'tuple', 'list'))) # 从tuple元组中随机取
6. random.shuffle(x[,random]):用于将一个列表中的元素打乱,随机排序
import random
p=['hehe','xixi','heihei','haha','zhizhi','lala','momo..da']
random.shuffle(p)
print(p)
x = [1, 2, 3, 4, 5]
random.shuffle(x)
print(x)

7. random.sample(sequence,k):用于从指定序列中随机获取指定长度的片段,sample()函数不会修改原有序列。
import random
list1=[1,2,3,4,5,6,7,8,9,10]
slice=random.sample(list1,5)
print(slice)
#[8, 3, 5, 9, 10]
print(list1)
#[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
x = random.sample(range(0, 10), 5)
print(x, type(x))
#[9, 2, 7, 8, 6] <class 'list'>
Words = "AppleKMedoide"
print(random.sample(Words, 3))
#['p', 'M', 'A']
print(random.sample(Words, 3))
#['d', 'i', 'l']
下面的函数需要调用numpy库
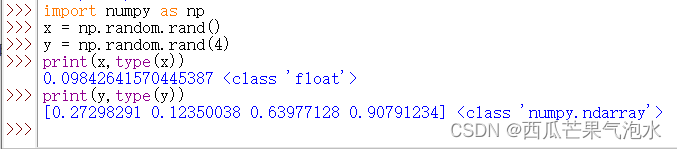
8. np.random.rand(d0, d1, …, dn): 返回一个或一组浮点数,范围在[0, 1)之间
import random
import numpy as np
x = np.random.rand()
y = np.random.rand(4)
print(x,type(x))
#0.09842641570445387 <class 'float'>
print(y,type(y))
#[0.27298291 0.12350038 0.63977128 0.90791234] <class 'numpy.ndarray'>
9. np.random.normal(loc=a, scale=b, size=()): 返回满足条件为均值=a, 标准差=b的正态分布(高斯分布)的概率密度随机数
np.random.normal(loc=a, scale=b, size=()) - 返回满足条件为均值=a, 标准差=b的正态分布(高斯分布)的概率密度随机数,size默认为None(返回1个随机数),也可以为int或数组
import random
import numpy as np
x = np.random.normal(10,0.2,2)
print(x,type(x))
#[9.78391585 9.83981096] <class 'numpy.ndarray'>
y = np.random.normal(10,0.2)
print(y,type(y))
#9.871187751372984 <class 'float'>
z = np.random.normal(0,0.1,(2,3))
print(z,type(z))
#[[-0.07114831 -0.10258022 -0.12686863]
# [-0.08988384 -0.00647591 0.06990716]] <class 'numpy.ndarray'>
z = np.random.normal(0,0.1,[2,2])
print(z,type(z))
#[[ 0.07178268 -0.00226728]
# [ 0.06585013 -0.04385656]] <class 'numpy.ndarray'>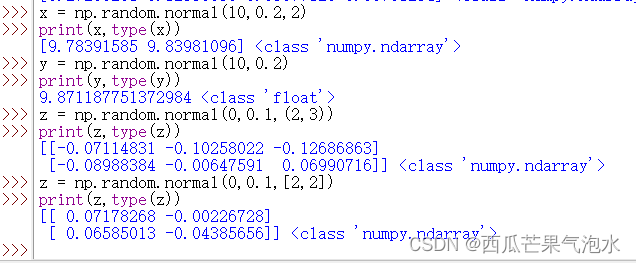
10 np.random.randn(d0, d1, … dn): 返回标准正态分布(均值=0,标准差=1)的概率密度随机数
np.random.randn(d0, d1, ... dn): 返回标准正态分布(均值=0,标准差=1)的概率密度随机数,
import random
import numpy as np
x = np.random.randn()
y = np.random.randn(3)
z = np.random.randn(3, 3)
print(x, type(x))
print(y, type(y))
print(z, type(z))

11. np.random.standard_normal(size=()): 返回标准正态分布(均值=0,标准差=1)的概率密度随机数
np.random.standard_normal(): 返回标准正态分布(均值=0,标准差=1)的概率密度随机数, size默认为None(返回1个随机数),也可以为int或数组
import random
import numpy as np
x = np.random.standard_normal()
y = np.random.standard_normal(size=(3,3))
print(x, type(x))
print(y, type(y))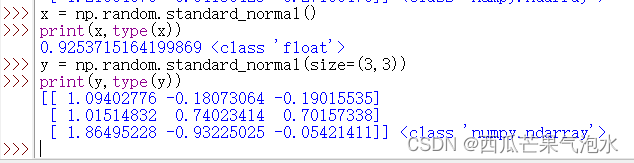
np.random.rand()与np.random.standard_normal()的方法结果相似,都是返回合符标准正态分布的随机浮点数或数组。
12. np.random.randint(a, b, size=(), dtype=int): 返回在范围在[a, b)中的随机整数(含有重复值)
