首页 > Python资料 博客日记
Python标准数据类型-String(字符串)
2024-03-08 09:00:04Python资料围观209次
✅作者简介:CSDN内容合伙人、阿里云专家博主、51CTO专家博主、新星计划第三季python赛道Top1
📃个人主页:hacker707的csdn博客
🔥系列专栏:零基础入门篇
💬个人格言:不断的翻越一座又一座的高山,那样的人生才是我想要的。这一马平川,一眼见底的活,我不想要,我的人生,我自己书写,余生很长,请多关照,我的人生,敬请期待

Python字符串最强学习宝典
✨字符串简介
在Python程序中,字符串类型'str'是最常用的数据类型。
可以使用单引号'' 双引号"" 三引号''''''来创建字符串。(单引号,双引号创建的字符串只能在一行,三引号创建的字符串可以分布在多行)
创建字符串的方法很简单,只需要为变量分配一个值即可
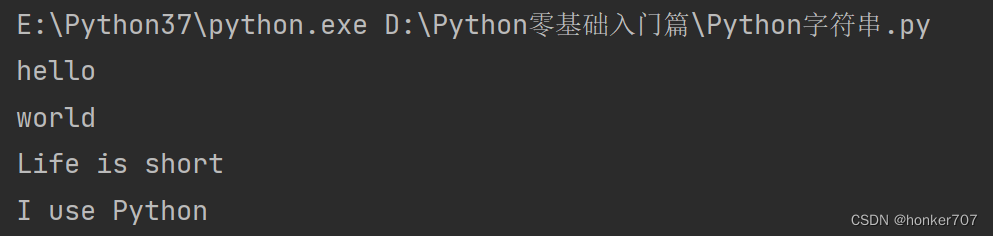
demo = 'hello' # 用单引号创建字符串
demo1 = "world" # 用双引号创建字符串
demo2 = '''Life is short
I use Python
''' # 用三引号创建字符串
print(demo)
print(demo1)
print(demo2)
运行结果如下:
✨字符串编码转换
- 最早出现的字符串编码是
美国标准信息交换码(ASCLL码)ASCLL码最多只能表示256个字符,每个字符占一个字节 - 随着信息技术的快速发展,各国的文字都需要进行编码,于是出现了
GBK、GB2312、UTF-8等。 GBK、GB2312是我国指定的中文编码标准(使用1个字节表示英文字母,2个字节表示中文字符)UTF-8是国际通用的编码,对全世界所有国家使用的字符进行编码(使用1个字节表示英文字母,3个字节表示中文字符)- 在Python3.x中,默认采用的编码格式为UTF-8,采用这种编码格式能有效解决中文乱码问题
在python中,有两种常见的字符串类型,分别是str和bytes
str表示Unicode字符(ASCLL或其他)bytes表示二进制数据(包括编码的文本)
这两种类型的字符串不能拼接在一起使用
通常情况下,str在内存中以Unicode表示(一个字符对应若干个字节)但如果在网络中传输,或者保存到磁盘上,就需要把str转换为字节(byte)类型
str和bytes之间可以通过encode()和decode()方法进行转换
使用encode()方法解码
encode方法为str对象的方法,用于将字符串转换为二进制数据(bytes),也称为编码。
其语法格式为:str.encode(encoding="utf-8", errors="strict")
参数说明如下:
str:表示要转换的字符串encoding="utf-8":可选参数,用于置顶进行转码时采用的字符编码,默认为utf-8,也可以设置为GB2312、GBK。当只有一个参数时,也可以省略encoding=,直接写编码errors="strict":可选参数,用于指定错误处理方式,默认为strict(遇到非法字符就抛出异常),也可以设置为ignore(忽略非法字符)replace(用"?"替换非法字符)xmlcharrfreplace(使用XML的字符串引用)等
注意事项:
在使用encode()方法时,不会修改原字符串,如果打印原字符串会恢复原状。
实例:定义一个名为demo的字符串,内容为"但行好事莫问前程",然后使用encode()方法将其采用UTF-8编码转换为二进制数据,并输出原字符串内容和转换后的内容
demo = "但行好事莫问前程"
res = demo.encode("UTF-8")
print("原字符串:" + demo)
print("转换后的二进制数据:", res)
运行结果如下:

