首页 > Python资料 博客日记
天池学习赛:保险反欺诈预测(附代码)
2024-07-03 15:00:05Python资料围观234次
前言
本案例还是对比了xgboost及catboost,最终catboost更胜一筹,线上测试取得了更高的成绩,shap的代码还是根据xgboost模型输出,catboost也附带有shap,感兴趣的可以自己尝试下。
所有的数据结论也仅是从本次样本数据集得出的结论,并不代表总体。
一、赛题介绍
以保险风控为背景,保险是重要的金融体系,对社会发展,民生保障起到重要作用。保险欺诈近些年层出不穷,在某些险种上保险欺诈的金额已经占到了理赔金额的20%甚至更多。对保险欺诈的识别成为保险行业中的关键应用场景。
训练集700条,38个特征;测试集300条,数据量不大,数据应该来源于国外,相关特征参考官网【教学赛】金融数据分析赛题2:保险反欺诈预测赛题与数据-天池大赛-阿里云天池
二、数据描述性统计
1.查看缺失值、重复值、统计目标变量比例
import pandas as pd
df=pd.read_csv("/train.csv")
test=pd.read_csv("/testA.csv")
(df['fraud'].value_counts()/len(df)).round(2) #统计目标变量比例
0 0.74
1 0.26
# 比例1:3
print(df.isnull().any(axis=1).sum()) # 缺失值记录数
df[df.duplicated()==True]#打印重复值
###############################
# 输出
0
policy_id age customer_months policy_bind_date policy_state policy_csl policy_deductable policy_annual_premium umbrella_limit insured_zip ... witnesses police_report_available total_claim_amount injury_claim property_claim vehicle_claim auto_make auto_model auto_year fraud
0 rows × 38 columns
# 无缺失值及重复值2.查看异常值
import matplotlib.pyplot as plt
# 分离数值变量与分类变量
Nu_feature = list(df.select_dtypes(exclude=['object']).columns) # 数值变量
Ca_feature = list(df.select_dtypes(include=['object']).columns)
# 绘制箱线图
plt.figure(figsize=(30,30)) # 箱线图查看数值型变量异常值
i=1
for col in Nu_feature:
ax=plt.subplot(4,5,i)
ax=sns.boxplot(data=df[col])
ax.set_xlabel(col)
ax.set_ylabel('Frequency')
i+=1
