首页 > Python资料 博客日记
pandas DataFrame内存优化技巧:让数据处理更高效
2024-03-14 14:00:03Python资料围观277次
Pandas无疑是我们数据分析时一个不可或缺的工具,它以其强大的数据处理能力、灵活的数据结构以及易于上手的API赢得了广大数据分析师和机器学习工程师的喜爱。
然而,随着数据量的不断增长,如何高效、合理地管理内存,确保Pandas DataFrame在运行时不会因内存不足而崩溃,成为我们每一个人必须面对的问题。
在这个信息爆炸的时代,数据规模呈指数级增长,如何优化内存使用,不仅关乎到程序的稳定运行,更直接关系到数据处理的效率和准确性。通过本文,你将了解到一些实用的内存优化技巧,帮助你在处理大规模数据集时更加得心应手。
1. 准备数据
首先,准备一些包含各种数据类型的测试数据集。
封装一个函数(fake_data),用来生成数据集,数据集中包含后面用到的几种字段。
import pandas as pd
import numpy as np
def fake_data(size):
"""
根据测试数据集:
age:整数类型数值
grade:有限个数的字符串
qualified:是否合格
ability:能力评估,浮点类型数值
"""
df = pd.DataFrame()
df["age"] = np.random.randint(1, 30, size)
df["grade"] = np.random.choice(
[
"一年级",
"二年级",
"三年级",
"四年级",
"五年级",
"六年级",
],
size,
)
df["qualified"] = np.random.choice(["合格", "不合格"], size)
df["ability"] = np.random.uniform(0, 1, size)
return df
2. 检测内存占用
使用上面封装的函数(fake_data)先构造一个包含一百万条数据的DataFrame。
df = fake_data(1_000_000)
df.head()
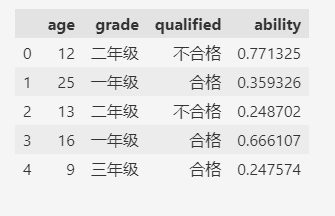
看看优化前的内存占用情况:
df.info()
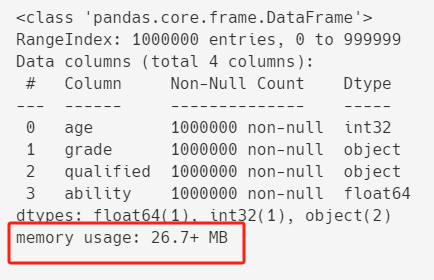
内存占用大约 26.7MB 左右。
3. 优化内存
接下来,我们开始一步步优化DataFrame的内存占用,
并测试每一步优化之后的内存使用情况和运行性能变化。
3.1. 优化整型数据
首先,优化整型数据的内存占用,也就是测试数据中的年龄(age)字段。
从上面df.info()的结果中,我们可以看出,age的类型是int32(也就是用32位,8个字节来存储整数)。
对于年龄来说,用不到这么大的整数,用int8(数值范围:-128~127)来存储绰绰有余。
df["age"] = df["age"].astype("int8")
df.info()
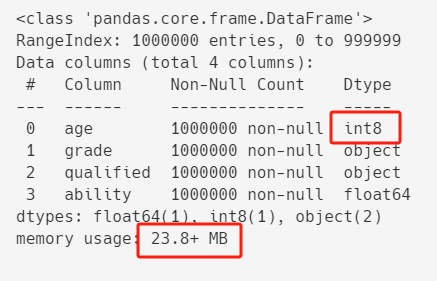
优化之后,内存占用从26.7+ MB减到23.8+ MB。
3.2. 优化浮点型数据
接下来优化浮点类型数据,也就是测试数据中的能力评估值(ability)。
测试数据中ability的值是6位小数,类型是float64,
转换成float16可能会改变值,所以这里转换成float32。
df["ability"] = df["ability"].astype("float32")
