首页 > Python资料 博客日记
day33-Django3.2(二)
2024-07-02 09:30:03Python资料围观104次
四、视图
django的视图主要有2种,分别是函数视图和类视图.现在刚开始学习django,我们先学习函数视图(FBV),后面再学习类视图[CBV].
4.1、请求方式
web项目运行在http协议下,默认肯定也支持用户通过不同的http请求发送数据来。django支持让客户端只能通过指定的Http请求来访问到项目的视图
home/views.py,代码:
# 让用户发送POST才能访问的内容
from django.views.decorators.http import require_http_methods
@require_http_methods(["POST"])
def login(request):
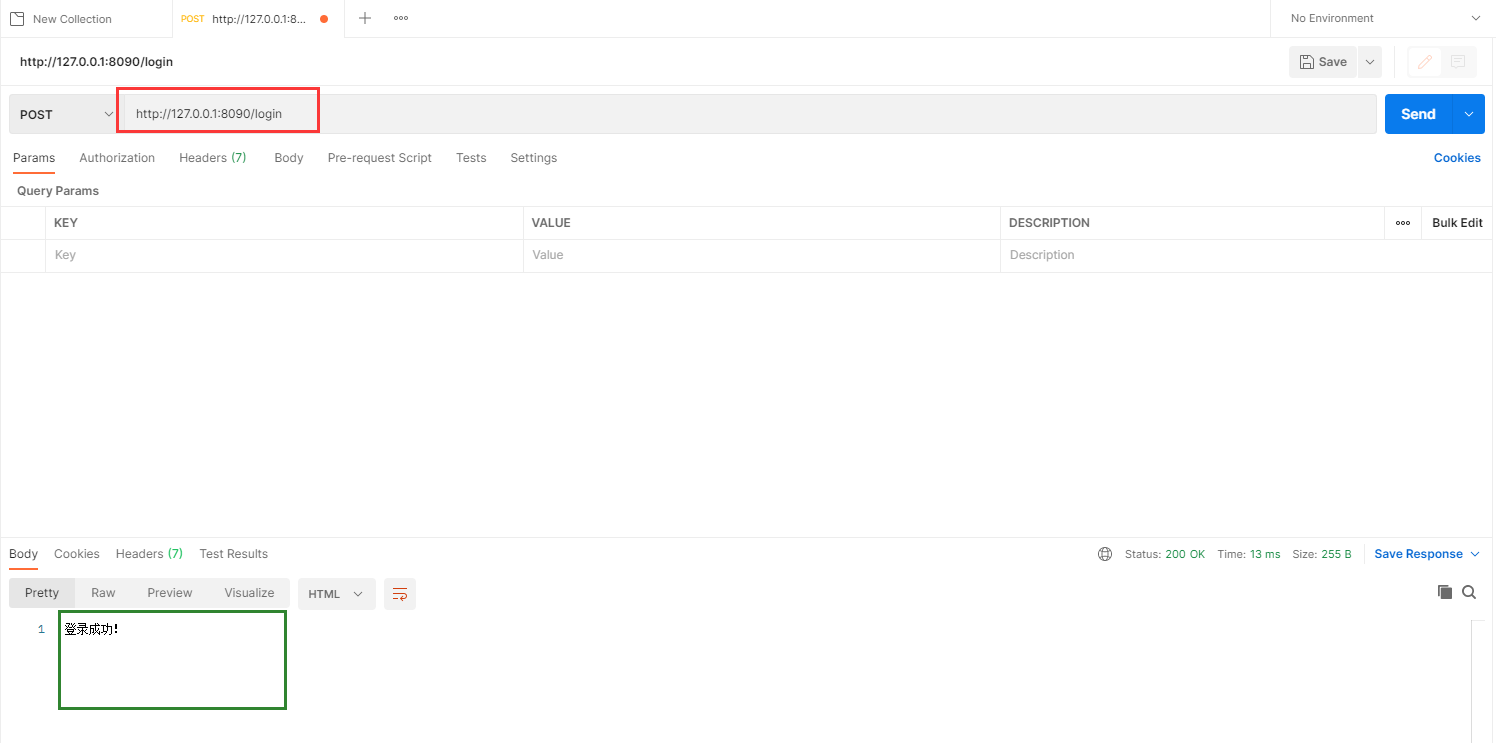
return HttpResponse("登录成功!")
路由绑定,demo/urls.py,代码:
from django.contrib import admin
from django.urls import path
from home.views import index
urlpatterns = [
path('admin/', admin.site.urls),
path("index", index),
path("login", login),
]
通过浏览器,访问效果http://127.0.0.1:8090/login:
4.2、请求对象
django将请求报文中的请求行、首部信息、内容主体封装成 HttpRequest 类中的属性。 除了特殊说明的之外,其他均为只读的。
(1)请求方式
print(request.method)
(2)请求数据
# 1.HttpRequest.GET:一个类似于字典的对象,包含 HTTP GET 的所有参数。详情请参考 QueryDict 对象。
# 2.HttpRequest.POST:一个类似于字典的对象,如果请求中包含表单数据,则将这些数据封装成 QueryDict 对象。
# 注意:键值对的值是多个的时候,比如checkbox类型的input标签,select标签,需要用: request.POST.getlist("hobby")
# 3.HttpRequest.body:一个字符串,代表请求报文的请求体的原数据。
(3)请求路径
# HttpRequest.path:表示请求的路径组件(不含get参数)
# HttpRequest.get_full_path():含参数路径
(4)请求头
# HttpRequest.META:一个标准的Python 字典,包含所有的HTTP 首部。具体的头部信息取决于客户端和服务器
4.3、响应对象
响应对象主要有三种形式:
- HttpResponse()
- render()
- redirect()
(1)HttpResponse()
Django服务器接收到客户端发送过来的请求后,会将提交上来的这些数据封装成一个 HttpRequest 对象传给视图函数。那么视图函数在处理完相关的逻辑后,也需要返回一个响应给浏览器。而这个响应,我们必须返回 HttpResponseBase 或者他的子类的对象。而 HttpResponse 则是 HttpResponseBase 用得最多的子类。
常用属性:
- content:返回的内容。
- status:返回的HTTP响应状态码。
- content_type:返回的数据的MIME类型,默认为 text/html 。浏览器会根据这个属性,来显示数据。如果是 text/html ,那么就会解析这个字符串,如果 text/plain ,那么就会显示一个纯文本。
- 设置响应头: response['X-Access-Token'] = 'xxxx' 。
return HttpResponse("ok")
return HttpResponse("您访问的资源不存在", status=404)
return HttpResponse("<h1>ok</h1>", content_type="text/plain")
res = HttpResponse("ok")
res["user"] = "yuan"
return res
JsonResponse类:
用来对象 dump 成 json 字符串,然后返回将 json 字符串封装成 Response 对象返回给浏览器。并且他的 Content-Type 是 application/json 。示例代码如下:
from django.http import JsonResponse
def index(request):
return JsonResponse({"title":"三国演义","price":199})
默认情况下 JsonResponse 只能对字典进行 dump ,如果想要对非字典的数据进行 dump ,那么需要给 JsonResponse 传递一个 safe=False 参数。示例代码如下:
books = [{"title": "西游记", "price": 99}, {"title": "水浒传", "price": 199}]
return JsonResponse(books, safe=False)
(2)render()
render(request, template_name[, context])
#结合一个给定的模板和一个给定的上下文字典,并返回一个渲染后的 HttpResponse 对象。
参数:
/*
request: 用于生成响应的请求对象。
template_name:要使用的模板的完整名称,可选的参数
context:添加到模板上下文的一个字典,
默认是一个空字典。如果字典中的某个值是可调用的,视图将在渲染模板之前调用它。
*/
render方法就是将一个模板页面中的模板语法进行渲染,最终渲染成一个html页面作为响应体。
(3)redirect方法
当您使用Django框架构建Python Web应用程序时,您在某些时候必须将用户从一个URL重定向到另一个URL,
通过redirect方法实现重定向。
参数可以是:
- 一个绝对的或相对的URL, 将原封不动的作为重定向的位置.
- 一个url的别名: 可以使用reverse来反向解析url
传递要重定向到的一个具体的网址
def my_view(request):
...
return redirect("/some/url/")
当然也可以是一个完整的网址
def my_view(request):
...
return redirect("http://www.baidu.com")
传递一个视图的名称
def my_view(request):
...