plt.show()
# 结合原始数据及经验,真正的异常值只有umbrella_limit这一个变量,有一个-1000000的异常值,但测试集没有,可以忽略不管
针对异常值可以结合业务经验判断,不要盲目删除及自行更改。
3.查看训练集与测试集数据分布
3.1 查看数值变量
import seaborn as sns
import warnings
warnings.filterwarnings("ignore")
plt.figure(figsize=(30,25))
i=1
for col in Nu_feature:
ax=plt.subplot(4,5,i)
ax=sns.kdeplot(df[col],color='red')
ax=sns.kdeplot(test[col],color='cyan')
ax.set_xlabel(col)
ax.set_ylabel('Frequency')
ax=ax.legend(['train','test'])
i+=1
plt.show()
3.2 查看部分分类变量
col1=[ 'policy_state', 'insured_sex', 'insured_education_level', 'insured_relationship', 'incident_type', 'authorities_contacted', \
'incident_state', 'auto_make']
plt.figure(figsize=(20,10))
j=1
for col in col1:
ax=plt.subplot(4,4,j)
ax=plt.scatter(x=range(len(df)),y=df[col],color='red')
plt.title(col)
j+=1
k=9
for col in col1:
ax=plt.subplot(4,4,k)
ax=plt.scatter(x=range(len(test)),y=test[col],color='cyan')
plt.title(col)
k+=1
plt.subplots_adjust(wspace=0.4,hspace=0.3) # 调整图间距
plt.show()
结论:数据集分布一致。
4. 数据相关性
correlation_matrix=df.corr()
plt.figure(figsize=(12,10))
sns.heatmap(correlation_matrix,vmax=0.9,linewidths=0.05,cmap="RdGy")
# 特征相关性的数据是经过处理后的数据,包括构造了一个车辆年限,日期变量的分解,非原始读取数据
出险类型(单车、多车、停放受损等)与碰撞类型(前部、后部、侧面等)、索赔金额类型之间的相关性比较高,毕竟单车事故、多车事故、碰撞部位的损失程度直接与索赔金额有关。
目标变量与各变量之间的相关性没有特别突出。
三. 部分分类特征可视化
可视化使用power bi实现,代码实现有点麻烦,偷懒一下。

欺诈样本主要分布在损失程度较大,单车及三车事故,碰撞类型后部碰撞最高
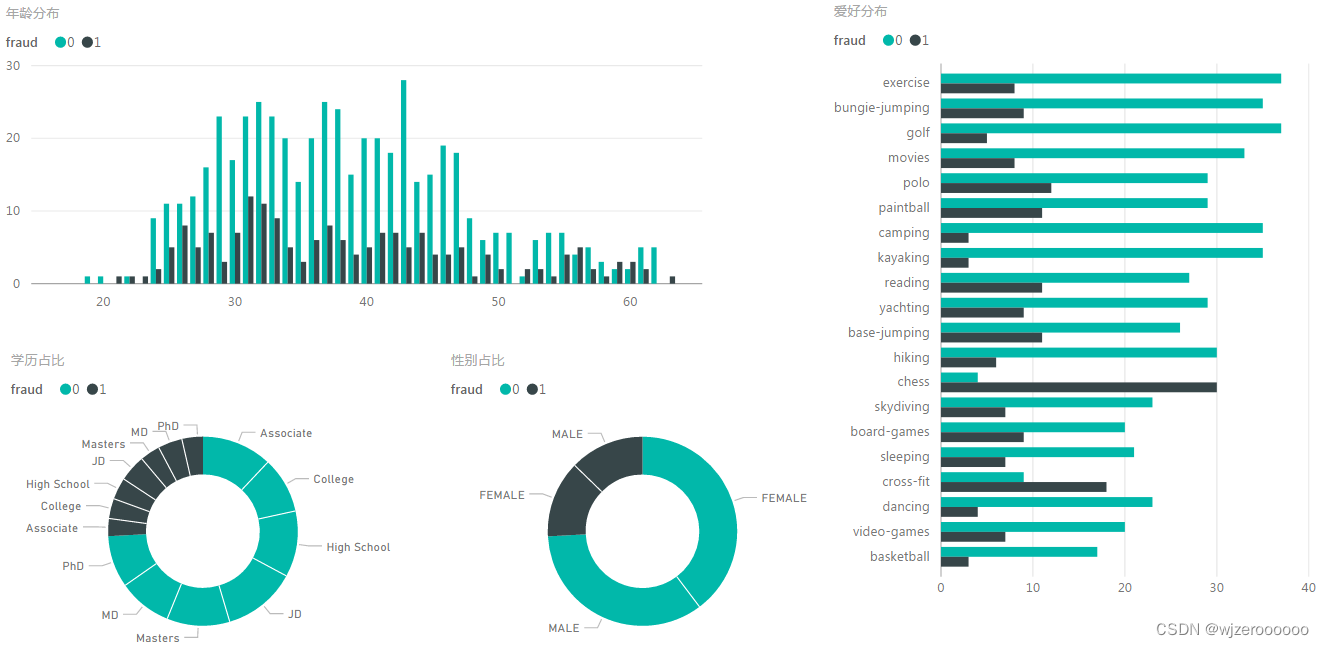
