首页 > Python资料 博客日记
【Python数分实战】预测肥胖风险数据
2024-07-01 06:00:05Python资料围观184次
📣 前言
- 👓 可视化主要使用 plotly
- 🔎 数据处理主要使用 pandas
- 🕷️ 数据爬取主要使用 requests
- 👉 本文是我自己在和鲸社区的原创
今天这篇文章将给大家介绍【关于肥胖风险数据集】案例。
Step 1. 导入模块
import pandas as pd
import plotly.graph_objects as go
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, accuracy_score
import numpy as np
Step 2. 数据概览
数据下载:关注公众号,回复关键字【肥胖风险数据集】免费获取。
file_path = '/home/mw/input/shein9661/shein_mens_fashion.csv'
df = pd.read_csv(file_path)
df.head()
输出结果:

missing_values = data.isnull().sum()
duplicate_rows = data.duplicated().sum()
missing_values, duplicate_rows
输出结果:
(id 0
Gender 0
Age 0
Height 0
Weight 0
family_history_with_overweight 0
FAVC 0
FCVC 0
NCP 0
CAEC 0
SMOKE 0
CH2O 0
SCC 0
FAF 0
TUE 0
CALC 0
MTRANS 0
0be1dad 0
dtype: int64, 0)
Step 2. 相关性分析
correlation_matrix = data.corr()
correlation_matrix
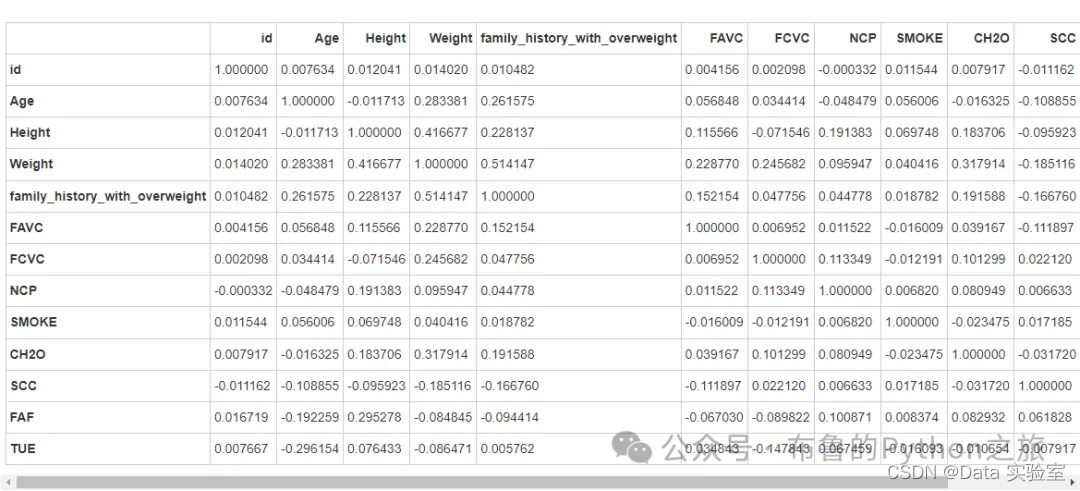
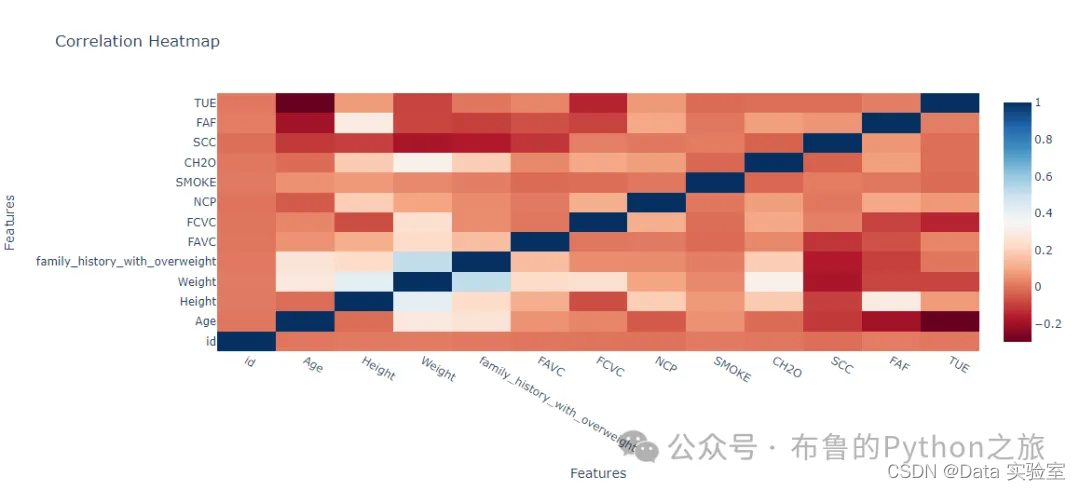
上面的热力图展示了数据集中各特征之间的相关性。每个单元格的颜色代表相应特征对之间的相关系数,颜色越暖表示相关性越强,颜色越冷表示相关性越弱。图中的中心线表示相关系数为0,即没有相关性。
相关性分析已完成,以下是一些关键观察结果:
- 年龄(Age)与体重(Weight)之间存在较强的正相关关系,相关系数约为 0.283。
- 身高(Height)与体重(Weight)之间也存在较强的正相关关系,相关系数约为 0.417。