return redirect(reverse("url的别名"))
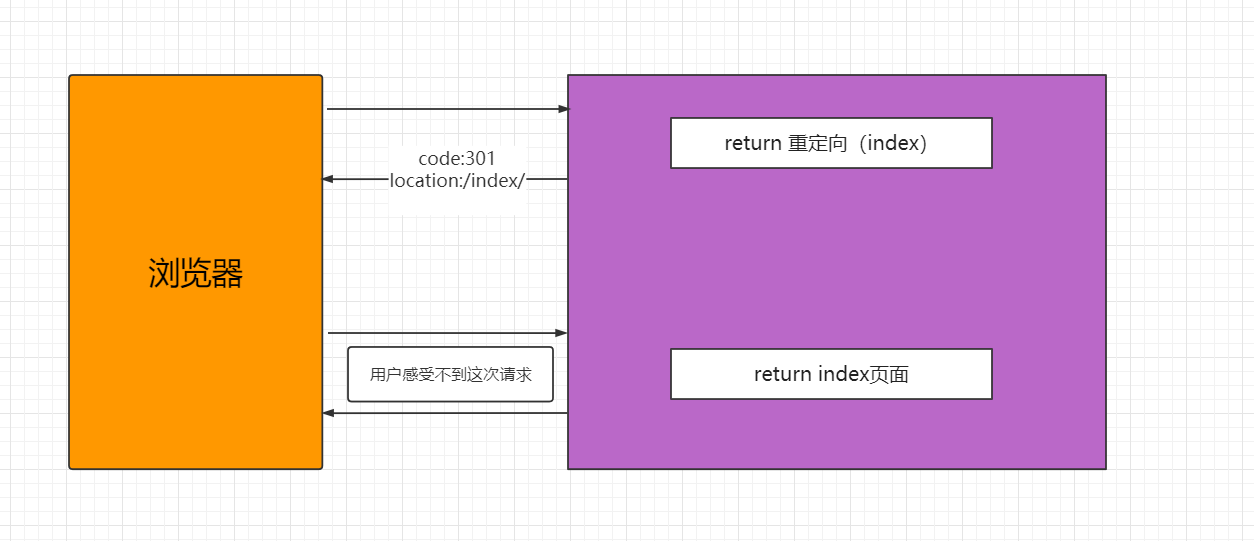
APPEND_SLASH的实现就是基于redirect
4.4、登录验证案例
from django.contrib import admin
from django.urls import path, re_path,include
from users.views import index,login,auth
urlpatterns = [
path("",index),
path("login/",login),
path("auth/",auth),
]
def login(request):
return render(request,"users/login.html")
def auth(request):
# 获取数据
print("request.POST:",request.POST)
user = request.POST.get("user")
pwd = request.POST.get("pwd")
# 模拟数据校验
if user == "rain" and pwd == "123":
# return HttpResponse("验证通过")
return redirect("/users/")
else:
# return HttpResponse("用户名或者密码错误")
# return redirect("/users/login")
msg = "用户名或者密码错误"
return render(request,"users/login.html",{"msg":msg})
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<form action="/users/auth" method="post">
用户名<input type="text" name="user">
密码 <input type="password" name="pwd">
<input type="submit"> <span style="color: red">{{ msg }}</span>
</form>
</body>
</html>
五、模板语法
模板引擎是一种可以让开发者把服务端数据填充到html网页中完成渲染效果的技术。它实现了把前端代码和服务端代码分离的作用,让项目中的业务逻辑代码和数据表现代码分离,让前端开发者和服务端开发者可以更好的完成协同开发。
静态网页:页面上的数据都是写死的,万年不变
动态网页:页面上的数据是从后端动态获取的(比如后端获取当前时间;后端获取数据库数据然后传递给前端页面)
Django框架中内置了web开发领域非常出名的一个DjangoTemplate模板引擎(DTL)。DTL官方文档
要在django框架中使用模板引擎把视图中的数据更好的展示给客户端,需要完成3个步骤:
在项目配置文件中指定保存模板文件的模板目录。一般模板目录都是设置在项目根目录或者主应用目录下。
在视图中基于django提供的渲染函数绑定模板文件和需要展示的数据变量
在模板目录下创建对应的模板文件,并根据模板引擎内置的模板语法,填写输出视图传递过来的数据。
配置模板目录:在当前项目根目录下创建了模板目录templates. 然后在settings.py, 模板相关配置,找到TEMPLATES配置项,填写DIRS设置模板目录。
# 模板引擎配置
TEMPLATES = [
{
'BACKEND': 'django.template.backends.django.DjangoTemplates',
'DIRS': [
BASE_DIR / "templates", # 路径拼接
],
'APP_DIRS': True,
'OPTIONS': {
'context_processors': [
'django.template.context_processors.debug',
'django.template.context_processors.request',
'django.contrib.auth.context_processors.auth',
'django.contrib.messages.context_processors.messages',
],
},
},
]
5.1、简单案例
为了方便接下里的演示内容,我这里创建创建一个新的子应用tem
python manage.py startapp tem
settings.py,注册子应用,代码:
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'tem', # 开发者创建的子应用,这填写就是子应用的导包路径
]
总路由加载子应用路由,urls.py,代码:
from django.contrib import admin
from django.urls import path,include
urlpatterns = [
path('admin/', admin.site.urls),
# path("路由前缀/", include("子应用目录名.路由模块"))
path("users/", include("users.urls")),
path("tem/", include("tem.urls")),
]
在子应用目录下创建urls.py子路由文件,代码如下:
"""子应用路由"""
from django.urls import path, re_path
from . import views
urlpatterns = [
path("index", views.index),
]
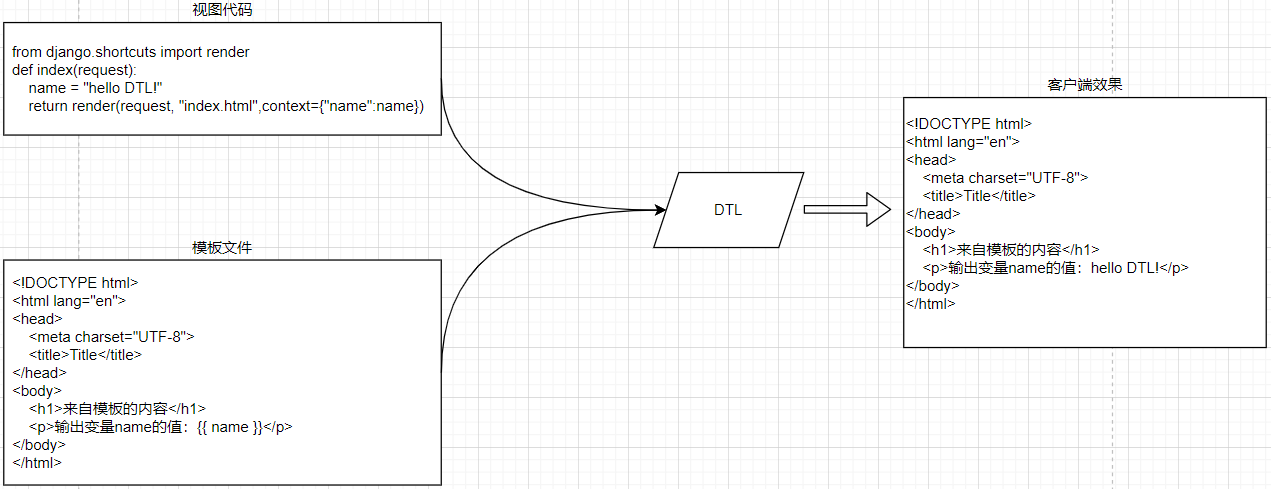
tem.views.index,代码:
from django.shortcuts import render
def index(request):
# 要显示到客户端的数据
name = "hello DTL!"
# return render(request, "模板文件路径",context={字典格式:要在客户端中展示的数据})
return render(request, "index.html",context={"name":name})
templates.index.html,代码:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<h1>来自模板的内容</h1>
<p>输出变量name的值:{{ name }}</p>
</body>
</html>
5.2、render函数内部本质
from django.shortcuts import render
from django.template.loader import get_template
from django.http.response import HttpResponse
def index(request):
name = "hello world!"
# 1. 初始化模板,读取模板内容,实例化模板对象
# get_template会从项目配置中找到模板目录,我们需要填写的参数就是补全模板文件的路径
template = get_template("index.html")
# 2. 识别context内容, 和模板内容里面的标记[标签]替换,针对复杂的内容,进行正则的替换
context = {"name": name}
content = template.render(context, request) # render中完成了变量替换成变量值的过程,这个过程使用了正则。
print(content)
# 3. 通过response响应对象,把替换了数据的模板内容返回给客户端
return HttpResponse(content) # 上面代码的简写,直接使用 django.shortcuts.render
# return render(request, "index.html",context={"name":name})
# return render(request,"index3.html", locals())
# data = {}
# data["name"] = "xiaoming"
# data["message"] = "你好!"
# return render(request,"index3.html", data)
- DTL模板文件与普通html文件的区别在哪里?
DTL模板文件是一种带有特殊语法的HTML文件,这个HTML文件可以被Django编译,可以传递参数进去,实现数据动态化。在编译完成后,生成一个普通的HTML文件,然后发送给客户端。
- 开发中,我们一般把开发中的文件分2种,分别是静态文件和动态文件。
* 静态文件,数据保存在当前文件,不需要经过任何处理就可以展示出去。普通html文件,图片,视频,音频等这一类文件叫静态文件。 * 动态文件,数据并不在当前文件,而是要经过服务端或其他程序进行编译转换才可以展示出去。 编译转换的过程往往就是使用正则或其他技术把文件内部具有特殊格式的变量转换成真实数据。 动态文件,一般数据会保存在第三方存储设备,如数据库中。django的模板文件,就属于动态文件。
5.3、模板语法
变量渲染(深度查询、过滤器)
{{val}} {{val|filter_name:参数}}标签
{% tag_name %}嵌套和继承
5.3.1、变量渲染之深度查询
def index(request):
name = "root"
age = 13
sex = True
lve = ["swimming", "shopping", "coding", "game"]
bookinfo = {"id": 1, "price": 9.90, "name": "python3天入门到挣扎", }
book_list = [
{"id": 10, "price": 9.90, "name": "python3天入门到挣扎", },
{"id": 11, "price": 19.90, "name": "python7天入门到垂死挣扎", },
]
return render(request, 'index.html', locals())
模板代码,templates/index.html:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<p>name={{ name }}</p>
<p>{{ age }}</p>
<p>{{ sex }}</p>
<p>列表成员</p>
<p>{{ lve }}</p>
<p>{{ lve.0 }}</p>
<p>{{ lve | last }}</p>
<p>字典成员</p>
<p>id={{ bookinfo.id }}</p>
<p>price={{ bookinfo.price }}</p>
<p>name={{ bookinfo.name }}</p>
<p>复杂列表</p>
<p>{{ book_list.0.name }}</p>
<p>{{ book_list.1.name }}</p>
</body>
</html>
通过句点符号深度查询
tem.urls,代码:
"""子应用路由"""
from django.urls import path, re_path
from . import views
urlpatterns = [
# ....
path("index", views.index),
]
5.3.2、变量渲染之内置过滤器
语法:
{{obj|过滤器名称:过滤器参数}}
内置过滤器
| 过滤器 | 用法 | 代码 |
|---|---|---|
| last | 获取列表/元组的最后一个成员 | {{liast | last}} |
| first | 获取列表/元组的第一个成员 | {{list|first}} |
| length | 获取数据的长度 | {{list | length}} |
| defualt | 当变量没有值的情况下, 系统输出默认值, | {{str|default="默认值"}} |
| safe | 让系统不要对内容中的html代码进行实体转义 | {{htmlcontent| safe}} |
| upper | 字母转换成大写 | {{str | upper}} |
| lower | 字母转换成小写 | {{str | lower}} |
| title | 每个单词首字母转换成大写 | {{str | title}} |
| date | 日期时间格式转换 | `{{ value |
| cut | 从内容中截取掉同样字符的内容 | {{content | cut:"hello"}} |
| list | 把内容转换成列表格式 | {{content | list}} |
| add | 加法 | {{num| add}} |
| filesizeformat | 把文件大小的数值转换成单位表示 | {{filesize | filesizeformat}} |
join |
按指定字符拼接内容 | {{list| join("-")}} |
random |
随机提取某个成员 | {list | random}} |
slice |
按切片提取成员 | {{list | slice:":-2"}} |
truncatechars |
按字符长度截取内容 | {{content | truncatechars:30}} |
truncatewords |
按单词长度截取内容 | 同上 |
过滤器的使用
视图代码 home.views.py;
def index(request):
"""过滤器 filters"""
content = "<a href='http://www.luffycity.com'>路飞学城</a>"
# content1 = '<script>alert(1);</script>'
from datetime import datetime
now = datetime.now()
content2= "hello wrold!"