性别和学历差别不大,年龄分布在30-40居多,爱好以国际象棋(善于思考)及运动(具有冒险精神)居多。
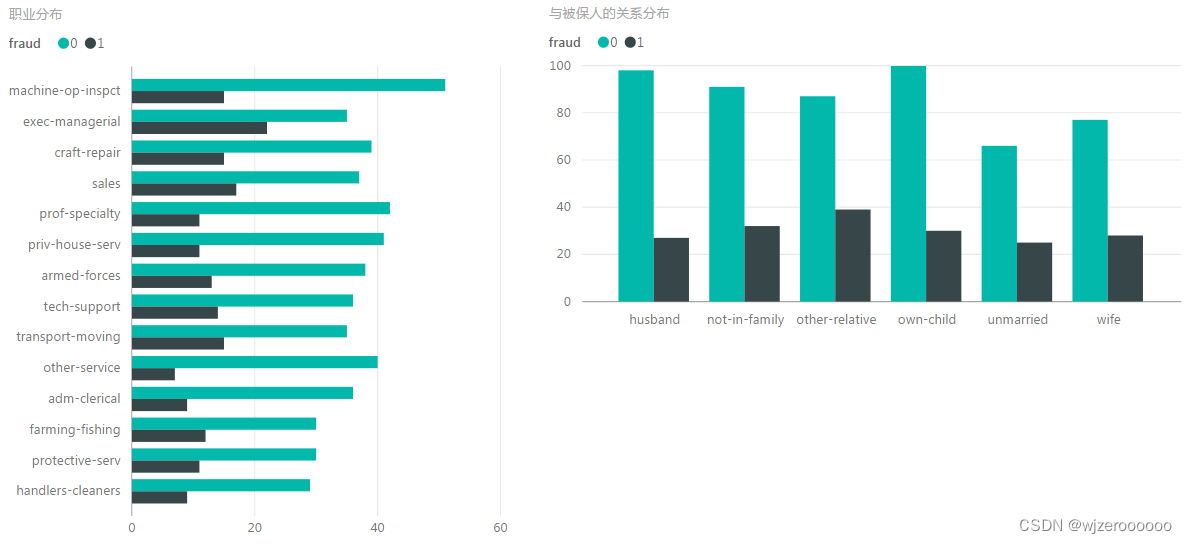
与被保人关系相对平均,职业以从事管理的最多。

时间点白天较高(夜间作案的风险更高)、车辆年限(本数据集样本出险时间基本是2015年)主要是2000-2010年的老旧车型为主,符合低买高保,故意碰撞全损的特质。
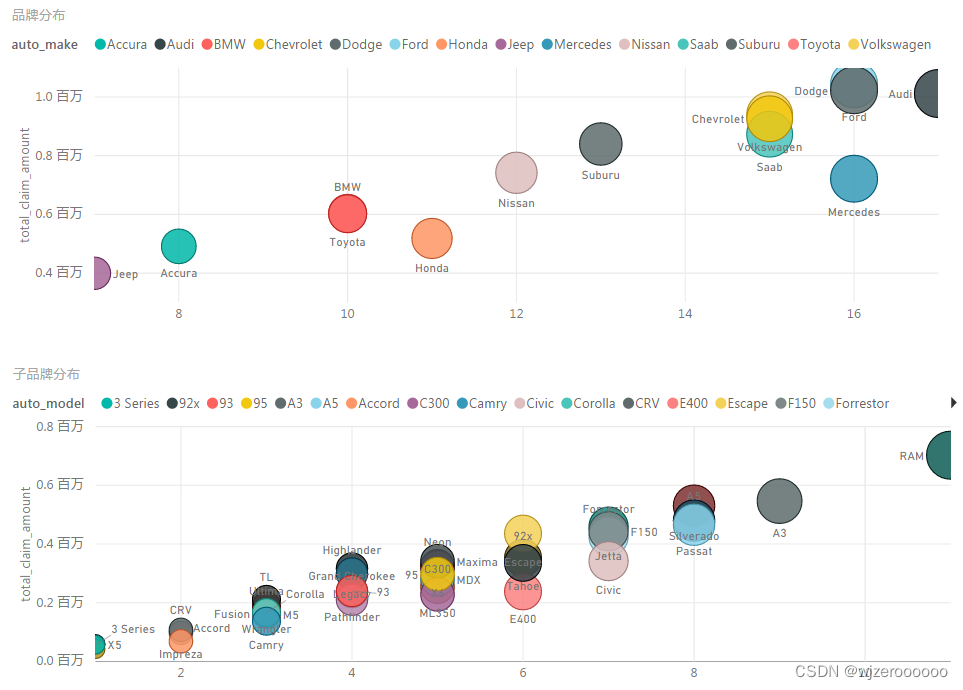 品牌方面以奥迪、福特、道奇、大众、奔驰等高端车型为主,5年以上车型,低价买进,高额承保,全损赚取差价,低端车型没有作案价值,所以以高端车型为主,本数据集还有皮卡车的,这在国内不多见。
品牌方面以奥迪、福特、道奇、大众、奔驰等高端车型为主,5年以上车型,低价买进,高额承保,全损赚取差价,低端车型没有作案价值,所以以高端车型为主,本数据集还有皮卡车的,这在国内不多见。
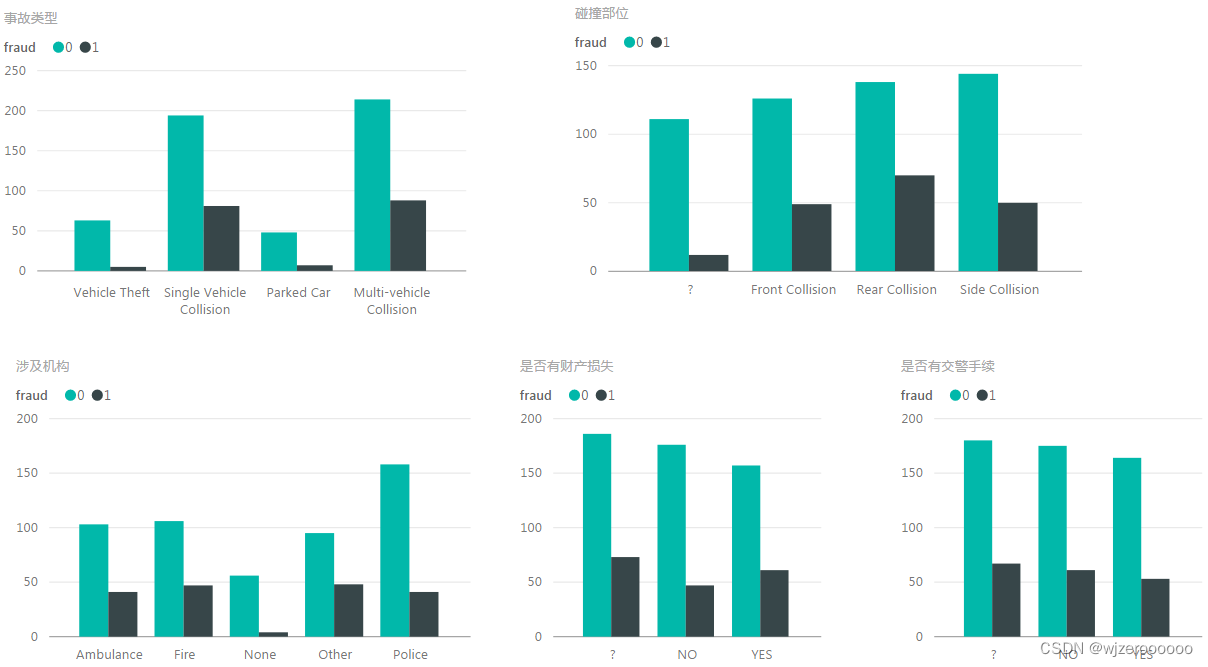
其他特征就不过多解释了,还是那句话,本数据集仅做为样本,特征与国内情况有一定相似,但不能完全反映目前国内的保险欺诈情况。
四. 特征处理
4.1 平均数编码
主要是针对分类变量的处理,将线上成绩从0.96提升到了0.97。
import datetime # 将日期列分解成年、月、日
df['policy_bind_date']=pd.to_datetime(df['policy_bind_date'])
df['policy_bind_date_year']=df['policy_bind_date'].dt.year.astype('int64')
df['policy_bind_date_month']=df['policy_bind_date'].dt.month.astype('int64')
df['policy_bind_date_day']=df['policy_bind_date'].dt.day.astype('int64')
df['incident_date']=pd.to_datetime(df['incident_date'])
df['incident_date_year']=df['incident_date'].dt.year.astype('int64')
df['incident_date_month']=df['incident_date'].dt.month.astype('int64')
df['incident_date_day']=df['incident_date'].dt.day.astype('int64')
df['auto_year']=df['auto_year'].astype('int64')
#####################################
import Meancoder # 平均数编码
X_data=df.drop(columns=['policy_id','policy_bind_date','incident_date','fraud'])
Y_data=df['fraud']
class_list = [‘放入你要处理的特征’]