- 家族肥胖史(family_history_with_overweight)与体重(Weight)之间存在较强的正相关关系,相关系数约为 0.514。
- 食用蔬菜的频次(FCVC)与体重(Weight)之间存在正相关关系,相关系数约为 0.246。
- 高热量饮料消耗量(SCC)与体重(Weight)之间存在负相关关系,相关系数约为 -0.185。
- 运动频率(FAF)与体重(Weight)之间存在负相关关系,相关系数约为 -0.085。
- 使用电子设备的时间(TUE)与体重(Weight)之间存在负相关关系,相关系数约为 -0.086。
这些结果表明,年龄、身高、家族肥胖史、食用蔬菜的频次、高热量饮料消耗量、运动频率以及使用电子设备的时间都与体重有一定的相关性。这些信息可能有助于了解不同因素如何影响个人的体重水平。如果您需要更详细的分析或有其他问题,请告诉我。
from plotly.subplots import make_subplots
fig2 = make_subplots(specs=[[{"secondary_y":True}]])
fig2.add_trace(
go.Scatter(x=df_sorted["name"],y=df_sorted["scoreAvg"],name="平均分"),secondary_y=True
)
fig2.add_trace(
go.Bar(x=df_sorted["name"],y=df_sorted["scorePersonCount"],name="评分人数",)
)
fig2.update_yaxes(go.layout.YAxis(tickformat="",showgrid=False),secondary_y=True)
fig2.update_layout(go.Layout(title=go.layout.Title(text="虎扑评分人数Top20")),template="plotly_white",)
输出结果:
《》
Step 3. 群体特征分析
Step 3.1 性别分布
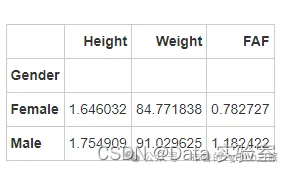
grouped_data[['Height', 'Weight', 'FAF']]
输出结果:
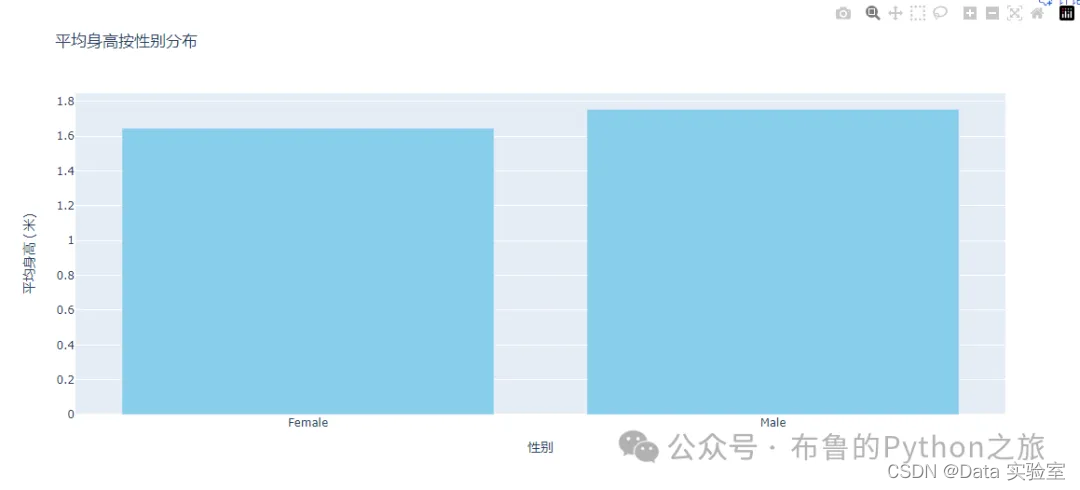
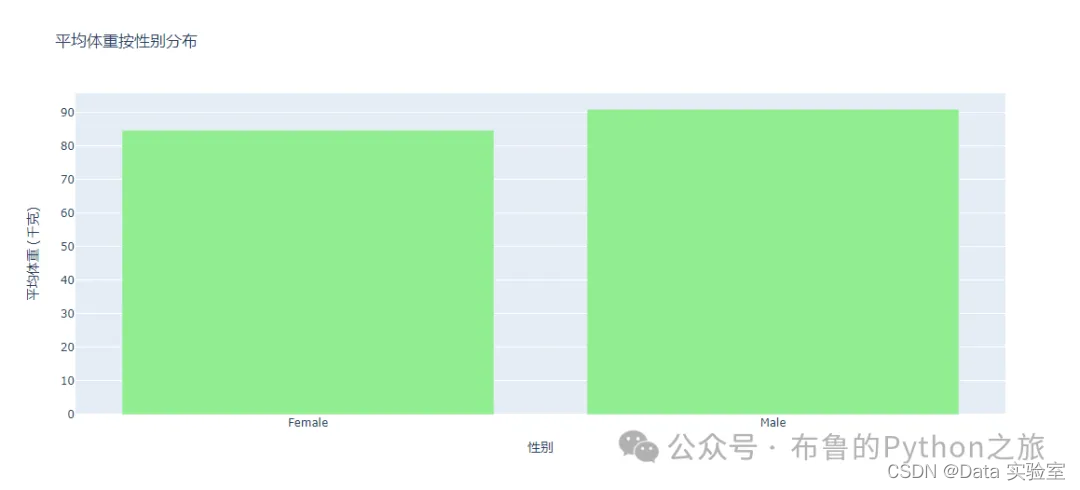
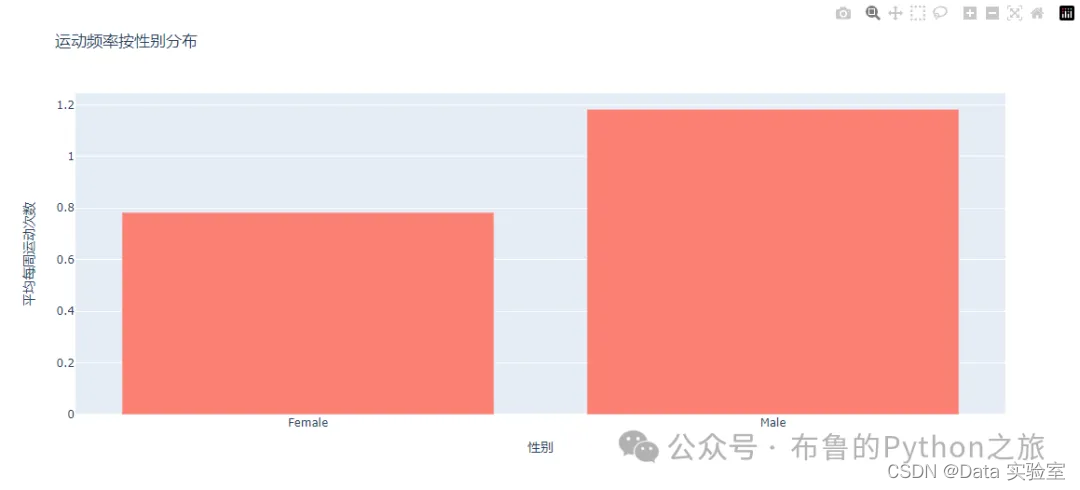
以下是按性别分组的平均身高、体重和运动频率的对比:
- 平均身高:
- 女性:约1.65米
- 男性:约1.75米
- 平均体重:
- 女性:约84.77千克
- 男性:约91.03千克
- 平均每周运动次数:
- 女性:约0.78次
- 男性:约1.18次
图表显示了男性和女性在不同特征上的平均值和95%置信区间。从图表和数值中可以看出,男性在身高和体重上普遍高于女性,并且每周的运动频率也略高于女性。这些信息有助于我们了解不同性别之间在健康和生活方式方面的差异。
Step 3.2 肥胖水平分布
# 计算不同肥胖水平的分布
obesity_distribution = data['0be1dad'].value_counts(normalize=True) * 100 # 标准化为百分比
# 创建肥胖水平分布的柱状图
fig = go.Figure(data=[
go.Bar(x=obesity_distribution.index, y=obesity_distribution, marker_color='skyblue')
])
# 更新布局
fig.update_layout(
title='肥胖水平分布',
xaxis=dict(title='肥胖水平'),
yaxis=dict(title='百分比 (%)'),
xaxis_tickangle=-45
)
# 显示图形
fig.show()
输出结果:
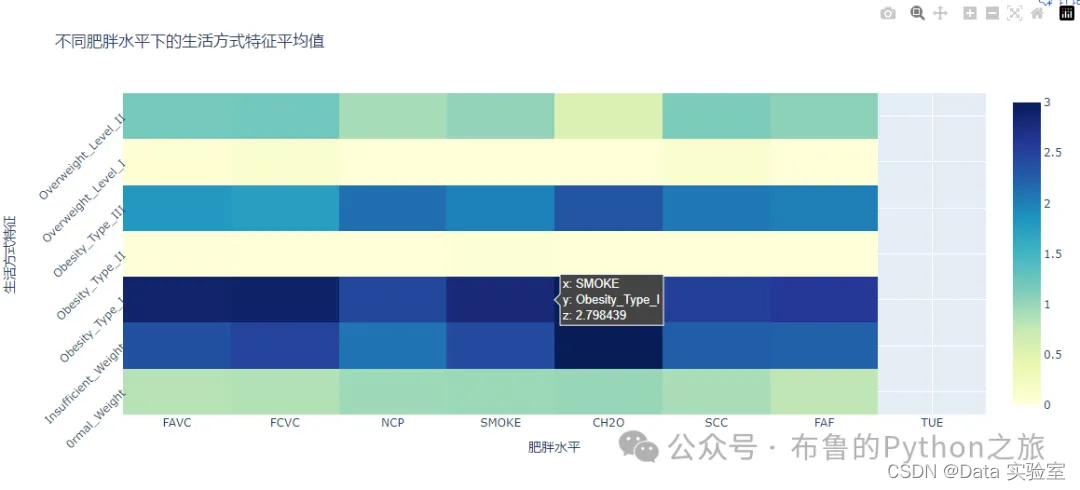
# 比较不同肥胖水平下的生活方式特征
lifestyle_columns = ['FAVC', 'FCVC', 'NCP', 'SMOKE', 'CH2O', 'SCC', 'FAF', 'TUE', 'CALC']
lifestyle_data = data[lifestyle_columns + ['0be1dad']]
# 根据肥胖水平分组并计算每种生活方式特征的平均值
lifestyle_means = lifestyle_data.groupby('0be1dad').mean()
输出结果:
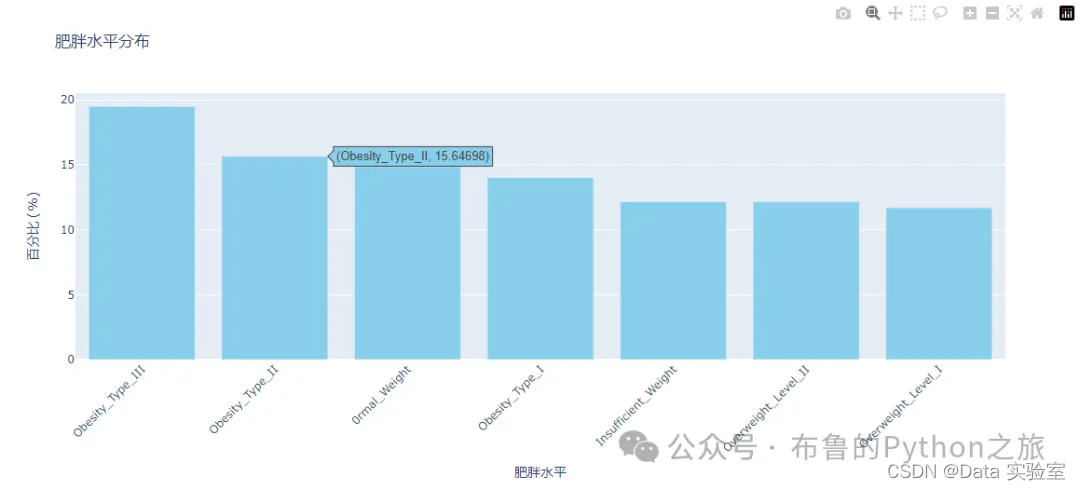
根据数据分析,不同肥胖水平的分布情况如下:
- 正常体重(0rmal_Weight):占比约14.85%
- 体重不足(Insufficient_Weight):占比约12.15%
- 肥胖类型 I(Obesity_Type_I):占比约14.02%
- 肥胖类型 II(Obesity_Type_II):占比约15.65%
- 肥胖类型 III(Obesity_Type_III):占比约19.49%
- 一级超重(Overweight_Level_I):占比约11.69%
- 二级超重(Overweight_Level_II):占比约12.15%
从热图中我们可以观察到不同肥胖水平的人群在生活方式特征上的差异:
- 频繁食用高热量食物(FAVC):随着肥胖水平的增加,这一指标呈上升趋势,表明肥胖程度越高的人越可能频繁食用高热量食物。
- 食用蔬菜的频次(FCVC):肥胖类型III的人群报告称他们每周都会食用蔬菜,这可能是由于他们在努力改善饮食习惯。
- 食用主餐的次数(NCP):肥胖类型III的人每周食用主餐的次数接近三次,这可能反映了他们饮食习惯的一部分。
- 每日耗水量(CH2O):肥胖类型III的人平均每日耗水量较高,这可能与他们的饮食和运动习惯有关。
- 高热量饮料消耗量(SCC):肥胖类型I和II的人很少消耗高热量饮料,而其他水平的人群则有所增加。
- 运动频率(FAF):肥胖类型III的人每周运动频率最低,这可能与他们的肥胖水平有关。
- 使用电子设备的时间(TUE):肥胖类型III的人使用电子设备的时间相对较短,这可能与他们的生活方式有关。
这些观察结果表明,肥胖水平与饮食习惯、运动频率和生活方式因素之间存在一定的关联。通过进一步分析这些数据,我们可以为肥胖预防和健康促进提供有价值的见解。
Step 4. 构建肥胖风险预测模型
选择一个常用的机器学习算法来构建肥胖风险预测模型。考虑到这是一个分类问题,我们可以选择以下算法之一:
- 逻辑回归(Logistic Regression):这是一种广泛用于分类问题的算法,特别是当特征数量不是很大时。
- 决策树(Decision Tree):这是一种基于树结构的模型,易于理解和解释。
- 随机森林(Random Forest):这是一种集成算法,通过组合多个决策树来提高性能。
- 支持向量机(Support Vector Machine):这是一种强大的分类算法,特别是在特征维度较高时。
考虑到数据的特征数量和问题的复杂性,我将选择随机森林算法来构建模型。这种算法通常在分类问题上表现良好,并且可以处理特征之间的相互作用。
接下来,开始数据准备步骤,包括数据编码和划分训练集与测试集。然后,将使用随机森林算法来训练模型。
# 选择相关特征和目标变量
features = data[['Gender', 'Age', 'Height', 'Weight', 'family_history_with_overweight',
'FAVC', 'FCVC', 'NCP', 'CAEC', 'SMOKE', 'CH2O', 'SCC', 'FAF', 'TUE', 'CALC', 'MTRANS']]
target = data['0be1dad']
# 使用标签编码将分类变量转换为数值变量
categorical_features = ['Gender', 'CAEC', 'SMOKE', 'SCC', 'CALC', 'MTRANS']
label_encoders = {} # 存储标签编码器以备将来使用
