首页 > Python资料 博客日记
Python高分大数据分析与挖掘大作业
2024-07-02 23:00:04Python资料围观115次
题目一——线性代数计算
1.创建一个Python脚本,命名为test1.py,完成以下功能。
(1)生成两个3×3矩阵,并计算矩阵的乘积。
(2)求矩阵A=-110-430102 的特征值和特征向量。
的特征值和特征向量。
(3)设有矩阵A=521201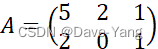 ,试对其进行奇异分解。
,试对其进行奇异分解。
求解过程
import numpy as np
mat1 = np.matrix([[3,6,9],[7,8,10],[11,15,19]])
mat2 = np.matrix([[1,2,3],[6,9,10],[12,13,15]])
mat3 = mat1 * mat2
print(mat3)
mat4 = np.matrix([[-1,1,0],[-4,3,0],[1,0,2]])
mat4_value, mat4_vector = np.linalg.eig(mat4)
print('特征值为:',mat4_value)
print('特征向量为:',mat4_vector)
mat5 = np.matrix([[5,2,1],[2,0,1]])
U, Sigma, V = np.linalg.svd(mat5, full_matrices=False)
题目二——线性回归预测
2.油气藏的储量密度Y与生油门限以下平均地温梯度X1、生油门限以下总有机碳百分比X2、生油岩体积与沉积岩体积百分比X3、砂泥岩厚度百分比X4、有机转化率X5有关,数据数据集(datat11)。根据数据集信息完成如下任务:
(1)利用线性回归分析命令,求出Y与5个因素之间的线性回归关系式系数向量(包括常数项),并在命令窗口输出该系数向量。
(2)求出线性回归关系的判定系数。
(3)今有一个样本X1=3.5,X2=1.8,X3=8,X4=17,X5=10,试预测该样本的Y值。
| 油气存储特征数据 | |||||
| X1 | X2 | X3 | X4 | X5 | Y |
| 3.18 | 1.15 | 9.4 | 17.6 | 3 | 0.7 |
| 3.8 | 0.79 | 5.1 | 30.5 | 3.8 | 0.7 |
| 3.6 | 1.1 | 9.2 | 9.1 | 3.65 | 1 |
| 2.73 | 0.73 | 14.5 | 12.8 | 4.68 | 1.1 |
| 3.4 | 1.48 | 7.6 | 16.5 | 4.5 | 1.5 |
| 3.2 | 1 | 10.8 | 10.1 | 8.1 | 2.6 |
| 2.6 | 0.61 | 7.3 | 16.1 | 16.16 | 2.7 |
| 4.1 | 2.3 | 3.7 | 17.8 | 6.7 | 3.1 |
| 3.72 | 1.94 | 9.9 | 36.1 | 4.1 | 6.1 |
| 4.1 | 1.66 | 8.2 | 29.4 | 13 | 9.6 |
| 3.35 | 1.25 | 7.8 | 27.8 | 10.5 | 10.9 |
| 3.31 | 1.81 | 10.7 | 9.3 | 10.9 | 11.9 |
| 3.6 | 1.4 | 24.6 | 12.6 | 12.76 | 12.7 |
| 3.5 | 1.39 | 21.3 | 41.1 | 10 | 14.7 |
| 4.75 | 2.4 | 26.2 | 42.5 | 16.4 | 21.3 |
| 3.32 | 1.45 | 8.1 | 18.6 | 11 | 11.4 |
| 4.12 | 1.89 | 23.7 | 21 | 13.2 | |
| 3.8 | 1.7 | 20.5 | 26.4 | 10.9 |
求解
import pandas as pd
import numpy as np
data = pd.read_excel('data11.xlsx')
prex = data.iloc[2:20,0:5].values
prey = data.iloc[2:20,5].values
prey = prey.reshape(-1,1)
from sklearn.impute import SimpleImputer
imp = SimpleImputer(missing_values=np.nan, strategy='mean')
imp.fit(prex)
x = imp.transform(prex)
y = imp.fit_transform(prey)
from sklearn.linear_model import LinearRegression as LR
lr = LR()
lr.fit(x,y)
Slr = lr.score(x,y)
c_x = lr.coef_
c_b = lr.intercept_
x1 = np.array([3.5,1.8,8,17,10])
x1 = x1.reshape(1,-1)
R1 = lr.predict(x1)
print('x回归系数为:',c_x)
print('回归系数的常数项为:',c_b)
print('判定系数为:',Slr)
print('样本预测值为:',R1)
题目三——Apriori关联规则挖掘
3. 假设有顾客在超市的购买记录数据集(data22),每行代表一个顾客在超市的购买记录。完成下列任务:
(1)试利用关联规则支持度和置信度定义挖掘出任意两个商品之间的关联规则。
(2)试利用Apriori关联规则挖掘算法函数进行关联规则挖掘。
最小支持度和最小置信度分别为0.2和0.4。
| 顾客在超市的购买记录 | |||
| I1 | 西红柿、排骨、鸡蛋、毛巾、水果刀、苹果 | ||
| I2 | 西红柿、茄子、水果刀、香蕉 | ||
| I3 | 鸡蛋、袜子、毛巾、肥皂、苹果、水果刀 | ||