MeanEnocodeFeature = class_list # 声明需要平均数编码的特征
ME = Meancoder.MeanEncoder(MeanEnocodeFeature,target_type='classification') # 声明平均数编码的类
X_data = ME.fit_transform(X_data,Y_data) # 对训练数据集的X和y进行拟合
test = ME.transform(test)#对测试集进行编码class_list是你要处理的特征,可以是一个或多个,本人也是试了很多组合,在线上测试了很多次,建议可以对类别数大于10个的特征进行处理,特征类别数太少就不建议用平均数编码。
4.2 其余分类特征编码
from sklearn.preprocessing import LabelEncoder
lb = LabelEncoder()
cols = Ca_feature
for j in cols:
df[j] = lb.fit_transform(df[j])
# 如果前面对某些特特征做了平均数编码,此处就将这些特征删除,再进行编码说明:测试集也要一起做特征处理
五. 数据建模
可能是主办方将数据集处理的比较好,所以会出现线上验证比线下测试高很多的情况,即使用默认的参数,也可以轻松达到线上0.9以上的效果,以下是尝试的情况。
| xgboost | 测试0.8 |
| catboost | 测试0.849/线上0.961 |
| catboost+(meancoder尝试1) | 测试0.856/线上0.956 |
| catboost+(meancoder尝试2) | 测试0.862/线上0.959 |
| catboost+(meancoder尝试3) | 测试0.852/线上0.9502 |
| catboost+(meancoder尝试4) | 测试0.874/线上0.97 |
from catboost import CatBoostClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import roc_auc_score
col=Ca_feature
X_data[col] = X_data[col].astype('str')
testA[col] = testA[col].astype('str')
# 划分训练及测试集
x_train,x_test,y_train,y_test = train_test_split( X_data, Y_data,test_size=0.3,random_state=1,stratify=Y)
# 模型训练
clf=CatBoostClassifier()
clf.fit(x_train,y_train,verbose=500,cat_features=col)
y_pred=clf.predict_proba(x_test)[:,1]
print('验证集auc:{}'.format(roc_auc_score(y_test, y_pred)))


平均数编码+模型调参可以将精度小幅度提高,感兴趣的朋友可以多做一些尝试。
六. shap归因展示
6.1 特征输出