np.random.randint(a, b, sizie=(), dytpe=int) - size默认为None(返回1个随机数),也可以为int或数组
import random
import numpy as np
# 从序列[0, 10)之间返回shape=(5,5)的10个随机整数(包含重复值)
x = np.random.randint(0, 10, size=(5, 5))
# 从序列[15, 20)之间返回1个随机整数(size默认为None, 则返回1个随机整数)
y = np.random.randint(15, 20)
print(x, type(x))
print(y, type(y))
13. random.seed(): 设定随机种子
在设定随机种子为10之后,random.random()的随机数将被直接设定为:0.5714025946899135
import random
random.seed(10)
x = random.random()
print(x,type(x))
random.seed(10)
y = random.random()
print(y,type(y))
z = random.random()
print(z,type(z))
random随机数是这样生成的:我们将这套复杂的算法(是叫随机数生成器吧)看成一个黑盒,把我们准备好的种子扔进去,它会返给你两个东西,一个是你想要的随机数,另一个是保证能生成下一个随机数的新的种子,把新的种子放进黑盒,又得到一个新的随机数和一个新的种子,从此在生成随机数的路上越走越远。
我们利用如下代码进行测试:
import numpy as np
if __name__ == '__main__':
i = 0
while i < 6:
if i < 3:
np.random.seed(0)
print(np.random.randn(1, 5))
else:
print(np.random.randn(1, 5))
i += 1
i = 0
while i < 2:
print(np.random.randn(1, 5))
i += 1
print(np.random.randn(2, 5))
np.random.seed(0)
print("###################################")
i = 0
while i < 8:
print(np.random.randn(1,5))
i += 1
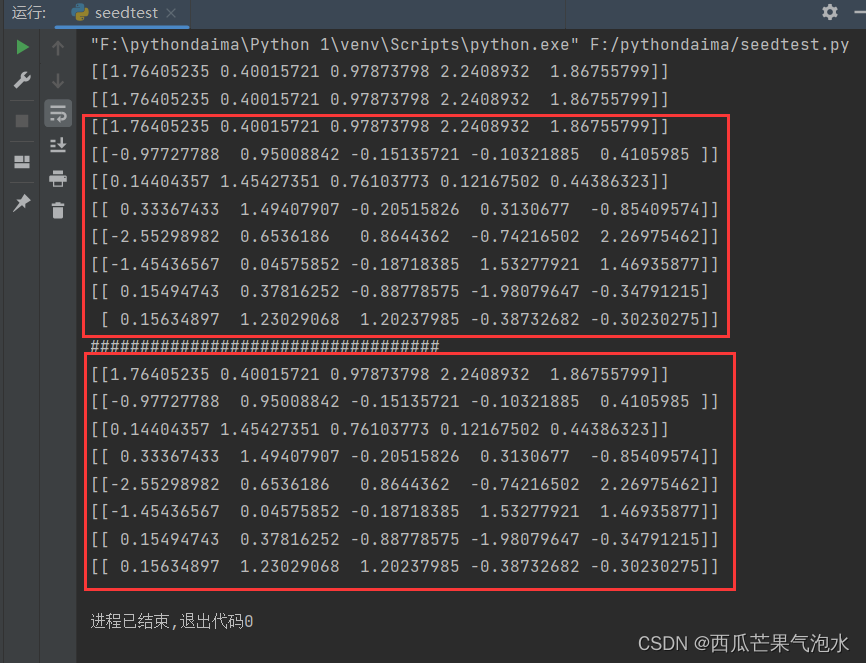
通过该实验我们可以得到以下结论:
- 两次利用随机数种子后,即便是跳出循环后,生成随机数的结果依然是相同的。第一次跳出while循环后,进入第二个while循环,得到的两个随机数组确实和加了随机数种子不一样。但是,后面的加了随机数种子的,八次循环中的结果和前面的结果是一样的。说明,随机数种子对后面的结果一直有影响。同时,加了随机数种子以后,后面的随机数组都是按一定的顺序生成的。
- 在同样的随机种子后第六次的随机数生成结果,两行五列的数组和两个一行五列的数组结果相同。说明,在生成多行随机数组时,是由单行随机数组组合而成的。
- 利用随机数种子,每次生成的随机数相同,就是使后面的随机数按一定的顺序生成。当随机数种子参数为0和1时,生成的随机数和我上面高亮的结果相同。说明该参数指定了一个随机数生成的起始位置。每个参数对应一个位置。并且在该参数确定后,其后面的随机数的生成顺序也就确定了。
- 随机数种子的参数怎么选择?我认为随意,这个参数只是确定一下随机数的起始位置。
本文综合参考了如下文章整理:
python中的random用法_山深✨的博客-CSDN博客_python中random的用法![]() https://blog.csdn.net/shoushou_/article/details/119652905?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522165352582116781685333907%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=165352582116781685333907&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~top_positive~default-2-119652905-null-null.142^v10^pc_search_result_control_group,157^v12^control&utm_term=python+random&spm=1018.2226.3001.4187python random函数_PandaDou的博客-CSDN博客_python random函数
https://blog.csdn.net/shoushou_/article/details/119652905?