return render(request,"index.html",locals())
# 模板代码,templates/index.html:
{{ content | safe }}
{{ content1 | safe }}
{# 过滤器本质就是函数,但是模板语法不支持小括号调用,所以需要使用:号分割参数 #}
<p>{{ now | date:"Y-m-d H:i:s" }}</p>
<p>{{ conten1 | default:"默认值" }}</p>
{# 一个数据可以连续调用多个过滤器 #}
<p>{{ content2 | truncatechars:6 | upper }}</p>
5.3.3、自定义过滤器
虽然官方已经提供了许多内置的过滤器给开发者,但是很明显,还是会有存在不足的时候。例如:希望输出用户的手机号码时, 13912345678 ---->> 139*****678,这时我们就需要自定义过滤器。要声明自定义过滤器并且能在模板中正常使用,需要完成2个前置的工作:
# 1. 当前使用和声明过滤器的子应用必须在setting.py配置文件中的INSTALLED_APPS中注册了!!!
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'home',
]
# 2. 自定义过滤器函数必须被 template.register进行装饰使用.
# 而且过滤器函数所在的模块必须在templatetags包里面保存
# 在home子应用下创建templatetags包[必须包含__init__.py], 在包目录下创建任意py文件
# home.templatetags.my_filters.py代码:
from django import template
register = template.Library()
# 自定义过滤器
@register.filter("mobile")
def mobile(content):
return content[:3]+"*****"+content[-3:]
# 3. 在需要使用的模板文件中顶部使用load标签加载过滤器文件my_filters.py并调用自定义过滤器
# home.views.py,代码:
def index(request):
"""自定义过滤器 filters"""
moblie_number = "13312345678"
return render(request,"index2.html",locals())
# templates/index2.html,代码:
{% load my_filters %}
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
{{ moblie_number| mobile }}
</body>
</html>
5.3.4、标签
(1)if 标签
视图代码,tem.views.py:
def index(request):
name = "xiaoming"
age = 19
sex = True
lve = ["swimming", "shopping", "coding", "game"]
user_lve = "sleep"
bookinfo = {"id": 1, "price": 9.90, "name": "python3天入门到挣扎", }
book_list = [
{"id": 10, "price": 9.90, "name": "python3天入门到挣扎", },
{"id": 11, "price": 19.90, "name": "python7天入门到垂死挣扎", },
]
return render(request, 'index.html', locals())
模板代码,templates/index.html,代码:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
{# 来自django模板引擎的注释~~~~ #}
{% comment %}
多行注释,comment中的所有内容全部都不会被显示出去
{% endcomment %}
{# {% if age < 18 %}#}
{# <p>你还没成年,不能访问我的网站!</p>#}
{# {% endif %}#}
{##}
{# {% if name == "root" %}#}
{# <p>超级用户,欢迎回家!</p>#}
{# {% else %}#}
{# <p>{{ name }},你好,欢迎来到xx网站!</p>#}
{# {% endif %}#}
{% if user_lve == lve.0 %}
<p>那么巧,你喜欢游泳,海里也能见到你~</p>
{% elif user_lve == lve.1 %}
<p>那么巧,你也来收快递呀?~</p>
{% elif user_lve == lve.2 %}
<p>那么巧,你也在老男孩?</p>
{% else %}
<p>看来我们没有缘分~</p>
{% endif %}
</body>
</html>
路由代码:
"""子应用路由"""
from django.urls import path, re_path
from . import views
urlpatterns = [
# ....
path("index", views.index),
]
(2)for标签
视图代码, home.views.py:
def index7(request):
book_list1 = [
{"id": 11, "name": "python基础入门", "price": 130.00},
{"id": 17, "name": "Go基础入门", "price": 230.00},
{"id": 23, "name": "PHP基础入门", "price": 330.00},
{"id": 44, "name": "Java基础入门", "price": 730.00},
{"id": 51, "name": "C++基础入门", "price": 300.00},
{"id": 56, "name": "C#基础入门", "price": 100.00},
{"id": 57, "name": "前端基础入门", "price": 380.00},
]
return render(request, 'index.html', locals())
template/index.html,代码:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<table width="800" align="center" border="1">
<tr>
<td>序号</td>
<td>id</td>
<td>标题</td>
<td>价格</td>
</tr>
{# 多行编辑,alt+鼠标键,alt不要松开,左键点击要编辑的每一行 #}
{# {% for book in book_list1 %}#}
{# <tr>#}
{# <td>{{ book.id }}</td>#}
{# <td>{{ book.name }}</td>#}
{# <td>{{ book.price }}</td>#}
{# </tr>#}
{# {% endfor %}#}
{# 建议不要直接使用for循环一维字典,此处使用仅仅展示for嵌套for而已 #}
{# {% for book in book_list1 %}#}
{# <tr>#}
{# {% for field,value in book.items %}#}
{# <td>{{ field }} == {{ value }}</td>#}
{# {% endfor %}#}
{# </tr>#}
{# {% endfor %}#}
{# {% for book in book_list1 %}#}
{# <tr>#}
{# <td>{{ book.id }}</td>#}
{# <td>{{ book.name }}</td>#}
{# {% if book.price > 200 %}#}
{# <td bgcolor="#ff7f50">{{ book.price }}</td>#}
{# {% else %}#}
{# <td>{{ book.price }}</td>#}
{# {% endif %}#}
{# </tr>#}
{# {% endfor %}#}
{# 逆向循环数据 #}
{# {% for book in book_list1 reversed %}#}
{# <tr>#}
{# <td>{{ book.id }}</td>#}
{# <td>{{ book.name }}</td>#}
{# {% if book.price > 200 %}#}
{# <td bgcolor="#ff7f50">{{ book.price }}</td>#}
{# {% else %}#}
{# <td>{{ book.price }}</td>#}
{# {% endif %}#}
{# </tr>#}
{# {% endfor %}#}
{% for book in book_list1 %}
<tr>
{# <td>{{ forloop.counter }}</td>#}
{# <td>{{ forloop.counter0 }}</td>#}
{# <td>{{ forloop.revcounter }}</td>#}
{# <td>{{ forloop.revcounter0 }}</td>#}
{# <td>{{ forloop.first }}</td>#}
<td>{{ forloop.last }}</td>
<td>{{ book.id }}</td>
<td>{{ book.name }}</td>
{% if book.price > 200 %}
<td bgcolor="#ff7f50">{{ book.price }}</td>
{% else %}
<td>{{ book.price }}</td>
{% endif %}
</tr>
{% endfor %}
</table>
</body>
</html>
路由代码:
"""子应用路由"""
from django.urls import path, re_path
from . import views
urlpatterns = [
# ....
path("index", views.index),
]
循环中, 模板引擎提供的forloop对象,用于给开发者获取循环次数或者判断循环过程的.
| 属性 | 描述 |
|---|---|
| forloop.counter | 显示循环的次数,从1开始 |
| forloop.counter0 | 显示循环的次数,从0开始 |
| forloop.revcounter0 | 倒数显示循环的次数,从0开始 |
| forloop.revcounter | 倒数显示循环的次数,从1开始 |
| forloop.first | 判断如果本次是循环的第一次,则结果为True |
| forloop.last | 判断如果本次是循环的最后一次,则结果为True |
| forloop.parentloop | 在嵌套循环中,指向当前循环的上级循环 |
5.3.5、模板嵌套继承
传统的模板分离技术,依靠{% include "模板文件名"%}实现,这种方式,虽然达到了页面代码复用的效果,但是由此也会带来大量的碎片化模板,导致维护模板的成本上升.因此, Django框架中除了提供这种模板分离技术以外,还并行的提供了 模板继承给开发者.
{% include "模板文件名"%} # 模板嵌入
{% extends "base.html" %} # 模板继承
(1) 继承父模板的公共内容
视图, home.views.py代码:
def index(request):
"""模板继承"""
return render(request,"index.html",locals())
子模板, templates/index.html
{% extends "base.html" %}
父模板, templates/base.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<h1>base.html的头部</h1>
<h1>base.html的内容</h1>
<h1>base.html的脚部</h1>
</body>
</html>
(2) 个性展示不同于父模板的内容
{%block %} 独立内容 {%endblock%}
{{block.super}}
视图home.views.py, 代码:
def index(request):
"""模板继承"""
return render(request,"index.html",locals())
def home(request):
"""模板继承"""
return render(request,"home.html",locals())
路由 home.urls.py,代码:
from django.urls import path
from . import views
urlpatterns = [
path("", views.index),
path("home/", views.home),