plot_importance(clf,height=0.5,importance_type='gain',max_num_features=10,xlabel='Gain Split',grid=False)
plt.show() # xgboost特征输出
import shap # shap特征输出
explainer = shap.TreeExplainer(clf)
shap_values = explainer.shap_values(X_data)
shap.summary_plot(shap_values, X_data, plot_type="bar",max_display = 10)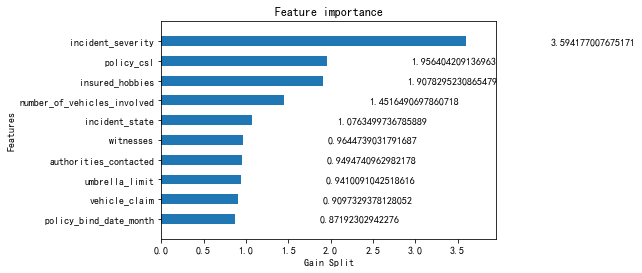

特征顺序有一定不同,但影响最大的还是incident_severity(事故严重程度)这个特征。
6.2. 正负影响
shap.summary_plot(shap_values, X_data ,max_display = 10)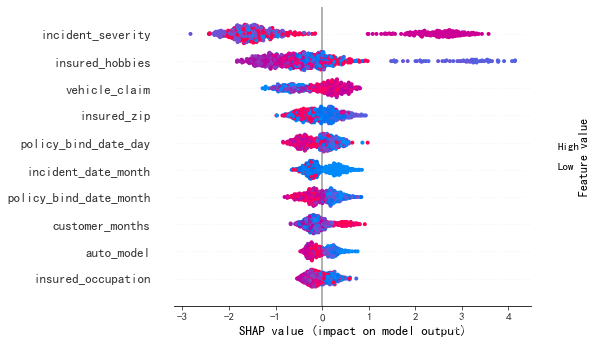
shap值随着事故程度、索赔金额的增加而变大,两者有正向线性关系,说明欺诈案件多数损失不会太小,不然没有冒险价值,还有比如品牌、职业呈现负向关系,是因为编码方式造成,这个可以自定义从高到低编码,就可以呈现出正相关关系。
6.3. 单样本解析
feature_names = list(X_data.columns)
shap.force_plot(explainer.expected_value, shap_values[3,:], X_data.iloc[3,:],feature_names,matplotlib=False) 
shap基准值是-1.274,该样本的shap值为3.39。
这个特征很明显是欺诈特征的shap值高于正常的shap值,最后判定为欺诈。结合原始数据分析:事故程度是3,属于较大损失。索赔金额68862,车型是03年的斯巴鲁力狮,属于老旧车型,3车事故,本车前部受损,有交警证明及财产损失,驾驶员男性,年龄42,联系了当地的火警(有可能是个意外),结合经验推断属于老旧车型,故意碰撞, 车辆全损,新手作案没控制好程度(这点只是推测),导致车辆燃烧。由于部分特征已经脱敏,所以只能从部分特征解读。
6.4. LIME局部可解释模型不可知解释
from lime.lime_tabular import LimeTabularExplainer
class_names = ['0', '1']
explainer = LimeTabularExplainer(x_test.values, feature_names = feature_names,class_names = class_names, mode = 'classification')
explaination = explainer.explain_instance(x_test.iloc[1],clf.predict_proba)
explaination.show_in_notebook(show_table = True, show_all = False)