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522165352582116781685333907%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=165352582116781685333907&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~top_positive~default-2-119652905-null-null.142^v10^pc_search_result_control_group,157^v12^control&utm_term=python+random&spm=1018.2226.3001.4187python random函数_PandaDou的博客-CSDN博客_python random函数![]() https://blog.csdn.net/m0_37822685/article/details/80363530?spm=1001.2101.3001.6650.1&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1-80363530-blog-119652905.pc_relevant_paycolumn_v3&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1-80363530-blog-119652905.pc_relevant_paycolumn_v3&utm_relevant_index=1python常用random随机函数汇总,用法详解及函数之间的区别--一图了解python随机函数_若芷兰的博客-CSDN博客_python随机函数
https://blog.csdn.net/m0_37822685/article/details/80363530?spm=1001.2101.3001.6650.1&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1-80363530-blog-119652905.pc_relevant_paycolumn_v3&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1-80363530-blog-119652905.pc_relevant_paycolumn_v3&utm_relevant_index=1python常用random随机函数汇总,用法详解及函数之间的区别--一图了解python随机函数_若芷兰的博客-CSDN博客_python随机函数![]() https://blog.csdn.net/weixin_45914452/article/details/115264053?spm=1001.2101.3001.6661.1&utm_medium=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7ECTRLIST%7Edefault-1-115264053-blog-110164241.pc_relevant_default&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7ECTRLIST%7Edefault-1-115264053-blog-110164241.pc_relevant_default&utm_relevant_index=1随机种子的理解_一个新新的小白的博客-CSDN博客_随机种子
https://blog.csdn.net/weixin_45914452/article/details/115264053?spm=1001.2101.3001.6661.1&utm_medium=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7ECTRLIST%7Edefault-1-115264053-blog-110164241.pc_relevant_default&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7ECTRLIST%7Edefault-1-115264053-blog-110164241.pc_relevant_default&utm_relevant_index=1随机种子的理解_一个新新的小白的博客-CSDN博客_随机种子![]() https://blog.csdn.net/qq_31511955/article/details/110424334
https://blog.csdn.net/qq_31511955/article/details/110424334
标签:
相关文章
最新发布
- 光流法结合深度学习神经网络的原理及应用(完整代码都有Python opencv)
- Python 图像处理进阶:特征提取与图像分类
- 大数据可视化分析-基于python的电影数据分析及可视化系统_9532dr50
- 【Python】入门(运算、输出、数据类型)
- 【Python】第一弹---解锁编程新世界:深入理解计算机基础与Python入门指南
- 华为OD机试E卷 --第k个排列 --24年OD统一考试(Java & JS & Python & C & C++)
- Python已安装包在import时报错未找到的解决方法
- 【Python】自动化神器PyAutoGUI —告别手动操作,一键模拟鼠标键盘,玩转微信及各种软件自动化
- Pycharm连接SQL Sever(详细教程)
- Python编程练习题及解析(49题)
点击排行
- 版本匹配指南:Numpy版本和Python版本的对应关系
- 版本匹配指南:PyTorch版本、torchvision 版本和Python版本的对应关系
- Anaconda版本和Python版本对应关系(持续更新...)
- 相关性分析——Pearson相关系数+热力图(附data和Python完整代码)
- Python 可视化 web 神器:streamlit、Gradio、dash、nicegui;低代码 Python Web 框架:PyWebIO
- Windows上安装 Python 环境并配置环境变量 (超详细教程)
- Python与PyTorch的版本对应
- 安装spacy+zh_core_web_sm避坑指南
本站推荐
