首页 > Python资料 博客日记
Python 爬虫零基础教程(1):爬单个图片
2024-03-13 11:00:03Python资料围观306次
代码:
import requests
url = 'https://cdn.pixabay.com/photo/2018/01/04/07/59/salt-3060093_960_720.jpg'
data = requests.get(url).content
f = open('1.jpg', 'wb')
f.write(data)
f.close()
print('OK')
解释代码
变量
代码中的 url、data、f 都是变量,也可以给他们取别的名字:a、b、c,或者x、y、z 都可以
url = 'https://cdn.pixabay.com/photo/2018/01/04/07/59/salt-3060093_960_720.jpg'
这行代码表示把图片的网址赋值给变量 url。
在之后的代码中 url 就代指这个网址。
Python 用等号=来给变量赋值,等号左边是变量名,等号右边是存储在变量中的值。
Python 的变量赋值不需要声明变量类型。
变量命名规则:
- 只能包含字母、数字和下划线,并且不能以数字开头。
- 区分大小写字母,如果写错了大小写,程序会报错。
- 不能使用保留字
通常以“小写字母,单词之间用 _ 分割”的方式来给普通变量名。
this_is_a_var
字符串
'https://cdn.pixabay.com/photo/2018/01/04/07/59/salt-3060093_960_720.jpg'
就是字符串。
在 Python 中,可以用成对的单引号( ' )、双引号( " )、三引号( ''' 或 """ ) 来表示字符串,其中三引号可以跨行。
字符串是编程语言中表示文本的数据类型。
requests 库
使用之前要先导入import requests 。(别的Python编程工具需要先安装 requests,Anaconda不用)
data = requests.get(url).content
可以分成两段:
response = requests.get(url)
data = response.content
response 和 data 当然都是变量
response = requests.get() 表示使用requests库的get函数,获取网页,并赋值给变量 response
data = response.content 表示把变量response的数据以二进制的格式返回,赋值给变量data
requests.get(url).content 以后会经常用到。
文件的打开
f = open('1.jpg', 'wb')
这行代码表示在当前目录打开一个名为1.jpg 的文件,赋值给变量 f。如果该文件已存在则将其覆盖,如果该文件不存在,创建新文件。
函数 open() 的语法为: open(路径+文件名,读写模式)
如果没有“路径”则是在当前目录。当前目录的意思是包含这段代码的 .py 文件所在的文件夹。
路径+文件名 与 读写模式 都是字符串类型。
读写模式有很多种,写爬虫一般用 wb 模式:以二进制格式打开一个文件只用于写入,如果该文件已存在则将其覆盖,如果该文件不存在,创建新文件。
文件的写入
f.write(data)
表示将data写入 f 文件。
write() 方法,将字符串写入一个打开的文件。
文件的关闭
f.close()
表示关闭文件 f。文件打开后,无论进行读、写或其他什么操作,最后都要关闭。
输出到屏幕
print('OK')
在屏幕上输出字符串 OK。
print 用于打印输出。在 Python2.x 版本可以 print 'ok' 也可以 print('OK') ,而在 Python3.x 必须 print('OK') 。
这句代码的作用是告诉我们全部代码已经执行完毕,图片下载好了。没有这句也不影响下载图片。
Python 基础语法:
每一行是一个语句,语句无需以 ;结尾。不需要大括号 {} 来控制类、函数以及其他逻辑判断。
Python 用缩进表示逻辑层次。当语句以冒号 : 结尾时,下一行代码需要缩进。
没有规定缩进是几个空格还是Tab,但是所有代码的缩进必须相同。约定俗成是4个空格的缩进。
缩进很方便,但也有坏处,Python 代码“复制-粘贴”后需要重新检查缩进是否正确。
运行代码
打开Spyder,点击左上角的“新建”。
把最上面的代码复制到左边的编辑区,点击“运行”
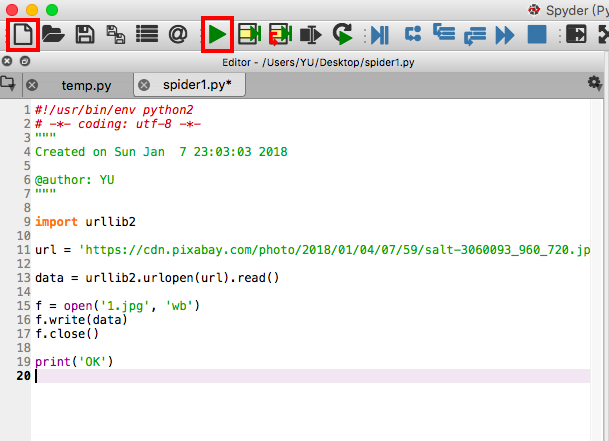
在弹出的对话框里输入文件名,以 .py 为后缀,选择存放位置,点击存储。
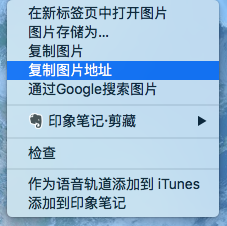
等待几秒钟,Spyder的右侧输出OK,说明图片下载成功。