]
子模板index.html,代码:
{% extends "base.html" %}
{% block title %}index3的标题{% endblock %}
{% block content %}
{{ block.super }} {# 父级模板同名block标签的内容 #}
<h1>index3.html的独立内容</h1>
{{ block.super }}
{% endblock %}
子模板home.html,代码:
{% extends "base.html" %}
{% block title %}home的标题{% endblock %}
父模板base.html,代码:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>{% block title %}{% endblock %}</title>
</head>
<body>
<h1>base.html的头部</h1>
{% block content %}
<h1>base.html的内容</h1>
{% endblock %}
<h1>base.html的脚部</h1>
</body>
</html>
- 如果你在模版中使用
{% extends %}标签,它必须是模版中的第一个标签。其他的任何情况下,模版继承都将无法工作。- 在base模版中设置越多的
{% block %}标签越好。请记住,子模版不必定义全部父模版中的blocks,所以,你可以在大多数blocks中填充合理的默认内容,然后,只定义你需要的那一个。多一点钩子总比少一点好。- 为了更好的可读性,你也可以给你的
{% endblock %}标签一个 名字 。例如:{``%block content``%``}``...``{``%endblock content``%``},在大型模版中,这个方法帮你清楚的看到哪一个{% block %}标签被关闭了。- 不能在一个模版中定义多个相同名字的
block标签。
5.4、静态文件
开发中在开启了debug模式时,django可以通过配置,允许用户通过对应的url地址访问django的静态文件。
setting.py,代码:
STATIC_ROOT = BASE_DIR / 'static'
STATIC_URL = '/static/' # django模板中,可以引用{{STATIC_URL}}变量避免把路径写死。
总路由,urls.py,代码:
from django.views.static import serve as serve_static
urlpatterns = [
path('admin/', admin.site.urls),
# 对外提供访问静态文件的路由,serve_static 是django提供静态访问支持的映射类。依靠它,客户端才能访问到django的静态文件。
path(r'static/<path:path>', serve_static, {'document_root': settings.STATIC_ROOT},),
]
注意:项目上线以后,关闭debug模式时,django默认是不提供静态文件的访问支持,项目部署的时候,我们会通过收集静态文件使用nginx这种web服务器来提供静态文件的访问支持。
六、模型层(ORM)
Django中内嵌了ORM框架,不需要直接编写SQL语句进行数据库操作,而是通过定义模型类,操作模型类来完成对数据库中表的增删改查和创建等操作。
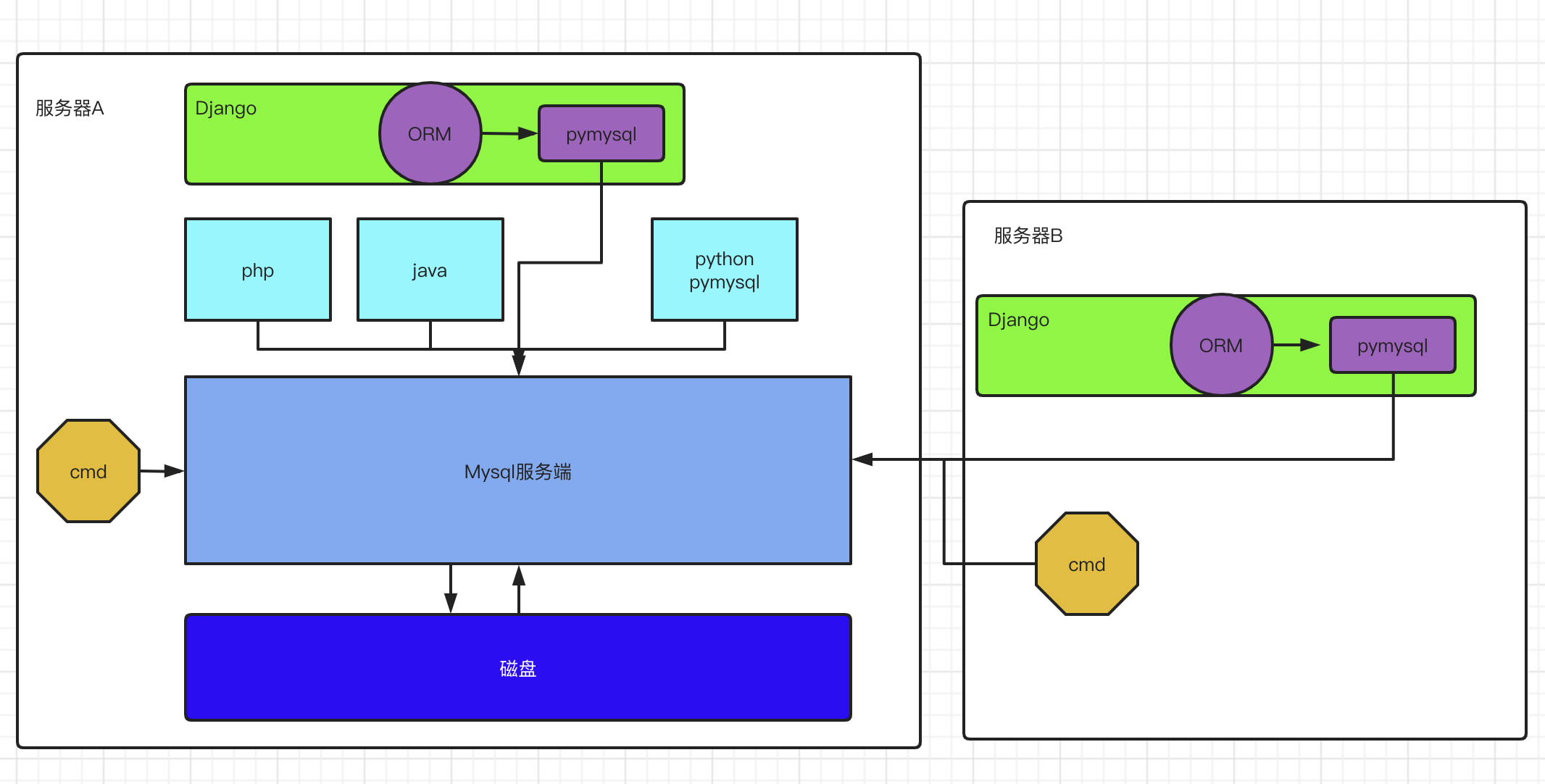
O是object,也就类对象的意思。
R是relation,翻译成中文是关系,也就是关系数据库中数据表的意思。
M是mapping,是映射的意思。
映射:
类:sql语句table表
类成员变量:table表中的字段、类型和约束
类对象:sql表的表记录
ORM的优点
数据模型类都在一个地方定义,更容易更新和维护,也利于重用代码。
ORM 有现成的工具,很多功能都可以自动完成,比如数据消除、预处理、事务等等。
它迫使你使用 MVC 架构,ORM 就是天然的 Model,最终使代码更清晰。
基于 ORM 的业务代码比较简单,代码量少,语义性好,容易理解。
新手对于复杂业务容易写出性能不佳的 SQL,有了ORM不必编写复杂的SQL语句, 只需要通过操作模型对象即可同步修改数据表中的数据.
开发中应用ORM将来如果要切换数据库.只需要切换ORM底层对接数据库的驱动【修改配置文件的连接地址即可】
ORM 也有缺点
- ORM 库不是轻量级工具,需要花很多精力学习和设置,甚至不同的框架,会存在不同操作的ORM。
- 对于复杂的业务查询,ORM表达起来比原生的SQL要更加困难和复杂。
- ORM操作数据库的性能要比使用原生的SQL差。
- ORM 抽象掉了数据库层,开发者无法了解底层的数据库操作,也无法定制一些特殊的 SQL。【自己使用pymysql另外操作即可,用了ORM并不表示当前项目不能使用别的数据库操作工具了。】
我们可以通过以下步骤来使用django的数据库操作
1. 配置数据库连接信息
2. 在models.py中定义模型类
3. 生成数据库迁移文件并执行迁移文件[注意:数据迁移是一个独立的功能,这个功能在其他web框架未必和ORM一块的]
4. 通过模型类对象提供的方法或属性完成数据表的增删改查操作
6.1、配置数据库连接
在settings.py中保存了数据库的连接配置信息,Django默认初始配置使用sqlite数据库。
-
使用MySQL数据库首先需要安装驱动程序
pip install PyMySQL -
在Django的工程同名子目录的
__init__.py文件中添加如下语句from pymysql import install_as_MySQLdb install_as_MySQLdb() # 让pymysql以MySQLDB的运行模式和Django的ORM对接运行作用是让Django的ORM能以mysqldb的方式来调用PyMySQL。
-
修改DATABASES配置信息
DATABASES = { 'default': { 'ENGINE': 'django.db.backends.mysql', 'HOST': '127.0.0.1', # 数据库主机 'PORT': 3306, # 数据库端口 'USER': 'root', # 数据库用户名 'PASSWORD': '123', # 数据库用户密码 'NAME': 'student' # 数据库名字 } } -
在MySQL中创建数据库
create database student; # mysql8.0默认就是utf8mb4; create database student default charset=utf8mb4; # mysql8.0之前的版本 -
注意3: 如果想打印orm转换过程中的sql,需要在settings中进行如下配置:
LOGGING = { 'version': 1, 'disable_existing_loggers': False, 'handlers': { 'console':{ 'level':'DEBUG', 'class':'logging.StreamHandler', }, }, 'loggers': { 'django.db.backends': { 'handlers': ['console'], 'propagate': True, 'level':'DEBUG', }, } }
6.2、定义模型类
定义模型类
- 模型类被定义在"子应用/models.py"文件中。
- 模型类必须直接或者间接继承自django.db.models.Model类。
接下来以学生管理为例进行演示。[系统大概3-4表,学生信息,课程信息,老师信息],创建子应用student,注册子应用并引入子应用路由.
settings.py,代码:
INSTALLED_APPS = [
# ...
'student',
]
urls.py,总路由代码:
urlpatterns = [
# 省略,如果前面有重复的路由,改动以下。
path("student/", include("student.urls")),
]
在models.py 文件中定义模型类。
from django.db import models
from datetime import datetime
# 模型类必须要直接或者间接继承于 models.Model
class BaseModel(models.Model):
"""公共模型[公共方法和公共字段]"""
# created_time = models.IntegerField(default=0, verbose_name="创建时间")
created_time = models.DateTimeField(auto_now_add=True, verbose_name="创建时间")
# auto_now_add 当数据添加时设置当前时间为默认值
# auto_now= 当数据添加/更新时, 设置当前时间为默认值
updated_time = models.DateTimeField(auto_now=True)
class Meta(object):
abstract = True # 设置当前模型为抽象模型, 当系统运行时, 不会认为这是一个数据表对应的模型.
class Student(BaseModel):
"""Student模型类"""
#1. 字段[数据库表字段对应]
SEX_CHOICES = (
(0,"女"),
(1,"男"),
(2,"保密"),
)
# 字段名 = models.数据类型(约束选项1,约束选项2, verbose_name="注释")
# SQL: id bigint primary_key auto_increment not null comment="主键",
# id = models.AutoField(primary_key=True, null=False, verbose_name="主键") # django会自动在创建数据表的时候生成id主键/还设置了一个调用别名 pk
# SQL: name varchar(20) not null comment="姓名"
# SQL: key(name),
name = models.CharField(max_length=20, db_index=True, verbose_name="姓名" )
# SQL: age smallint not null comment="年龄"
age = models.SmallIntegerField(verbose_name="年龄")
# SQL: sex tinyint not null comment="性别"
# sex = models.BooleanField(verbose_name="性别")
sex = models.SmallIntegerField(choices=SEX_CHOICES, default=2)
# SQL: class varchar(5) not null comment="班级"
# SQL: key(class)
classmate = models.CharField(db_column="class", max_length=5, db_index=True, verbose_name="班级")
# SQL: description longtext default "" not null comment="个性签名"
description = models.TextField(default="", verbose_name="个性签名")
#2. 数据表结构信息
class Meta:
db_table = 'tb_student' # 指明数据库表名,如果没有指定表明,则默认为子应用目录名_模型名称,例如: users_student
verbose_name = '学生信息表' # 在admin站点中显示的名称
verbose_name_plural = verbose_name # 显示的复数名称
#3. 自定义数据库操作方法
def __str__(self):
"""定义每个数据对象的显示信息"""
return "<User %s>" % self.name
(1) 数据库表名
模型类如果未指明表名db_table,Django默认以 小写app应用名_小写模型类名 为数据库表名。
可通过db_table 指明数据库表名。
(2) 关于主键
django会为表创建自动增长的主键列,每个模型只能有一个主键列。
如果使用选项设置某个字段的约束属性为主键列(primary_key)后,django不会再创建自动增长的主键列。
class Student(models.Model):
# django会自动在创建数据表的时候生成id主键/还设置了一个调用别名 pk
id = models.AutoField(primary_key=True, null=False, verbose_name="主键") # 设置主键
默认创建的主键列属性为id,可以使用pk代替,pk全拼为primary key。
(3) 属性命名限制
-
不能是python的保留关键字。
-
不允许使用连续的2个下划线,这是由django的查询方式决定的。__ 是关键字来的,不能使用!!!