| I4 | 西红柿、排骨、茄子、毛巾、水果刀 | ||
| I5 | 西红柿、排骨、酸奶、苹果 | ||
| I6 | 鸡蛋、茄子、酸奶、肥皂、苹果、香蕉 | ||
| I7 | 排骨、鸡蛋、茄子、水果刀、苹果 | ||
| I8 | 土豆、鸡蛋、袜子、香蕉、苹果、水果刀 | ||
| I9 | 鸡蛋、排骨、鞋子、土豆 | ||
| I10 | 西红柿、排骨、香蕉、苹果 | ||
| I11 | 西红柿、排骨、水果刀、土豆、香蕉、苹果 |
求解
import pandas as pd
import numpy as np
item = ['西红柿','排骨','鸡蛋','毛巾','水果刀','香蕉','苹果','酸奶','土豆','鞋子','肥皂','茄子','袜子']
data = pd.read_excel('data22.xlsx',header=None)
data = data.iloc[1:,1:]
di = {}
for i in range(0,11):
di.setdefault(i,data.iloc[i,0].split('、'))
while(len(di[i])<6):
di[i].append(np.nan)
Di = pd.DataFrame(di)
D = {}
for t in range(len(item)):
z = np.zeros(len(data))
li = list()
for k in range(len(Di.iloc[:,0])):
s = Di.iloc[k-1,:] == item[t]
li.extend(list(s[s.values==True].index))
z[li]=1
D.setdefault(item[t],z)
Data = pd.DataFrame(D)
#挖掘关联规则
c = list(Data.columns)
c0 = 0.4
s0 = 0.2
list1 = []
list2 = []
list3 = []
for k in range(len(c)):
for q in range(len(c)):
if c[k] != c[q]:
c1 = Data[c[k]]
c2 = Data[c[q]]
I1 = c1.values == 1
I2 = c2.values == 1
t12 = np.zeros(len(c1))
t1 = np.zeros(len(c1))
t12[I1&I2] = 1
t1[I1] = 1
sp = sum(t12)/len(c1)
co = sum(t12)/sum(t1)
if co>=c0 and sp>= s0:
list1.append(c[k]+'--'+c[q])
list2.append(sp)
list3.append(co)
R = {'rule':list1,'support':list2,'confidence':list3}
R = pd.DataFrame(R)
R.to_excel('rule1.xlsx')
#Apriori挖掘
import apriori
outputfile = 'apriori_rules.xlsx'
support = 0.2
confidence = 0.4
ms = '---'
apriori.find_rule(Data, support, confidence, ms).to_excel(outputfile)
# apriori
import pandas as pd
def connect_string(x,ms):
x = list(map(lambda i:sorted(i.split(ms)),x))
l = len(x[0])
r = []
for i in range(len(x)):
for j in range(i,len(x)):
if x[i][:l-1]==x[j][:l-1] and x[i][l-1] != x[j][l-1]:
r.append(x[i][:l-1]+sorted([x[j][l-1],x[i][l-1]]))
return r
def find_rule(d, support, confidence, ms = u'--'):
result = pd.DataFrame(index=['support','confidence'])
support_series = 1.0*d.sum()/len(d)
column = list(support_series[support_series > support].index)
k = 0
while len(column) > 1:
k = k+1
print(u'|n正在进行第%s次搜索...' %k)
column = connect_string(column, ms)
print(u'数目:%s...' %len(column))
sf = lambda i: d[i].prod(axis=1, numeric_only = True)
d_2 = pd.DataFrame(list(map(sf,column)), index = [ms.join(i) for i in column]).T
support_series_2 = 1.0*d_2[[ms.join(i) for i in column]].sum()/len(d)
column = list(support_series_2[support_series_2 > support].index)
support_series = support_series.append(support_series_2)
column2 = []
for i in column:
i = i.split(ms)
for j in range(len(i)):
column2.append(i[:j]+i[j+1:]+i[j:j+1])
confidence_series = pd.Series(index = [ms.join(i) for i in column2])