df.info()
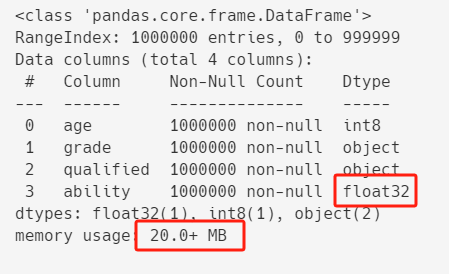
优化之后,内存占用进一步从23.8+ MB减到20.0+ MB。
3.3. 优化布尔型数据
接下来,优化测试数据中的是否合格(qualified),
这个值虽然是字符串类型,但是它的值只有两种(合格和不合格),所以可以转换成布尔类型。
df["qualified"] = df["qualified"].map({"合格": True, "不合格": False})
df.info()
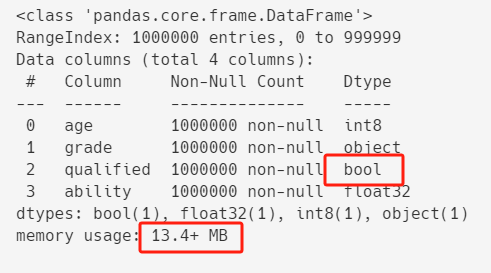
优化之后,内存占用进一步从20.0+ MB减到13.4+ MB。
3.4. 使用category类型
最后,我们再优化剩下的字段--年级(grade)。
这个字段也是字符串,不过它的值只有6个,虽然无法转换成布尔类型(布尔类型只有两种值True和False),但是它可以转换为pandas中的 category 类型。
df["grade"] = df["grade"].astype("category")
df.info()
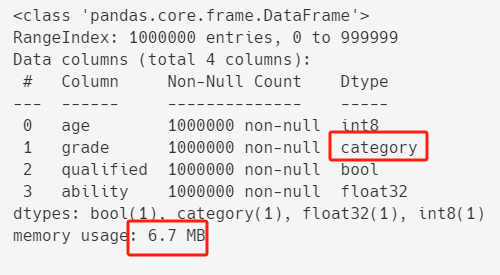
优化之后,内存占用进一步从13.4+ MB减到6.7+ MB。
4. 总结
各类字段优化之后,内存占用从刚开始的26.7+ MB减到6.7+ MB,优化的效果非常明显。
仅仅是数据类型的简单调整,就带来了如此之大的内存效率提升,
这也给我们带来启示,在数据分析的过程中,构造DataFrame时,也可以根据数值的范围,特点等,
来赋予它合适的类型,不要一味简单的使用字符串,或者默认的整数(int32),默认的浮点(float64)等类型。
标签:
相关文章
最新发布
- 光流法结合深度学习神经网络的原理及应用(完整代码都有Python opencv)
- Python 图像处理进阶:特征提取与图像分类
- 大数据可视化分析-基于python的电影数据分析及可视化系统_9532dr50
- 【Python】入门(运算、输出、数据类型)
- 【Python】第一弹---解锁编程新世界:深入理解计算机基础与Python入门指南
- 华为OD机试E卷 --第k个排列 --24年OD统一考试(Java & JS & Python & C & C++)
- Python已安装包在import时报错未找到的解决方法
- 【Python】自动化神器PyAutoGUI —告别手动操作,一键模拟鼠标键盘,玩转微信及各种软件自动化
- Pycharm连接SQL Sever(详细教程)
- Python编程练习题及解析(49题)
点击排行
- 版本匹配指南:Numpy版本和Python版本的对应关系
- 版本匹配指南:PyTorch版本、torchvision 版本和Python版本的对应关系
- Anaconda版本和Python版本对应关系(持续更新...)
- 相关性分析——Pearson相关系数+热力图(附data和Python完整代码)
- Python 可视化 web 神器:streamlit、Gradio、dash、nicegui;低代码 Python Web 框架:PyWebIO
- Windows上安装 Python 环境并配置环境变量 (超详细教程)
- Python与PyTorch的版本对应
- 安装spacy+zh_core_web_sm避坑指南
本站推荐