-
定义属性时需要指定字段类型,通过字段类型的参数指定选项,语法如下:
属性名 = models.字段类型(约束选项, verbose_name="注释")
(4)字段类型
| 类型 | 说明 |
|---|---|
| AutoField | 自动增长的IntegerField,通常不用指定,不指定时Django会自动创建属性名为id的自动增长属性 |
| BooleanField | 布尔字段,值为True或False |
| NullBooleanField | 支持Null、True、False三种值 |
| CharField | 字符串,参数max_length表示最大字符个数,对应mysql中的varchar |
| TextField | 大文本字段,一般大段文本(超过4000个字符)才使用。 |
| IntegerField | 整数 |
| DecimalField | 十进制浮点数, 参数max_digits表示总位数, 参数decimal_places表示小数位数,常用于表示分数和价格 Decimal(max_digits=7, decimal_places=2) ==> 99999.99~ 0.00 |
| FloatField | 浮点数 |
| DateField | 日期 参数auto_now表示每次保存对象时,自动设置该字段为当前时间。 参数auto_now_add表示当对象第一次被创建时自动设置当前。 参数auto_now_add和auto_now是相互排斥的,一起使用会发生错误。 |
| TimeField | 时间,参数同DateField |
| DateTimeField | 日期时间,参数同DateField |
| FileField | 上传文件字段,django在文件字段中内置了文件上传保存类, django可以通过模型的字段存储自动保存上传文件, 但是, 在数据库中本质上保存的仅仅是文件在项目中的存储路径!! |
| ImageField | 继承于FileField,对上传的内容进行校验,确保是有效的图片 |
(5)约束选项
| 选项 | 说明 |
|---|---|
| null | 如果为True,表示允许为空,默认值是False。相当于python的None |
| blank | 如果为True,则该字段允许为空白,默认值是False。 相当于python的空字符串,“” |
| db_column | 字段的名称,如果未指定,则使用属性的名称。 |
| db_index | 若值为True, 则在表中会为此字段创建索引,默认值是False。 相当于SQL语句中的key |
| default | 默认值,当不填写数据时,使用该选项的值作为数据的默认值。 |
| primary_key | 如果为True,则该字段会成为模型的主键,默认值是False,一般不用设置,系统默认设置。 |
| unique | 如果为True,则该字段在表中必须有唯一值,默认值是False。相当于SQL语句中的unique |
注意:null是数据库范畴的概念,blank是表单验证范畴的
(6) 外键
在设置外键时,需要通过on_delete选项指明主表删除数据时,对于外键引用表数据如何处理,在django.db.models中包含了可选常量:
-
CASCADE 级联,删除主表数据时连通一起删除外键表中数据
-
PROTECT 保护,通过抛出ProtectedError异常,来阻止删除主表中被外键应用的数据
-
SET_NULL 设置为NULL,仅在该字段null=True允许为null时可用
-
SET_DEFAULT 设置为默认值,仅在该字段设置了默认值时可用
-
SET() 设置为特定值或者调用特定方法,例如:
from django.conf import settings from django.contrib.auth import get_user_model from django.db import models def get_sentinel_user(): return get_user_model().objects.get_or_create(username='deleted')[0] class UserModel(models.Model): user = models.ForeignKey( settings.AUTH_USER_MODEL, on_delete=models.SET(get_sentinel_user), ) -
DO_NOTHING 不做任何操作,如果数据库前置指明级联性,此选项会抛出IntegrityError异常
商品分类表
| id | category | |
|---|---|---|
| 1 | 蔬菜 | |
| 2 | 电脑 |
商品信息表
| id | goods_name | cid |
|---|---|---|
| 1 | 冬瓜 | 1 |
| 2 | 华为笔记本A1 | 2 |
| 3 | 茄子 | 1 |
当模型字段的on_delete=CASCADE, 删除蔬菜(id=1),则在外键cid=1的商品id1和3就被删除。
当模型字段的on_delete=PROTECT,删除蔬菜,mysql自动检查商品信息表,有没有cid=1的记录,有则提示必须先移除掉商品信息表中,id=1的所有记录以后才能删除蔬菜。
当模型字段的on_delete=SET_NULL,删除蔬菜以后,对应商品信息表,cid=1的数据的cid全部被改成cid=null
当模型字段的on_delete=SET_DEFAULT,删除蔬菜以后,对应商品信息表,cid=1的数据记录的cid被被设置默认值。
6.3、数据迁移
将模型类定义表架构的代码转换成SQL同步到数据库中,这个过程就是数据迁移。django中的数据迁移,就是一个类,这个类提供了一系列的终端命令,帮我们完成数据迁移的工作。
(1)生成迁移文件
所谓的迁移文件, 是类似模型类的迁移类,主要是描述了数据表结构的类文件.
python manage.py makemigrations
(2)同步到数据库中
python manage.py migrate
补充:在django内部提供了一系列的功能,这些功能也会使用到数据库,所以在项目搭建以后第一次数据迁移的时候,会看到django项目中其他的数据表被创建了。其中就有一个django内置的admin站点管理。
# admin站点默认是开启状态的,我们可以通过http://127.0.0.1:8000/admin
# 这个站点必须有个管理员账号登录,所以我们可以在第一次数据迁移,有了数据表以后,就可以通过以下终端命令来创建一个超级管理员账号。
python manage.py createsuperuser
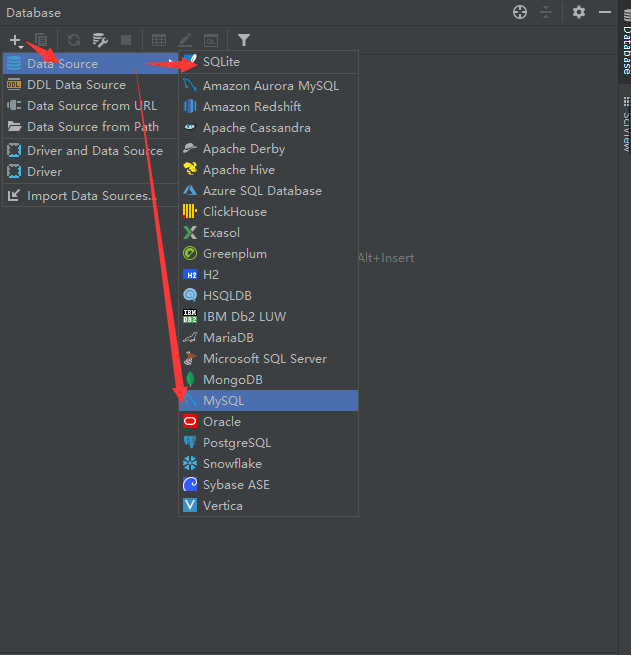
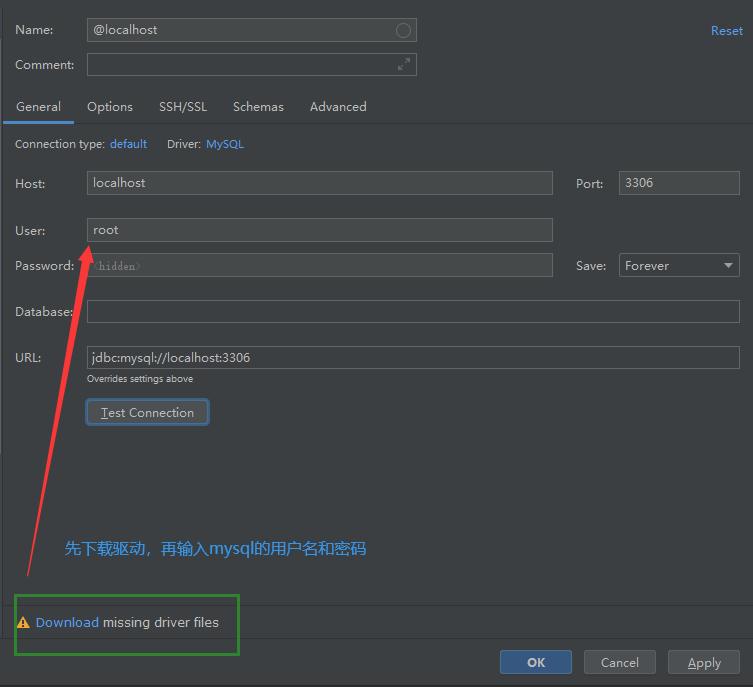
(3)添加测试数据
INSERT INTO `db_student`
(`id`,`name`,`sex`,`class`,`age`,`description`,`created_time`,`updated_time`)
VALUES
(1,'赵华',1,307,22,'对于勤奋的人来说,成功不是偶然;对于懒惰的人来说,失败却是必然。','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(2,'程星云',1,301,20,'人生应该如蜡烛一样,从顶燃到底,一直都是光明的。','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(3,'陈峰',1,504,21,'在不疯狂,我们就老了,没有记忆怎么祭奠呢?','2020-11-20 10:00:00','2020-11-20 10:00:00'),(4,'苏礼就',1,502,20,'不要为旧的悲伤,浪费新的眼泪。','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(5,'张小玉',2,306,18,'没有血和汗水就没有成功的泪水。','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(6,'吴杰',1,307,19,'以大多数人的努力程度之低,根本轮不到去拼天赋','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(7,'张小辰',2,405,19,'人生的道路有成千上万条, 每一条路上都有它独自的风景。','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(8,'王丹丹',2,502,22,'平凡的人听从命运,坚强的人主宰命运。','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(9,'苗俊伟',1,503,22,'外事找谷歌,内事找百度。','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(10,'娄镇明',1,301,22,'不经三思不求教,不动笔墨不读书。','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(11,'周梦琪',2,306,19,'学习与坐禅相似,须有一颗恒心。','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(12,'欧阳博',1,503,23,'春去秋来,又一年。What did you get ?','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(13,'颜敏莉',2,306,20,'Knowledge makes humble, ignorance makes proud.','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(14,'柳宗仁',1,301,20,'有志者事竟成。','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(15,'谢海龙',1,402,22,'这世界谁也不欠谁,且行且珍惜。','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(16,'邓士鹏',1,508,22,'青,取之于蓝而青于蓝;冰,水为之而寒于水。','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(17,'宁静',2,502,23,'一息若存 希望不灭','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(18,'上官屏儿',2,502,21,'美不自美,因人而彰。','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(19,'孙晓静',2,503,20,'人生本过客,何必千千结;无所谓得失,淡看风和雨。','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(20,'刘承志',1,306,20,'good good study,day day up! ^-^','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(21,'王浩',1,503,21,'积土而为山,积水而为海。','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(22,'钟无艳',2,303,19,'真者,精诚之至也,不精不诚,不能动人。','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(23,'莫荣轩',1,409,22,'不管发生什么事,都请安静且愉快地接受人生,勇敢地、大胆地,而且永远地微笑着。','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(24,'张裕民',1,303,21,'伟大的目标形成伟大的人物。','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(25,'江宸轩',1,407,22,'用最少的悔恨面对过去。','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(26,'谭季同',1,305,21,'人总是珍惜未得到的,而遗忘了所拥有的。','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(27,'李松风',1,504,19,'明天的希望,让我们忘了今天的痛苦。','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(28,'叶宗政',1,407,20,'因害怕失败而不敢放手一搏,永远不会成功。','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(29,'魏雪宁',2,306,20,'成功与失败只有一纸之隔','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(30,'徐秋菱',2,404,19,'年轻是我们唯一拥有权利去编织梦想的时光。','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(31,'曾嘉慧',2,301,19,'有一分热,发一分光。就令萤火一般,也可以在黑暗里发一点光,不必等候炬火。','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(32,'欧阳镇安',1,408,23,'青春虚度无所成,白首衔悲补何及!','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(33,'周子涵',2,309,19,'青春是一个普通的名称,它是幸福美好的,但它也是充满着艰苦的磨炼。','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(34,'宋应诺',2,501,23,'涓滴之水终可以磨损大石,不是由于它力量强大,而是由于昼夜不舍的滴坠。','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(35,'白瀚文',1,305,19,'一个人假如不脚踏实地去做,那么所希望的一切就会落空。','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(36,'陈匡怡',2,505,19,'一份耕耘,一份收获。','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(37,'邵星芸',2,503,22,'冰冻三尺非一日之寒。','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(38,'王天歌',2,302,21,'任何的限制,都是从自己的内心开始的。','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(39,'王天龙',1,302,22,'再长的路,一步步也能走完,再短的路,不迈开双脚也无法到达。','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(40,'方怡',2,509,23,'智者不做不可能的事情。','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(41,'李伟',1,505,19,'人之所以能,是相信能。','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(42,'李思玥',2,503,22,'人的一生可能燃烧也可能腐朽,我不能腐朽,我愿意燃烧起来。','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(43,'赵思成',1,401,18,'合抱之木,生于毫末;九层之台,起于累土。','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(44,'蒋小媛',2,308,22,'不积跬步无以至千里,不积细流无以成江河。','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(45,'龙华',1,510,19,'只要持续地努力,不懈地奋斗,就没有征服不了的东西。','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(46,'牧婧白夜',2,501,21,'读不在三更五鼓,功只怕一曝十寒。','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(47,'江俊文',1,304,19,'立志不坚,终不济事。','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(48,'李亚容',2,304,18,'Keep on going never give up.','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(49,'王紫伊',2,301,22,'最可怕的敌人,就是没有坚强的信念。','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(50,'毛小宁',1,501,19,'要从容地着手去做一件事,但一旦开始,就要坚持到底。','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(51,'董 晴',2,507,19,'常常是最后一把钥匙打开了门。