for feature in categorical_features:
le = LabelEncoder()
features[feature] = le.fit_transform(features[feature])
label_encoders[feature] = le # 存储标签编码器以备将来使用
# 将数据拆分为训练集和测试集(80%训练,20%测试)
X_train, X_test, y_train, y_test = train_test_split(features, target, test_size=0.2, random_state=42)
rf = RandomForestClassifier(n_estimators=100, random_state=42)
rf.fit(X_train, y_train)
y_pred = rf.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
classification_rep = classification_report(y_test, y_pred)
accuracy
classification_rep
输出结果:
' precision recall f1-score support\n\n 0rmal_Weight 0.83 0.89 0.86 626\nInsufficient_Weight 0.95 0.91 0.93 524\n Obesity_Type_I 0.89 0.86 0.88 543\n Obesity_Type_II 0.98 0.98 0.98 657\n Obesity_Type_III 1.00 1.00 1.00 804\n Overweight_Level_I 0.76 0.74 0.75 484\nOverweight_Level_II 0.78 0.79 0.79 514\n\n accuracy 0.89 4152\n macro avg 0.88 0.88 0.88 4152\n weighted avg 0.90 0.89 0.89 4152\n'
模型构建和评估的结果如下:
- 模型准确率:随机森林模型的准确率为89.47%。
- 分类报告:模型在不同肥胖水平上的精确度、召回率和F1分数如下:
- 正常体重(0rmal_Weight):精确度83%,召回率89%,F1分数86%
- 体重不足(Insufficient_Weight):精确度95%,召回率91%,F1分数93%
- 肥胖类型 I(Obesity_Type_I):精确度89%,召回率86%,F1分数88%
- 肥胖类型 II(Obesity_Type_II):精确度98%,召回率98%,F1分数98%