这个样本从特征判断就属于正常,结合原始数据解析:索赔金额4402,损失程度小,驾驶员男性,年龄29,有交警证明,案件类型是盗抢,车型是萨博9-5,结合经验推断,应该是零部件或者车内物品被盗,这种类型案件欺诈概率较低。
6.5. 单个特征与目标变量之间的关系图
shap.initjs()
explainer = shap.TreeExplainer(clf)
shap.force_plot(explainer.expected_value, shap_values[0:1000], X[0:1000], plot_cmap="DrDb", feature_names=feature_names)
这个图可以看到每个特征与目标函数之间的关系,比如随着事故程度的增加,欺诈样本也在增加,这与第三部分特征可视化的呈现一致。
总结
1. 本次数据集规模较小,也比较干净,所以没做相关清洗。
2. 平均数编码可以尝试的组合太多,有兴趣的朋友可以多多尝试。
3. 本次数据的一些特征分布与国内的保险欺诈情况还是有一定区别,加上近几年的费改,也一定程度上导致作案成本及风险的提高。
4. 保险欺诈类型不仅仅是故意制造,还有很多比如酒驾调包、先险后保、摆放现场、无主肇事等等很多类型,特别涉及人伤欺诈,案件侦破难度更高,同时欺诈案件还有地域差异。
5. 目前国内的环境也在逐步变好,欺诈案件只会越来越少,但反侦察意识也会越来越高,需要反欺诈从业人员与公安部门的共同努力,打击骗保。
6. 希望国家越来越好,人民生活好了,谁还会动骗保的心思呢。
标签:
相关文章
最新发布
- 【Python】selenium安装+Microsoft Edge驱动器下载配置流程
- Python 中自动打开网页并点击[自动化脚本],Selenium
- Anaconda基础使用
- 【Python】成功解决 TypeError: ‘<‘ not supported between instances of ‘str’ and ‘int’
- manim边学边做--三维的点和线
- CPython是最常用的Python解释器之一,也是Python官方实现。它是用C语言编写的,旨在提供一个高效且易于使用的Python解释器。
- Anaconda安装配置Jupyter(2024最新版)
- Python中读取Excel最快的几种方法!
- Python某城市美食商家爬虫数据可视化分析和推荐查询系统毕业设计论文开题报告
- 如何使用 Python 批量检测和转换 JSONL 文件编码为 UTF-8
点击排行
- 版本匹配指南:Numpy版本和Python版本的对应关系
- 版本匹配指南:PyTorch版本、torchvision 版本和Python版本的对应关系
- Python 可视化 web 神器:streamlit、Gradio、dash、nicegui;低代码 Python Web 框架:PyWebIO
- 相关性分析——Pearson相关系数+热力图(附data和Python完整代码)
- Anaconda版本和Python版本对应关系(持续更新...)
- Python与PyTorch的版本对应
- Windows上安装 Python 环境并配置环境变量 (超详细教程)
- Python pyinstaller打包exe最完整教程
本站推荐