for i in column2:
confidence_series[ms.join(i)]= support_series[ms.join(sorted(i))]/support_series[ms.join(i[:len(i)-1])]
for i in confidence_series[confidence_series > confidence].index:
result[i] = 0.0
result[i]['confidence'] = confidence_series[i]
result[i]['support'] = support_series[ms.join(sorted(i.split(ms)))]
result = result.T.sort_values(['confidence','support'],ascending = False)
print(u'\n结果为:')
print(result)
return result
题目四——可视化+K-means聚类
36个城市居民消费价格指数(2018.10—202109)的数据(data33)。完成下列任务:
(1)画出北京、南京、合肥、西安四个城市城市居民消费价格指数按月变化的趋势图;
(2)对36个城市居民消费价格指数建立分类模型,并进行分类比较分析。
部分数据如下:(第一行为时间序列)
| 地区 | 202109 | 202108 | 202107 | 202106 |
| 北京 | 101.2 | 101.4 | 101.5 | 100.9 |
| 天津 | 101 | 101.3 | 102 | 101.5 |
| 石家庄 | 100.3 | 100.8 | 101 | 100.8 |
| 太原 | 101 | 101.2 | 101.2 | 100.6 |
| 呼和浩特 | 100.3 | 101 | 101.2 | 101.1 |
| 沈阳 | 100.3 | 101.2 | 101.5 | 101.7 |
| 大连 | 101.1 | 101.6 | 101.6 | 101.4 |
| 长春 | 100.2 | 101.4 | 101 | 100.6 |
| 哈尔滨 | 101.2 | 101.5 | 101.8 | 100.4 |
| 上海 | 101.1 | 101.3 | 101.3 | 101.2 |
| 南京 | 101.3 | 101.5 | 101.8 | 101.8 |
| 杭州 | 101.5 | 101 | 101.2 | 101.2 |
| 宁波 | 101.7 | 101.9 | 102.3 | 102.6 |
| 合肥 | 102.1 | 102 | 102 | 101.9 |
求解
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
data = pd.read_excel('data33.xlsx')
data = data.iloc[0:36,:]
beijing = data.iloc[0,1:]
beijing = beijing.sort_index().values
nanjing = data.iloc[10,1:]
nanjing = nanjing.sort_index().values
hefei = data.iloc[13,1:]
hefei = hefei.sort_index().values
xian = data.iloc[31,1:]
xian = xian.sort_index().values
month = ['2018.10','2018.11','2018.12','2019.01','2019.02','2019.03','2019.04'
,'2019.05','2019.06','2019.07','2019.08','2019.09','2019.10','2019.11'
,'2019.12','2020.01','2020.02','2020.03','2020.04','2020.05','2020.06'
,'2020.07','2020.08','2020.09','2020,10','2020.11','2020.12','2021.01'
,'2021.02','2021.03','2021.04','2021.05','2021.06','2021.07','2021.08'
,'2021.09']
plt.rcParams['font.sans-serif'] = 'SimHei'
plt.rcParams['axes.unicode_minus'] = False
#北京图表
plt.figure(1)
plt.title('北京居民消费指数月变化趋势图')
plt.xlabel('日期')
plt.ylabel('消费价格指数')
plt.xlim((0,36))
plt.ylim((99,105))
plt.yticks([99,100,101,102,103,104,105,106])
plt.xticks(range(0,36))
v = np.array(list(range(0,36)))
plt.plot(v,beijing)
plt.xticks(v,month,rotation=90)
plt.show()
#南京图表
plt.figure(2)
plt.title('南京居民消费指数月变化趋势图')
plt.xlabel('日期')
plt.ylabel('消费价格指数')
plt.xlim((0,36))
plt.ylim((99,106))
plt.yticks([99,100,101,102,103,104,105,106])
plt.xticks(range(0,36))
v = np.array(list(range(0,36)))
plt.plot(v,nanjing)
plt.xticks(v,month,rotation=90)
plt.show()
#合肥图表
plt.figure(3)