- 肥胖类型 III(Obesity_Type_III):精确度100%,召回率100%,F1分数100%
- 一级超重(Overweight_Level_I):精确度76%,召回率74%,F1分数75%
- 二级超重(Overweight_Level_II):精确度78%,召回率79%,F1分数79%
这些结果表明,随机森林模型在预测不同肥胖水平方面表现良好,特别是在肥胖类型 II 和 III 上。然而,对于一些肥胖水平(如正常体重和一级超重),模型的性能可能还需要进一步优化。
完整代码👇
https://www.heywhale.com/mw/project/660b684a5c327bc57fd9fd74
ps:此代码可以直接在线运行,不需要担心环境配置问题
数据集下载
关注公众号,回复关键字【肥胖风险数据集】获取
- END -

👆 关注**「布鲁的Python之旅」**第一时间收到更新
标签:
相关文章
最新发布
- 【Python】selenium安装+Microsoft Edge驱动器下载配置流程
- Python 中自动打开网页并点击[自动化脚本],Selenium
- Anaconda基础使用
- 【Python】成功解决 TypeError: ‘<‘ not supported between instances of ‘str’ and ‘int’
- manim边学边做--三维的点和线
- CPython是最常用的Python解释器之一,也是Python官方实现。它是用C语言编写的,旨在提供一个高效且易于使用的Python解释器。
- Anaconda安装配置Jupyter(2024最新版)
- Python中读取Excel最快的几种方法!
- Python某城市美食商家爬虫数据可视化分析和推荐查询系统毕业设计论文开题报告
- 如何使用 Python 批量检测和转换 JSONL 文件编码为 UTF-8
点击排行
- 版本匹配指南:Numpy版本和Python版本的对应关系
- 版本匹配指南:PyTorch版本、torchvision 版本和Python版本的对应关系
- Python 可视化 web 神器:streamlit、Gradio、dash、nicegui;低代码 Python Web 框架:PyWebIO
- 相关性分析——Pearson相关系数+热力图(附data和Python完整代码)
- Anaconda版本和Python版本对应关系(持续更新...)
- Python与PyTorch的版本对应
- Windows上安装 Python 环境并配置环境变量 (超详细教程)
- Python pyinstaller打包exe最完整教程
本站推荐