使用decode()方法解码
decode()方法为bytes对象的方法,用于将二进制数据转换为字符串,即将使用encode()方法转换的结果再转换为字符串就是解码。
其语法格式为bytes.decode(encoding="utf-8", errors="strict")
参数说明如下:
bytes:表示要进行转换的二进制数据,通常是encode()方法转换的结果。encoding="utf-8":可选参数,用于置顶进行转码时采用的字符编码,默认为utf-8,也可以设置为GB2312、GBK。当只有一个参数时,也可以省略encoding=,直接写编码errors="strict":可选参数,用于指定错误处理方式,默认为strict(遇到非法字符就抛出异常),也可以设置为ignore(忽略非法字符)replace(用"?"替换非法字符)xmlcharrfreplace(使用XML的字符串引用)等。
注意事项:
- 在设置解码采用的字符编码时,需要与编码时采用的字符编码一致。
- 在使用decode()方法时,不会修改原字符串,如果打印原字符串会恢复原状。
实例:将上方实例encode()编码后的二进制数据进行解码,输出原字符串内容、编码后的内容、解码后的内容。
demo = "但行好事莫问前程"
res = demo.encode("UTF-8")
res1 = res.decode("UTF-8")
print("原字符串:" + demo)
print("编码后的二进制数据:", res)
print("解码后的字符串数据:" + res1)
运行结果如下:

✨字符串运算符
| 操作符 | 描述 |
|---|---|
| + | 连接字符串 |
| * | 重复输出字符串 |
| [] | 通过索引获取字符串中的字符 |
| [:] | 截取字符串一部分,遵循左闭右开原则 |
| in | 成员运算符(如果字符串中包含指定的字符返回true) |
| not in | 成员运算符(如果字符串中不包含指定的字符返回true) |
| r/R | 原始字符串(所有字符串都是直接使用,没有转义或不能打印的字符) |
| % | 格式化字符 |
- 重复输出字符串
*
demo = "Hacker"
print(demo * 7)

- 成员运算符
in
demo = "Hacker"
if "H" in demo:
print("H在变量demo里")

- 成员运算符
not in
demo = "Hacker"
if "Q" not in demo:
print("Q不在变量demo里")

- 原始字符串
r/R
print(r"\n")
print(R"\t")

✨格式化输出
使用%操作符
常用的格式化字符见下表
| 格式化字符 | 说明 |
|---|---|
| %s | 字符串 |
| %c | 单个字符 |
| %d | 十进制整数 |
| %x | 十六进制整数 |
| %f | 浮点数 |
| %o | 八进制整数 |
实例:
# 字符串
print("hacker%s" % "嘎嘎宠粉")
# 数字
print("今天走了%d步" % 777)

注意事项:
- 由于使用%操作符进行格式化是早期python中提供的方法,在python2.6版本开始,字符串对象提供了format()方法对字符串进行格式化
- 使用%操作符进行格式化仅了解即可,
推荐使用format()方法
使用字符串对象的format()方法(推荐使用)
字符串对象提供了format()方法用于字符串格式化
format()方法语法格式:str.format(args)
参数说明如下:
str:用于指定字符串的显示格式(即模板)args:用于指定要转换的项(如果有多项,用逗号隔开)
下面重点介绍创建模板。在创建模板时,需要使用"{}“和”:"指定占位符
创建模板语法格式:{ [index][ : [ [fill] align] [sign] [#] [width] [.precision] [type] ] }
参数说明如下:
index:可选参数,指定后边设置的格式要作用到 args 中第几个数据,数据的索引值从 0 开始。如果省略此选项,则会根据 args 中数据的先后顺序自动分配。fill:可选参数,指定空白处填充的字符。注意,当填充字符为逗号(,)且作用于整数或浮点数时,该整数(或浮点数)会以逗号分隔的形式输出,例如(1000000会输出 1,000,000)。align:可选参数,指定数据的对齐方式,具体的对齐方式见下表所示
| align | 含义 |
|---|---|
| < | 数据左对齐 |
| > | 数据右对齐 |
| = | 数据右对齐,只对数字类型有效,将数字放在填充字符的最左侧 |
| ^ | 数据居中,此项需和width参数一起使用 |
sign:可选参数,用于指定有无符号数,此参数值以及对应含义见下表所示
| sign | 含义 |
|---|---|
| + | 正数前加正号,负数前加负号 |
| - | 正数前不加正号,负数前加负号 |
| 空格 | 正数前加空格,负数前加负号 |
| # | 对于二进制数、八进制数和十六进制数,如果加上#,各进制数前会分别显示 0b、0o、0x前缀;反之则不显示前缀 |
width:可选参数,指定输出数据时所占的宽度。precision:可选参数,指定保留的小数位数。type:可选参数,用于指定类型
format()方法中常用的格式化字符见下表所示:
| 格式化字符 | 说明 |
|---|---|
| s | 对字符串类型格式化 |
| d | 十进制整数 |
| c | 将十进制整数自动转换成对应的 Unicode 字符 |
| e 或者 E | 转换为科学计数法后,再格式化输出 |
| g 或 G | 自动在e和f(或E和F)中切换 |
| b | 将十进制数自动转换成二进制表示,再格式化输出 |
| o | 将十进制数自动转换成八进制表示,再格式化输出 |
| x或X | 将十进制数自动转换成十六进制表示,再格式化输出 |
| f或F | 转换为浮点数(默认小数点后保留6位),再格式化输出 |
| % | 显示百分比(默认显示小数点后6位 |
在Python中,可以使用字符串中的format()方法来格式化字符串。format()方法可以将一个或者多个参数动态的插入到格式化字符串中。
实例一:使用format()和使用f.string
name = "hacker"
age = 20
res = "My name is {}, I am {} years old.".format(name, age)
print(res)
在上面的代码中,我们定义了一个字符串res使用了两个占位符{},然后调用format()方法将name和age两个参数传入。输出结果如下:

我们还可以使用大括号{}中的数字来指定参数的位置:
name = "hacker"
age = 20
res = "My name is {0}, I am {1} years old.".format(name, age)
print(res)
在{0}中的0代表传入的第一个参数name,在{1}中的1代表传入的第二个参数age,输出结果如下:

除了使用.format()以外,还可以使用f.string来进行更简洁,易读的输出
name = "hacker"
age = 20
print(f"My name is {name} and I am {age} years old.")

实例二:打印Python官网地址
demo = "网站名称:{:s}\n网址:{:s}"
print(demo.format("Python官网", "https://www.python.org/"))
运行结果如下:

实例三:在实际开发过程中,很多时候需要处理数据,可以使用format()方法对数值类型进行不同的输出(例如:货币形式、百分比形式、进制转换形式等)
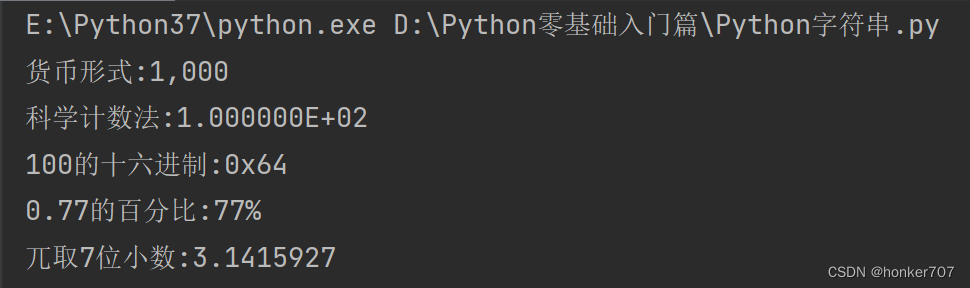
# 导入python数学模块math
import math
# 以货币形式显示
print("货币形式:{:,d}".format(1000))
# 科学计数法表示
print("科学计数法:{:E}".format(100))
# 以十六进制表示
print("100的十六进制:{:#x}".format(100))
# 输出百分比形式
print("0.77的百分比:{:.0%}".format(0.77))
# 兀取7位小数表示
print("兀取7位小数:{:.7f}".format(math.pi))
运行结果如下:
✨截取字符串(索引和切片)
由于字符串也属于序列,所以要截取字符串,可以采用切片方法实现
通过切片方法截取字符串的语法格式:string(start:end:step)
参数说明如下:
string:要截取的字符串start:要截取的第一个字符索引(包括该字符),如果不指定默认为0end:要截取的最后一个字符索引(不包括该字符),如果不指定默认为字符串的长度step:切片的步长(如果省略默认为1,当忽略步长时,最后一个冒号也可以省略)
实例:定义一个字符串,利用切片方法截取不同长度的子字符串
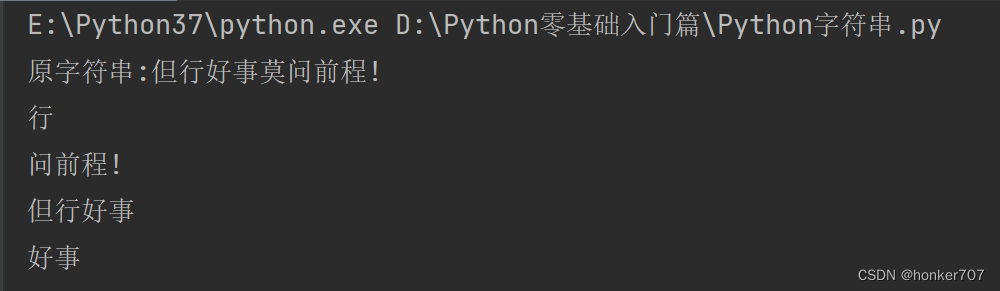
demo = "但行好事莫问前程!"
res1 = demo[1] # 截取第二个字符
res2 = demo[5:] # 从第6个字符开始截取
res3 = demo[:4] # 从左边开始截取4个字符
res4 = demo[2:4] # 截取第3个到第4个字符