plt.title('合肥居民消费指数月变化趋势图')
plt.xlabel('日期')
plt.ylabel('消费价格指数')
plt.xlim((0,36))
plt.ylim((99,106))
plt.yticks([99,100,101,102,103,104,105,106])
plt.xticks(range(0,36))
v = np.array(list(range(0,36)))
plt.plot(v,hefei)
plt.xticks(v,month,rotation=90)
#西安图表
plt.figure(4)
plt.title('西安居民消费指数月变化趋势图')
plt.xlabel('日期')
plt.ylabel('消费价格指数')
plt.xlim((0,36))
plt.ylim((99,106))
plt.yticks([99,100,101,102,103,104,105,106])
plt.xticks(range(0,36))
v = np.array(list(range(0,36)))
plt.plot(v,xian)
plt.xticks(v,month,rotation=90)
#k-均值聚类分析
from sklearn.cluster import KMeans
model = KMeans(n_clusters = 4, random_state=0, max_iter = 500)
X = data.iloc[:,1:]
model.fit(X)
c = model.labels_
Fs = pd.Series(c,index=data['地区'])
Fs = Fs.sort_values(ascending=True)
print(Fs)
题目五——神经网络预测
5、国有控股工业企业主要经济指标的数据(data44)。完成下列任务:
(1)分别建立数据集data1(DQ,B1); data2(DQ,C1,C2); data3(DQ,D1,D2,D3,D4,D5,D6,D7); data4(DQ,E1,E2); data5(DQ,F1,F2,F3,F4),并进行基本数据信息分析(如给出各指标的平均值、最大值、最小值等);
(2)根据数据集data1(DQ,B1)信息,分析各个地区的占比情况,画出饼图、箱线图;
(3)根据数据集data3,data5的信息,建立模型,进行地区排序;
(4)根据数据集data2,data4的信息,建立模型,分析工业销售产值与出口交货值、固定资产原价与生产经营用关系。
部分数据如下:
| 国有控股工业企业主要经济指标 | |||||
| DQ | A1 | A2 | B1 | C1 | C2 |
| 北 京 | 2144 | 754 | 3231.99 | 3192.35 | 161.12 |
| 天 津 | 1884 | 868 | 2045.09 | 2036.33 | 96.94 |
| 河 北 | 1498 | 551 | 3359.5 | 3337.75 | 118.12 |
| 山 西 | 1556 | 392 | 1950.51 | 1922.85 | 131.47 |
| 内蒙古 | 509 | 163 | 1110.21 | 1109.42 | 47.45 |
| 辽 宁 | 2139 | 956 | 4881.66 | 4817.51 | 418.95 |
| 吉 林 | 1258 | 489 | 2337.42 | 2327.55 | 42.41 |
| 黑龙江 | 1253 | 517 | 2881.81 | 2838.15 | 49.12 |
| 上 海 | 1830 | 509 | 5395.41 | 5343.26 | 522.16 |
| 江 苏 | 1172 | 377 | 3950.96 | 3911.26 | 355.73 |
求解
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
data = pd.read_excel('data44.xlsx',header = None)
data = data.iloc[2:32,:]
data.index = range(30)
data1 = data.iloc[:,[0,3]]
data1_col = ['地区','工业总产值']
data1.columns = data1_col
R1max = data1.iloc[:,[1]].max()
R1min = data1.iloc[:,[1]].min()
R1mean = data1.iloc[:,[1]].mean()
print('最大值为{},最小值为{},平均值为{}。'.format(R1max,R1min,R1mean))
data2 = data.iloc[:,[0,4,5]]
data2_col = ['地区','工业销售产值','出口交货值']
data2.columns = data2_col
R2max = data2.iloc[:,1:].max()
R2min = data2.iloc[:,1:].min()
R2mean = data2.iloc[:,1:].mean()
print('最大值为{},最小值为{},平均值为{}。'.format(R2max,R2min,R2mean))
data3 = data.iloc[:,[0,6,7,8,9,10,11,12]]
data3_col = ['地区','资产合计','流动资产合计','应收账款净额','存货','产成品','流动资产','固定资产合计']
data3.columns = data3_col
R3max = data3.iloc[:,1:].max()
R3min = data3.iloc[:,1:].mean()
R3mean = data3.iloc[:,1:].mean()
print('最大值为{},最小值为{},平均值为{}。'.format(R3max,R3min,R3mean))
data4 = data.iloc[:,[0,13,14]]