图片下载到和上面的 .py 文件相同的目录。文件名为 1.jpg

好啦,第一个 Python 爬虫成功了。
可以把 url 的赋值改为其他图片的地址来下载其他图片。
如何获取图片地址:网页上右键点击图片,选择“复制图片地址”
你可能觉得用爬虫下载图片还不如手动下载方便。
因为这才刚刚开始,后面我们会给爬虫添加自动化,还可以进行筛选。
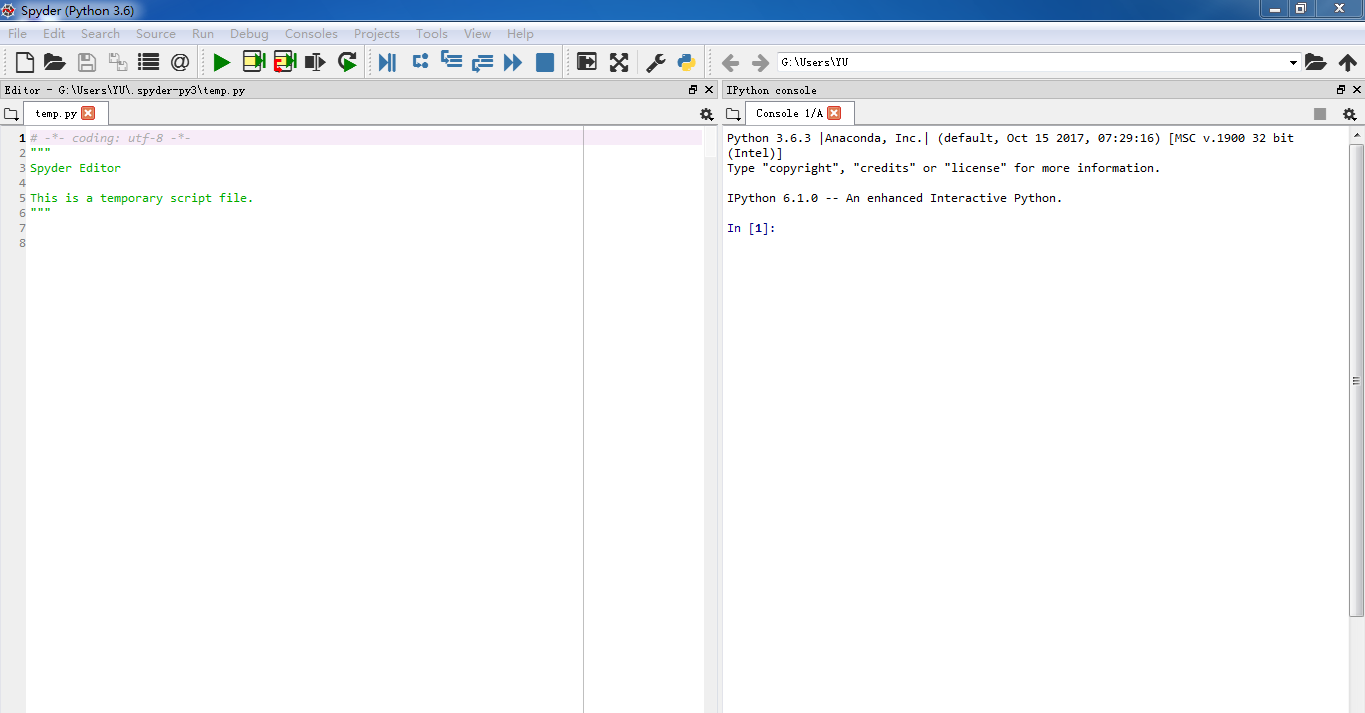
Spyder 简介

左边是代码编辑区。
右边下半部分是 Ipython ,左边代码的 print 都会显示在 Ipython。
Ipython 还可以进行一行行的交互。

右边的上半部分不常用,可以连续点击 X 将其关闭
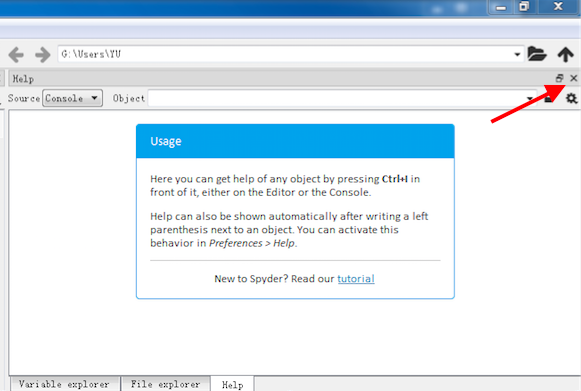
最后变成这样:
此文章是我原创,20180114 发布于我在其他平台的博客,现同步在此
我的公号:v1coder
我的博客:v1coder.com
我的GitHub:https://github.com/v1coder
标签:
相关文章
最新发布
- 光流法结合深度学习神经网络的原理及应用(完整代码都有Python opencv)
- Python 图像处理进阶:特征提取与图像分类
- 大数据可视化分析-基于python的电影数据分析及可视化系统_9532dr50
- 【Python】入门(运算、输出、数据类型)
- 【Python】第一弹---解锁编程新世界:深入理解计算机基础与Python入门指南
- 华为OD机试E卷 --第k个排列 --24年OD统一考试(Java & JS & Python & C & C++)
- Python已安装包在import时报错未找到的解决方法
- 【Python】自动化神器PyAutoGUI —告别手动操作,一键模拟鼠标键盘,玩转微信及各种软件自动化
- Pycharm连接SQL Sever(详细教程)
- Python编程练习题及解析(49题)
点击排行
- 版本匹配指南:Numpy版本和Python版本的对应关系
- 版本匹配指南:PyTorch版本、torchvision 版本和Python版本的对应关系
- Anaconda版本和Python版本对应关系(持续更新...)
- 相关性分析——Pearson相关系数+热力图(附data和Python完整代码)
- Python 可视化 web 神器:streamlit、Gradio、dash、nicegui;低代码 Python Web 框架:PyWebIO
- Windows上安装 Python 环境并配置环境变量 (超详细教程)
- Python与PyTorch的版本对应
- 安装spacy+zh_core_web_sm避坑指南
本站推荐