print("原字符串:" + demo)
print(res1 + "\n" + res2 + "\n" + res3 + "\n" + res4 + "\n")
运行结果如下:
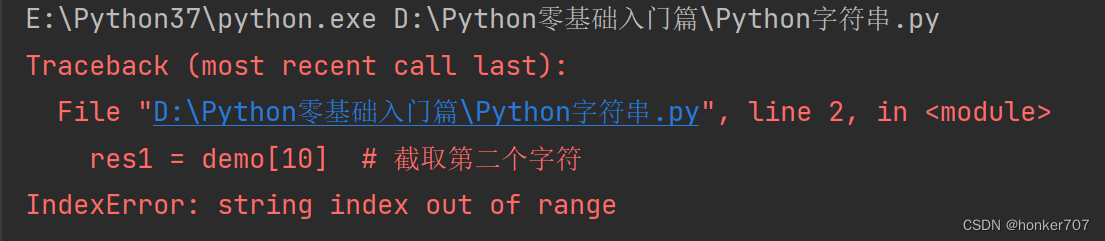
注意事项:
在进行字符串截取时,如果指定的索引不存在,就会抛出异常
IndexError: string index out of range:超出字符串索引范围
这时我们可以使用try...except语句去捕获异常(关于异常处理的讲解后面的文章里会讲到)
demo = "但行好事莫问前程!"
try:
res1 = demo[10]
except IndexError:
print("索引不存在")
这时再运行,即使超出范围也不会抛异常:

结束语🥇
以上就是Python基础入门篇之Python标准数据类型-String(字符串)
欢迎大家订阅系列专栏:Python零基础入门篇🥇此专栏内容会持续更新直到完结为止(如有任何纰漏请在评论区留言或者私信)
感谢大家一直以来对hacker的支持
你们的支持就是博主无尽创作的动力💖💖💖

标签:
相关文章
最新发布
- 光流法结合深度学习神经网络的原理及应用(完整代码都有Python opencv)
- Python 图像处理进阶:特征提取与图像分类
- 大数据可视化分析-基于python的电影数据分析及可视化系统_9532dr50
- 【Python】入门(运算、输出、数据类型)
- 【Python】第一弹---解锁编程新世界:深入理解计算机基础与Python入门指南
- 华为OD机试E卷 --第k个排列 --24年OD统一考试(Java & JS & Python & C & C++)
- Python已安装包在import时报错未找到的解决方法
- 【Python】自动化神器PyAutoGUI —告别手动操作,一键模拟鼠标键盘,玩转微信及各种软件自动化
- Pycharm连接SQL Sever(详细教程)
- Python编程练习题及解析(49题)
点击排行
- 版本匹配指南:Numpy版本和Python版本的对应关系
- 版本匹配指南:PyTorch版本、torchvision 版本和Python版本的对应关系
- Anaconda版本和Python版本对应关系(持续更新...)
- 相关性分析——Pearson相关系数+热力图(附data和Python完整代码)
- Python 可视化 web 神器:streamlit、Gradio、dash、nicegui;低代码 Python Web 框架:PyWebIO
- Windows上安装 Python 环境并配置环境变量 (超详细教程)
- Python与PyTorch的版本对应
- 安装spacy+zh_core_web_sm避坑指南
本站推荐