data4_col = ['地区','固定资产原价','生产经营']
data4.columns = data4_col
R4max = data4.iloc[:,1:].max()
R4min = data4.iloc[:,1:].min()
R4mean = data4.iloc[:,1:].mean()
print('最大值为{},最小值为{},平均值为{}。'.format(R4max,R4min,R4mean))
data5 = data.iloc[:,[0,15,16,17,18]]
data5_col = ['地区','累计折旧','本年折旧','固定资产净值','固定资产净值(年平均余额)']
data5.columns = data5_col
R5max = data5.iloc[:,1:].max()
R5min = data5.iloc[:,1:].min()
R5mean = data5.iloc[:,1:].mean()
print('最大值为{},最小值为{},平均值为{}。'.format(R5max,R5min,R5mean))
#绘制饼图
y = data1['地区']
x = data1['工业总产值'].values
plt.figure(1)
plt.rcParams['font.sans-serif'] = 'SimHei'
plt.rcParams['axes.unicode_minus'] = False
plt.pie(x,labels = y, autopct = '%1.2f%%')
plt.title('各地区工业总产值百分比分布图')
#绘制箱线图
plt.figure(2)
plt.title('工业总产值箱线图')
plt.xlabel('District')
plt.ylabel('工业生产总值')
plt.boxplot([x])
#data3,data5主成分分析
df = pd.merge(data3,data5, how = 'left',on = ['地区'])
M = df.iloc[:,1:]
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler(M)
scaler.fit(M)
from sklearn.decomposition import PCA
pca = PCA(n_components = 0.95)
pca.fit(M)
Y = pca.transform(M)
tzxl = pca.components_
tz = pca.explained_variance_
gxl = pca.explained_variance_ratio_
F = gxl[0]*Y[:,0] + gxl[1]*Y[:,1]
dq = list(df['地区'].values)
Rs = pd.Series(F,index = dq)
Rs = Rs.sort_values(ascending = False)
#data2,data4数据分析(神经网络回归模型)
from sklearn.neural_network import MLPRegressor
clf = MLPRegressor(solver = 'lbfgs', hidden_layer_sizes=8, random_state=1)
x1 = data2.iloc[:29,[1]]
y1 = data2.iloc[:29,[2]]
x2 = data4.iloc[:29,[1]]
y2 = data4.iloc[:29,[2]]
clf.fit(x1,y1)
clf.fit(x2,y2)
x1_predict = data2.iloc[29:,[1]]
x2_predict = data4.iloc[29:,[1]]
R1 = clf.predict(x1_predict)
R2 = clf.predict(x2_predict)
print('以前29组数据为训练对象,预测第30组数据,得到结果为:{},真实结果为:15.72'.format(R1))
print('以前29组数据为训练对象,预测第30组数据,得到结果为:{},真实结果为:381.11'.format(R2))
标签:
相关文章
最新发布
- 【Python】selenium安装+Microsoft Edge驱动器下载配置流程
- Python 中自动打开网页并点击[自动化脚本],Selenium
- Anaconda基础使用
- 【Python】成功解决 TypeError: ‘<‘ not supported between instances of ‘str’ and ‘int’
- manim边学边做--三维的点和线
- CPython是最常用的Python解释器之一,也是Python官方实现。它是用C语言编写的,旨在提供一个高效且易于使用的Python解释器。
- Anaconda安装配置Jupyter(2024最新版)
- Python中读取Excel最快的几种方法!
- Python某城市美食商家爬虫数据可视化分析和推荐查询系统毕业设计论文开题报告
- 如何使用 Python 批量检测和转换 JSONL 文件编码为 UTF-8
点击排行
- 版本匹配指南:Numpy版本和Python版本的对应关系
- 版本匹配指南:PyTorch版本、torchvision 版本和Python版本的对应关系
- Python 可视化 web 神器:streamlit、Gradio、dash、nicegui;低代码 Python Web 框架:PyWebIO
- 相关性分析——Pearson相关系数+热力图(附data和Python完整代码)
- Python与PyTorch的版本对应
- Anaconda版本和Python版本对应关系(持续更新...)
- Python pyinstaller打包exe最完整教程
- Windows上安装 Python 环境并配置环境变量 (超详细教程)
本站推荐
