首页 > Python资料 博客日记
『玩转Streamlit』--集成定时任务
2025-01-09 14:00:03Python资料围观77次
学习了Streamlit了之后,可以尝试给自己的命令行小工具加一个简单的界面。
本篇总结了我改造自己的数据采集的工具时的一些经验。
1. 概要
与常规的程序相比,数据采集任务的特点很明显,比如它一般都是I/O密集型程序,涉及大量网络请求或文件读写,耗费的时间比较长;而且往往是按照一定的时间间隔周期性地执行。
这样的程序对交互性要求不高,所以我之前都是用命令行的方式来实现的。
命令行虽然完成采集的任务没有问题,但是采集程序多了之后,管理起来不太方便,
比如,需要查看某个采集程序的配置,或是查看采集程序的状态时,需要登录服务器的命令行页面去查看。
于是,自然就想到使用Streamlit来构造一个简单的界面,本来采集程序也是用Python编写的,
与Streamlit集成非常方便。
下面主要使用Streamlit完成以下功能:
- 启动定时任务
- 停止定时任务
- 查看任务状态
2. 实现示例
数据集采集任务都是耗时比较长的,在命令行中无所谓,把定时任务放在一个无限循环中,
不断的去执行就行了。停止采集只要中断命令行(比如Ctrl+C)就行。
但是,在Streamlit中,不能被采集任务阻塞住页面,所以要用多线程或多进程的方式来启动。
因为不同的采集程序是独立的,所以下面的示例采用多进程的方式。
同时,通过Streamlit的session_state来存储采集程序的状态,从而实现控制采集程序启停的功能。
大致的结构如下:
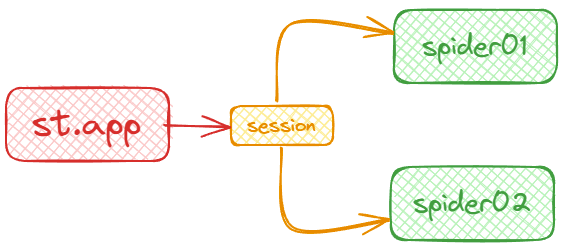
具体代码如下,其中的采集程序是模拟的,主要是为了展示如何通过Streamlit App来控制其他任务的执行。
import streamlit as st
import pandas as pd
import multiprocessing
import time
if "status01" not in st.session_state:
st.session_state.status01 = False
if "status02" not in st.session_state:
st.session_state.status02 = False
def spider01():
"""模拟数据采集01"""
while True:
print("数据采集01...")
time.sleep(3)
def spider02():
"""模拟数据采集02"""
while True:
print("数据采集02...")
time.sleep(3)
st.title("采集管理")
spider_data = pd.DataFrame(
{
"ID": [1, 2],
"名称": ["采集01", "采集02"],
"状态": [False, False],
}
)
spiders = st.data_editor(
spider_data,
width=500,
num_rows="dynamic",
disabled=["ID", "名称"],
)
status01 = spiders.iloc[0, 2]
status02 = spiders.iloc[1, 2]
if status01 != st.session_state.status01:
if status01: # 启动
print("启动采集01")
spider01_proc = multiprocessing.Process(target=spider01)
spider01_proc.daemon = True
spider01_proc.start()
st.session_state.proc01 = spider01_proc
else:
print("停止采集01")
st.session_state.proc01.terminate()
st.session_state.proc01.join()
st.session_state.status01 = status01
if status02 != st.session_state.status02:
if status02: # 启动
print("启动采集02")
spider02_proc = multiprocessing.Process(target=spider02)
spider02_proc.daemon = True
spider02_proc.start()
st.session_state.proc02 = spider02_proc
else:
print("停止采集02")
st.session_state.proc02.terminate()
st.session_state.proc02.join()
st.session_state.status02 = status02
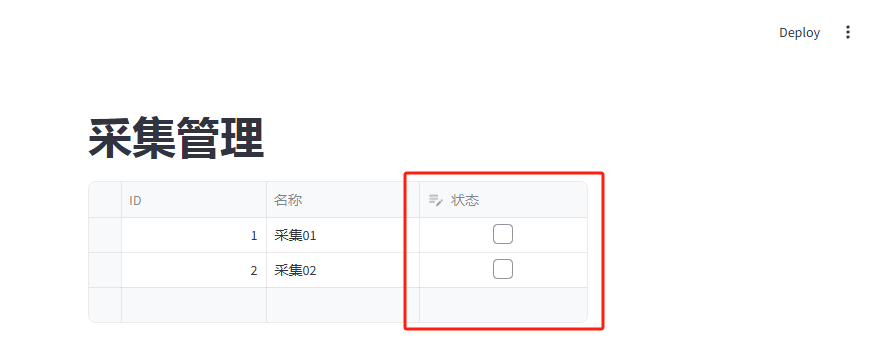
通过勾选状态列的Checkbox来控制采集程序的启停,运行的日志如下:
$ streamlit run .\app.py
You can now view your Streamlit app in your browser.
Local URL: http://localhost:8501
Network URL: http://192.168.0.6:8501
启动采集01
数据采集01...
数据采集01...
启动采集02
数据采集01...
数据采集02...
数据采集01...
数据采集02...
数据采集01...
数据采集02...
停止采集02
数据采集01...
停止采集01
3. 总结
通过Streamlit,可以快速的提供一个简单易用的数据采集控制界面。
上面使用sesstion来管理状态其实不太合理(重新打开浏览器session会丢失),使用sqlite之类的持久存储来保存更好。
标签:
相关文章
最新发布
- 光流法结合深度学习神经网络的原理及应用(完整代码都有Python opencv)
- Python 图像处理进阶:特征提取与图像分类
- 大数据可视化分析-基于python的电影数据分析及可视化系统_9532dr50
- 【Python】入门(运算、输出、数据类型)
- 【Python】第一弹---解锁编程新世界:深入理解计算机基础与Python入门指南
- 华为OD机试E卷 --第k个排列 --24年OD统一考试(Java & JS & Python & C & C++)
- Python已安装包在import时报错未找到的解决方法
- 【Python】自动化神器PyAutoGUI —告别手动操作,一键模拟鼠标键盘,玩转微信及各种软件自动化
- Pycharm连接SQL Sever(详细教程)
- Python编程练习题及解析(49题)
点击排行
- 版本匹配指南:Numpy版本和Python版本的对应关系
- 版本匹配指南:PyTorch版本、torchvision 版本和Python版本的对应关系
- Anaconda版本和Python版本对应关系(持续更新...)
- 相关性分析——Pearson相关系数+热力图(附data和Python完整代码)
- Python 可视化 web 神器:streamlit、Gradio、dash、nicegui;低代码 Python Web 框架:PyWebIO
- Windows上安装 Python 环境并配置环境变量 (超详细教程)
- Python与PyTorch的版本对应
- 安装spacy+zh_core_web_sm避坑指南
本站推荐