贵在坚持','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(52,'严语',2,405,18,'逆水行舟,不进则退。','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(53,'陈都灵',2,503,19,'无论什么时候,不管遇到什么情况,我绝不允许自己有一点点灰心丧气。','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(54,'黄威',1,301,23,'我的字典里面没有“放弃”两个字','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(55,'林佳欣',2,308,23,'梦想就是一种让你感到坚持,就是幸福的东西。','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(56,'翁心颖',2,303,19,'有目标的人才能成功,因为他们知道自己的目标在哪里。','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(57,'蒙毅',1,502,22,'所谓天才,就是努力的力量。','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(58,'李小琳',2,509,22,'每天早上对自己微笑一下。这就是我的生活态度。','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(59,'伍小龙',1,406,19,'一路上的点点滴滴才是我们的财富。','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(60,'晁然',2,305,23,'人的价值是由自己决定的。','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(61,'端木浩然',1,507,18,'摔倒了爬起来再哭。','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(62,'姜沛佩',2,309,21,'Believe in yourself.','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(63,'李栋明',1,306,19,'虽然过去不能改变,但是未来可以。','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(64,'柴柳依',2,508,23,'没有实践就没有发言权。','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(65,'吴杰',1,401,22,'人生有两出悲剧。一是万念俱灰;另一是踌躇满志','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(66,'杜文华',1,507,19,'有智者立长志,无志者长立志。','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(67,'邓珊珊',2,510,18,'Action is the proper fruit of knowledge.','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(68,'杜俊峰',1,507,23,'世上无难事,只要肯登攀。','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(69,'庄信杰',1,301,22,'知识就是力量。','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(70,'宇文轩',1,402,23,'如果你想要某样东西,别等着有人某天会送给你。生命太短,等不得。','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(71,'黄佳怿',2,510,19,'Learn and live.','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(72,'卫然',1,510,18,'神于天,圣于地。','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(73,'耶律齐',1,307,23,'如果不是在海市蜃楼中求胜,那就必须脚踏实地去跋涉。','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(74,'白素欣',2,305,18,'欲望以提升热忱,毅力以磨平高山。','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(75,'徐鸿',1,403,23,'最美的不是生如夏花,而是在时间的长河里,波澜不惊。','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(76,'上官杰',1,409,19,'生活之所以耀眼,是因为磨难与辉煌会同时出现。','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(77,'吴兴国',1,406,18,'生活的道路一旦选定,就要勇敢地走到底,决不回头。','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(78,'庄晓敏',2,305,18,'Never say die.','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(79,'吴镇升',1,509,18,'Judge not from appearances.','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(80,'朱文丰',1,304,19,'每个人都比自己想象的要强大,但同时也比自己想象的要普通。','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(81,'苟兴妍',2,508,18,'Experience is the best teacher.','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(82,'祝华生',1,302,21,'浅学误人。','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(83,'张美琪',2,404,23,'最淡的墨水,也胜过最强的记性。','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(84,'周永麟',1,308,21,'All work and no play makes Jack a dull boy.','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(85,'郑心',2,404,21,'人生就像一杯茶,不会苦一辈子,但总会苦一阵子。','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(86,'公孙龙馨',1,510,21,'Experience is the father of wisdom and memory the mother.','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(87,'叶灵珑',2,401,19,'读一书,增一智。','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(88,'上官龙',1,501,21,'别人能做到的事,自己也可以做到。','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(89,'颜振超',1,303,19,'如果要飞得高,就该把地平线忘掉。','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(90,'玛诗琪',2,409,22,'每天进步一点点,成功不会远。','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(91,'李哲生',1,309,22,'这不是偶然的失误,是必然的结果。','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(92,'罗文华',2,408,22,'好走的都是下坡路。','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(93,'李康',1,509,19,'Deliberate slowly, promptly.','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(94,'钟华强',1,405,19,'混日子很简单,讨生活比较难。','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(95,'张今菁',2,403,23,'不经一翻彻骨寒,怎得梅花扑鼻香。','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(96,'黄伟麟',1,407,19,'与其诅咒黑暗,不如燃起蜡烛。没有人能给你光明,除了你自己。','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(97,'程荣泰',1,406,22,'明天不一定更好,。但更好的明天一定会来。','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(98,'范伟杰',1,508,19,'水至清则无鱼,人至察则无徒。凡事不能太执着。','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(99,'王俊凯',1,407,21,'我欲将心向明月,奈何明月照沟渠。','2020-11-20 10:00:00','2020-11-20 10:00:00'),
(100,'白杨 ',1,406,19,'闪电从不打在相同的地方.人不该被相同的方式伤害两次。','2020-11-20 10:00:00','2020-11-20 10:00:00');
-- 作业:
-- 1. 完成学生的创建,导入上面的数据。
-- 2. 使用原来学过的SQL语句,然后对上面导入的学生信息,完成增删查改的操作。
-- 2.0 查询所有的学生信息(name,age)
SELECT name,age FROM db_student
-- 2.1 查询年龄在18-20之间的学生信息[name,age,sex]
select name,age,sex from db_student where age >=18 and age <=20;
-- 2.2 查询年龄在18-20之间的男生信息[name,age,sex]
select name,age,if(sex=1,'男','女') as sex from db_student where age >=18 and age <=20 and sex=1;
-- 2.3 查询401-406之间所有班级的学生信息[name,age,sex,class]
select name,age,sex,class from db_student where class between 401 and 406;
-- 2.4 查询401-406之间所有班级的总人数
select count(1) as c from db_student where class between 401 and 406;
-- 2.5 添加一个学生,男,刘德华,302班,17岁,"给我一杯水就行了。",'2020-11-20 10:00:00','2020-11-20 10:00:00'
insert into db_student (name,sex,class, age, description, created_time,updated_time) values ('刘德华',1,'302', 17, "给我一杯水就行了。",'2020-11-20 10:00:00','2020-11-20 10:00:00');
-- 2.6 修改刘德华的年龄,为19岁。
update db_student set age=19 where name='刘德华';
-- 2.7 刘德华毕业了,把他从学生表中删除
delete from db_student where name='刘德华';
-- 2.8 找到所有学生中,年龄最小的5位同学和年龄最大的5位同学
select * from db_student order by age asc limit 5;
select * from db_student order by age desc limit 5;
-- 2.9 【进阶】找到所有班级中人数超过4个人班级出来
select class,count(id) as total from db_student group by class having total >= 4;
-- 2.10【进阶】把上面2.8的要求重新做一遍,改成一条数据实现
(select * from db_student order by age asc limit 5) union all (select * from db_student order by age desc limit 5);
6.4、数据库基本操作
6.4.1、添加记录
(1)save方法
通过创建模型类对象,执行对象的save()方法保存到数据库中。
student = Student(
name="刘德华",
age=17,
sex=True,
classmate=301,
description="一手忘情水"
)
student.save()
print(student.id) # 判断是否新增有ID
(2)create方法
通过模型类.objects.create()保存,返回生成的模型类对象。
student = Student.objects.create(
name="赵本山",
age=50,
sex=True,
class_number=301,
description="一段小品"
)
print(student.id)
6.4.2、基础查询
ORM中针对查询结果的限制,提供了一个查询集[QuerySet].这个QuerySet,是ORM中针对查询结果进行保存数据的一个类型,我们可以通过了解这个QuerySet进行使用,达到查询优化,或者限制查询结果数量的作用。
(1)all()
查询所有对象,返回queryset对象。查询集,也称查询结果集、QuerySet,表示从数据库中获取的对象集合。
students = Student.objects.all()
print("students:",students)
(2)filter()
筛选条件相匹配的对象,返回queryset对象。
# 查询所有的女生
students = Student.objects.filter(sex=0)
print(students)
(3)get()
返回与所给筛选条件相匹配的对象,返回结果有且只有一个, 如果符合筛选条件的对象超过一个或者没有都会抛出错误。
student = Student.objects.get(pk=1)
print(student)
print(student.description)
get使用过程中的注意点:get是根据条件返回多个结果或者没有结果,都会报错
try:
student = Student.objects.get(name="刘德华")
print(student)
print(student.description)
except Student.MultipleObjectsReturned:
print("查询得到多个结果!")
except Student.DoesNotExist:
print("查询结果不存在!")
(4)first()、last()
分别为查询集的第一条记录和最后一条记录
# 没有结果返回none,如果有多个结果,则返回模型对象
students = Student.objects.all()
# print(students.name)
print(students[0].name)
stu01 = Student.objects.first()
stu02 = Student.objects.last()
print(stu01.name)
print(stu02.name)
(5)exclude()
筛选条件不匹配的对象,返回queryset对象。
# 查询张三以外的所有的学生
students = Student.objects.exclude(name="张三")
print(students)
(6)order_by()
对查询结果排序
# order_by("字段") # 按指定字段正序显示,相当于 asc 从小到大
# order_by("-字段") # 按字段倒序排列,相当于 desc 从大到小
# order_by("第一排序","第二排序",...)
# 查询所有的男学生按年龄从高到低展示
# students = Student.objects.all().order_by("-age","-id")
students = Student.objects.filter(sex=1).order_by("-age", "-id")
print(students)
(7)count()
查询集中对象的个数
# 查询所有男生的个数
count = Student.objects.filter(sex=1).count()
print(count)
(8)exists()
判断查询集中是否有数据,如果有则返回True,没有则返回False
# 查询Student表中是否存在学生
print(Student.objects.exists())
(9)values()、values_list()
-
value()把结果集中的模型对象转换成字典,并可以设置转换的字段列表,达到减少内存损耗,提高性能 -
values_list(): 把结果集中的模型对象转换成列表,并可以设置转换的字段列表(元祖),达到减少内存损耗,提高性能
# values 把查询结果中模型对象转换成字典
student_list = Student.objects.filter(classmate="301")
student_list = student_list.order_by("-age")
student_list = student_list.filter(sex=1)
ret1 = student_list.values() # 默认把所有字段全部转换并返回
ret2 = student_list.values("id","name","age") # 可以通过参数设置要转换的字段并返回
ret3 = student_list.values_list() # 默认把所有字段全部转换并返回
ret4 = student_list.values_list("id","name","age") # 可以通过参数设置要转换的字段并返回
print(ret4)
return JsonResponse({},safe=False)
(10)distinct()
从返回结果中剔除重复纪录。返回queryset。
# 查询所有学生出现过的年龄
print(Student.objects.values("age").distinct())
6.4.3、模糊查询
(1)模糊查询之contains
说明:如果要包含%无需转义,直接写即可。
例:查询姓名包含'华'的学生。
Student.objects.filter(name__contains='华')
(2)模糊查询之startswith、endswith
例:查询姓名以'文'结尾的学生
Student.objects.filter(name__endswith='文')
以上运算符都区分大小写,在这些运算符前加上i表示不区分大小写,如iexact、icontains、istartswith、iendswith.
(3)模糊查询之isnull
例:查询个性签名不为空的学生。
# 修改Student模型description属性允许设置为null,然后数据迁移
description = models.TextField(default=None, null=True, verbose_name="个性签名")
# 添加测试数据
NSERT INTO student.db_student (name, age, sex, class, description, created_time, updated_time) VALUES ('刘德华', 17, 1, '407', null, '2020-11-20 10:00:00.000000', '2020-11-20 10:00:00.000000');
# 代码操作
tudent_list = Student.objects.filter(description__isnull=True)
(4)模糊查询之in
例:查询编号为1或3或5的学生
Student.objects.filter(id__in=[1, 3, 5])
(5)模糊查询之比较查询
- gt 大于 (greater then)
- gte 大于等于 (greater then equal)
- lt 小于 (less then)
- lte 小于等于 (less then equal)
例:查询编号大于3的学生
Student.objects.filter(id__gt=3)
(6)模糊查询之日期查询
year、month、day、week_day、hour、minute、second:对日期时间类型的属性进行运算。
例:查询2010年被添加到数据中的学生。
Student.objects.filter(born_date__year=1980)
例:查询2016年6月20日后添加的学生信息。
from django.utils import timezone as datetime
student_list = Student.objects.filter(created_time__gte=datetime.datetime(2016,6,20),created_time__lt=datetime.datetime(2016,6,21)).all()
print(student_list)
6.4.4、进阶查询
(1) F查询
之前的查询都是对象的属性与常量值比较,两个属性怎么比较呢? 答:使用F对象,被定义在django.db.models中。
语法如下:
"""F对象:2个字段的值比较"""
# 获取从添加数据以后被改动过数据的学生
from django.db.models import F
# SQL: select * from db_student where created_time=updated_time;
student_list = Student.objects.exclude(created_time=F("updated_time"))
print(student_list)
(2) Q查询
多个过滤器逐个调用表示逻辑与关系,同sql语句中where部分的and关键字。
例:查询年龄大于20,并且编号小于30的学生。
Student.objects.filter(age__gt=20,id__lt=30)
或
Student.filter(age__gt=20).filter(id__lt=30)
如果需要实现逻辑或or的查询,需要使用Q()对象结合|运算符,Q对象被义在django.db.models中。
语法如下:
Q(属性名__运算符=值)
Q(属性名__运算符=值) | Q(属性名__运算符=值)
例:查询年龄小于19或者大于20的学生,使用Q对象如下。
from django.db.models import Q
student_list = Student.objects.filter( Q(age__lt=19) | Q(age__gt=20) ).all()
Q对象可以使用&、|连接,&表示逻辑与,|表示逻辑或**
例:查询年龄大于20,或编号小于30的学生,只能使用Q对象实现
Student.objects.filter(Q(age__gt=20) | Q(pk__lt=30))
Q对象左边可以使用~操作符,表示非not。但是工作中,我们只会使用Q对象进行或者的操作,只有多种嵌套复杂的查询条件才会使用&和~进行与和非得操作。
例:查询编号不等于30的学生。
Student.objects.filter(~Q(pk=30))
(3)聚合查询
使用aggregate()过滤器调用聚合函数。聚合函数包括:Avg 平均,Count 数量,Max 最大,Min 最小,Sum 求和,被定义在django.db.models中。
例:查询学生的平均年龄。
from django.db.models import Sum,Count,Avg,Max,Min
Student.objects.aggregate(Avg('age'))
注意:aggregate的返回值是一个字典类型,格式如下:
{'属性名__聚合类小写':值}
使用count时一般不使用aggregate()过滤器。
例:查询学生总数。
Student.objects.count() # count函数的返回值是一个数字。
(4)分组查询
QuerySet对象.annotate()
# annotate() 进行分组统计,按前面select 的字段进行 group by
# annotate() 返回值依然是 queryset对象,增加了分组统计后的键值对
模型对象.objects.values("id").annotate(course=Count('course__sid')).values('id','course')
# 查询指定模型, 按id分组 , 将course下的sid字段计数,返回结果是 name字段 和 course计数结果
# SQL原生语句中分组之后可以使用having过滤,在django中并没有提供having对应的方法,但是可以使用filter对分组结果进行过滤
# 所以filter在annotate之前,表示where,在annotate之后代表having
# 同理,values在annotate之前,代表分组的字段,在annotate之后代表数据查询结果返回的字段
(5)原生查询
执行原生SQL语句,也可以直接跳过模型,才通用原生pymysql.
ret = Student.objects.raw("SELECT id,name,age FROM db_student") # student 可以是任意一个模型
# 这样执行获取的结果无法通过QuerySet进行操作读取,只能循环提取
print(ret,type(ret))
for item in ret:
print(item,type(item))
6.4.5、修改记录
(1) 使用save更新数据
student = Student.objects.filter(name='刘德华').first()
print(student)
student.age = 19
student.classmate = "303"
# save之所以能提供给我们添加数据的同时,还可以更新数据的原因?
# save会找到模型的字段的主键id的值,
# 主键id的值如果是none,则表示当前数据没有被数据库,所以save会自动变成添加操作
# 主键id有值,则表示当前数据在数据库中已经存在,所以save会自动变成更新数据操作
student.save()
(2)update更新(推荐)
使用模型类.objects.filter().update(),会返回受影响的行数
# update是全局更新,只要符合更新的条件,则全部更新,因此强烈建议加上条件!!!
student = Student.objects.filter(name="赵华",age=22).update(name="刘芙蓉",sex=True)
print(student)
6.4.6、删除记录
删除有两种方法
(1)模型类对象.delete
student = Student.objects.get(id=13)
student.delete()
(2)模型类.objects.filter().delete()
Student.objects.filter(id=14).delete()
代码:
# 1. 先查询到数据模型对象。通过模型对象进行删除
# student = Student.objects.filter(pk=13).first()
# student.delete()
# 2. 直接删除
ret = Student.objects.filter(pk=100).delete()
print(ret)
# 务必写上条件,否则变成了清空表了。ret = Student.objects.filter().delete()
6.5、创建关联模型
-- 版本1
-- student
id name age class_name class_tutor class_num
1 rain 22 s12 zhangsan 78
2 alvin 24 s12 zhangsan 78
3 eric 23 s12 zhangsan 78
-- 版本2: 一对多是通过在多的表中创建关联字段
-- student
id name age class_id
1 rain 22 1
2 alvin 24 1
3 eric 23 1
-- class
id class_name class_tutor class_num
1 s12 zhangsan 78
2 s13 lisi 88
-- 查询学生rain所在班级名称
select class_id from student where name = 'rain' -- 1
select class_name from class where id = 1
-- 多对多的关系的确立是通过创建第三张关系表来完成的
-- course(选秀课程)
id name
1 python
2 java
3 php
-- student2course
id student_id course_id
1 1 1 -- id为1的学生选修了id为1的课程
2 1 2 -- id为1的学生选修了id为2的课程
3 2 2 -- id为2的学生选修了id为2的课程
-- 一对一 ,类似一对多,在两张关系表中的任何一张都可以建立一个关联字段
-- student
id name age class_id student_detail_id(unique)
1 rain 22 1 1
2 alvin 24 1 3
3 eric 23 1 2
-- student_detail
id addr email tel
1 bj 123 110
2 bj 234 911
3 nj 456 112
实例:我们来假定下面这些概念,字段和关系
- 班级模型: 班级名称、导员。
- 课程模型:课程名称、讲师等。
- 学生模型: 学生有姓名,年龄,只有一个班级,所以和班级表是一对多的关系(one-to-many);选修了多个课程,所以和课程表是多对多的关系(many-to-many)
- 学生详情:学生的家庭地址,手机号,邮箱等详细信息,和学生模型应该是一对一的关系(one-to-one)
模型建立如下:
from django.db import models
# Create your models here.
class Clas(models.Model):
name = models.CharField(max_length=32, unique=True, verbose_name="班级名称")
class Meta:
db_table = "db_class"
class Course(models.Model):
name = models.CharField(max_length=32, unique=True, verbose_name="课程名称")
class Meta:
db_table = "db_course"
class Student(models.Model):
sex_choices = (
(0, "女"),
(1, "男"),
(2, "保密"),
)
name = models.CharField(max_length=32, unique=True, verbose_name="姓名")
age = models.SmallIntegerField(verbose_name="年龄", default=18) # 年龄
sex = models.SmallIntegerField(choices=sex_choices)
birthday = models.DateField()
# 一对多
# on_delete= 关联关系的设置
# models.CASCADE 删除主键以后, 对应的外键所在数据也被删除
# models.DO_NOTHING 删除主键以后, 对应的外键不做任何修改
# 反向查找字段 related_name
clas = models.ForeignKey("Clas", on_delete=models.CASCADE)
# 多对多
# 建立多对多的关系,ManyToManyField可以建在两个模型中的任意一个,自动创建第三张表
courses = models.ManyToManyField("Course", db_table="db_student2course")
# 一对一,使用同一对多
stu_detail = models.OneToOneField("StudentDetail", on_delete=models.CASCADE)
class Meta:
db_table = "db_student"
def __str__(self):
return self.name
class StudentDetail(models.Model):
tel = models.CharField(max_length=32)
email = models.EmailField()
description = models.TextField(null=True, verbose_name="个性签名")
class Meta:
db_table = "db_student_detail"
6.6、关联添加
(1)一对多与一对一
stu = Student.objects.create(name="王五", age=23, sex=1, birthday="1991-11-12", clas_id=9, stu_detail_id=6)
print(stu.name)
print(stu.age)
print(stu.sex)
print(stu.clas_id) # 6
print(stu.stu_detail_id) # 5
print(stu.clas) # 模型类对象
print(stu.stu_detail) # 模型类对象
# 查询stu这个学生的班级名称
print(stu.clas.name)
# 查询stu这个学生的手机号
print(stu.stu_detail.tel)
(2)多对多
# stu = Student.objects.create(name="rain", age=33, sex=1, birthday="1996-11-12", clas_id=9, stu_detail_id=7)
# (1) 添加多对多的数据
# 添加多对多方式1
c1 = Course.objects.get(title="思修")
c2 = Course.objects.get(title="逻辑学")
stu.courses.add(c1,c2)
# 添加多对多方式2
stu = Student.objects.get(name="张三")
stu.courses.add(5,7)
# 添加多对多方式3
stu = Student.objects.get(name="李四")
stu.courses.add(*[6,7])
# (2) 删除多对多记录
stu = Student.objects.get(name="李四")
stu.courses.remove(7)
# (3) 清空多对多记录:clear方法
stu = Student.objects.get(name="rain")
stu.courses.clear()
# (4) 重置多对多记录:set方法
stu = Student.objects.get(name="李四")
stu.courses.set([5,8])
# (5) 多对多记录查询: all
# 查询李四所报课程的名称
stu = Student.objects.get(name="李四")
courses = stu.courses.all()
courses = stu.courses.all().values("title")
print(courses) # <QuerySet [<Course: Course object (5)>, <Course: Course object (8)>]>
6.7、关联查询
6.7.1、基于对象查询(子查询)
# ********************************** 一对多查询
# 查询张三所在班级的名称
# stu = Student.objects.get(name="张三")
# print(stu.clas.name)
# 查询计算机科学与技术2班有哪些学生
# clas = Clas.objects.get(name="计算机科学与技术2班")
# 反向查询方式1:
# ret = clas.student_set.all() # 反向查询按表名小写_set
# print(ret) # <QuerySet [<Student: 张三>, <Student: 李四>]>
# 反向查询方2:
# print(clas.student_list.all()) # <QuerySet [<Student: 张三>, <Student: 李四>]>
# ********************************** 一对一查询
# 查询李四的手机号
# stu = Student.objects.get(name="李四")
# print(stu.stu_detail.tel)
# 查询110手机号的学生姓名和年龄
# stu_detail = StudentDetail.objects.get(tel="110")
# 反向查询方式1: 表名小写
# print(stu_detail.student.name)
# print(stu_detail.student.age)
# 反向查询方式2: related_name
# print(stu_detail.stu.name)
# print(stu_detail.stu.age)
# ********************************** 多对多查询
# 查询张三所报课程的名称
# stu = Student.objects.get(name="张三")
# print(stu.courses.all()) # QuerySet [<Course: 近代史>, <Course: 篮球>]>
# 查询选修了近代史这门课程学生的姓名和年龄
# course = Course.objects.get(title="近代史")
# 反向查询方式1: 表名小写_set
# print(course.student_set.all()) # <QuerySet [<Student: 张三>, <Student: 李四>]>
# 反向查询方式2:related_name
# print(course.students.all())
# print(course.students.all().values("name","age")) # <QuerySet [{'name': '张三', 'age': 22}, {'name': '李四', 'age': 24}]>
(1)正向查询按字段
(2)反向查询按表名小写或者related_name
6.7.2、基于双下划线查询(join查询)
# 查询张三的年龄
ret = Student.objects.filter(name="张三").values("age")
print(ret) # <QuerySet [{'age': 22}]>
# (1) 查询年龄大于22的学生的姓名以及所在名称班级
# select db_student.name,db_class.name from db_student inner join db_class on db_student.clas_id = db_class.id where db_student.age>22;
# 方式1 : Student作为基表
ret = Student.objects.filter(age__gt=22).values("name","clas__name")
print(ret)
# 方式2 :Clas表作为基表
ret = Clas.objects.filter(student_list__age__gt=22).values("student_list__name","name")
print(ret)
# (2) 查询计算机科学与技术2班有哪些学生
ret = Clas.objects.filter(name="计算机科学与技术2班").values("student_list__name")
print(ret) #<QuerySet [{'student_list__name': '张三'}, {'student_list__name': '李四'}]>
# (3) 查询张三所报课程的名称
ret = Student.objects.filter(name="张三").values("courses__title")
print(ret) # <QuerySet [{'courses__title': '近代史'}, {'courses__title': '篮球'}]>
# (4) 查询选修了近代史这门课程学生的姓名和年龄
ret = Course.objects.filter(title="近代史").values("students__name","students__age")
print(ret) # <QuerySet [{'students__name': '张三', 'students__age': 22}, {'students__name': '李四', 'students__age': 24}]>
# (5) 查询李四的手机号
ret = Student.objects.filter(name='李四').values("stu_detail__tel")
print(ret) # <QuerySet [{'stu_detail__tel': '911'}]>
# (6) 查询手机号是110的学生的姓名和所在班级名称
# 方式1
ret = StudentDetail.objects.filter(tel="110").values("stu__name","stu__clas__name")
print(ret) # <QuerySet [{'stu__name': '张三', 'stu__clas__name': '计算机科学与技术2班'}]>
# 方式2:
ret = Student.objects.filter(stu_detail__tel="110").values("name","clas__name")
print(ret) # <QuerySet [{'name': '张三', 'clas__name': '计算机科学与技术2班'}]>
(1)正向关联按关联字段
(2)反向按表名小写或related_name
6.7.3、关联分组查询
# from django.db.models import Avg, Count, Max, Min
ret = Student.objects.values("sex").annotate(c = Count("name"))
print(ret) # <QuerySet [{'sex': 0, 'c': 1}, {'sex': 1, 'c': 3}]>
# (1)查询每一个班级的名称以及学生个数
ret = Clas.objects.values("name").annotate(c = Count("student_list__name"))
print(ret) # <QuerySet [{'name': '网络工程1班', 'c': 0}, {'name': '网络工程2班', 'c': 0}, {'name': '计算机科学与技术1班', 'c': 0}, {'name': '计算机科学与技术2班', 'c': 1}, {'name': '软件1班', 'c': 3}]>
# (2)查询每一个学生的姓名,年龄以及选修课程的个数
ret = Student.objects.values("name","age").annotate(c=Count("courses__title"))
print(ret) # <QuerySet [{'name': 'rain', 'c': 0}, {'name': '张三', 'c': 2}, {'name': '李四', 'c': 2}, {'name': '王五', 'c': 0}]>
ret = Student.objects.all().annotate(c=Count("courses__title")).values("name","age","sex","c")
# print(ret)
# (3) 每一个课程名称以及选修学生的个数
ret = Course.objects.all().annotate(c = Count("students__name")).values("title","c")
print(ret) # <QuerySet [{'title': '近代史', 'c': 2}, {'title': '思修', 'c': 0}, {'title': '篮球', 'c': 1}, {'title': '逻辑学', 'c': 1}, {'title': '轮滑', 'c': 0}]>
# (4) 查询选修课程个数大于1的学生姓名以及选修课程个数
ret = Student.objects.all().annotate(c=Count("courses__title")).filter(c__gt=1).values("name","c")
print(ret) # <QuerySet [{'name': '张三', 'c': 2}, {'name': '李四', 'c': 2}]>
# (5) 查询每一个学生的姓名以及选修课程个数并按着选修的课程个数进行从低到高排序
ret = Student.objects.all().annotate(c=Count("courses__title")).order_by("c").values("name","c")
print(ret)
6.8、项目练习
标签:
相关文章
最新发布
- 【Python】selenium安装+Microsoft Edge驱动器下载配置流程
- Python 中自动打开网页并点击[自动化脚本],Selenium
- Anaconda基础使用
- 【Python】成功解决 TypeError: ‘<‘ not supported between instances of ‘str’ and ‘int’
- manim边学边做--三维的点和线
- CPython是最常用的Python解释器之一,也是Python官方实现。它是用C语言编写的,旨在提供一个高效且易于使用的Python解释器。
- Anaconda安装配置Jupyter(2024最新版)
- Python中读取Excel最快的几种方法!
- Python某城市美食商家爬虫数据可视化分析和推荐查询系统毕业设计论文开题报告
- 如何使用 Python 批量检测和转换 JSONL 文件编码为 UTF-8
点击排行
- 版本匹配指南:Numpy版本和Python版本的对应关系
- 版本匹配指南:PyTorch版本、torchvision 版本和Python版本的对应关系
- Python 可视化 web 神器:streamlit、Gradio、dash、nicegui;低代码 Python Web 框架:PyWebIO
- 相关性分析——Pearson相关系数+热力图(附data和Python完整代码)
- Anaconda版本和Python版本对应关系(持续更新...)
- Python与PyTorch的版本对应
- Windows上安装 Python 环境并配置环境变量 (超详细教程)
- Python pyinstaller打包exe最完整教程
本站推荐
