首页 > Python资料 博客日记
【腾讯云 TDSQL-C Serverless 产品体验】 使用 Python 向 TDSQL-C 添加读取数据 实现词云图
2024-07-14 18:00:04Python资料围观82次
文章目录
前言
TDSQL-C MySQL 版(TDSQL-C for MySQL)是腾讯云自研的新一代云原生关系型数据库。融合了传统数据库、云计算与新硬件技术的优势,为用户提供具备高弹性、高性能、海量存储、安全可靠的数据库服务。TDSQL-C MySQL 版100%兼容 MySQL 5.7、8.0。实现超百万级 QPS 的高吞吐,最高 PB 级智能存储,保障数据安全可靠。
TDSQL-C MySQL 版采用存储和计算分离的架构,所有计算节点共享一份数据,提供秒级的配置升降级、秒级的故障恢复,单节点可支持百万级 QPS,自动维护数据和备份,最高以GB/秒的速度并行回档。
TDSQL-C MySQL 版既融合了商业数据库稳定可靠、高性能、可扩展的特征,又具有开源云数据库简单开放、高效迭代的优势。TDSQL-C MySQL 版引擎完全兼容原生 MySQL,您可以在不修改应用程序任何代码和配置的情况下,将 MySQL 数据库迁移至 TDSQL-C MySQL 版引擎。
本篇文章我们将一步一步的实现 使用 Python 向 TDSQL-C 添加读取数据 实现词云图
学到什么?
- 如何申请TDSQL数据库:包括登录腾讯云、选购配置、购买和管理页面等相关步骤。
- 创建项目工程、连接TDSQL数据库、创建数据库等内容。
- 涉及读取词频Excel、创建表、保存数据到TDSQL、读取TDSQL数据等相关代码的讲解。
- python 相关的知识等
准备工作
申请TDSQL数据库
1. 点击登录腾讯云
2. 点击立即选购 ,如下图所示
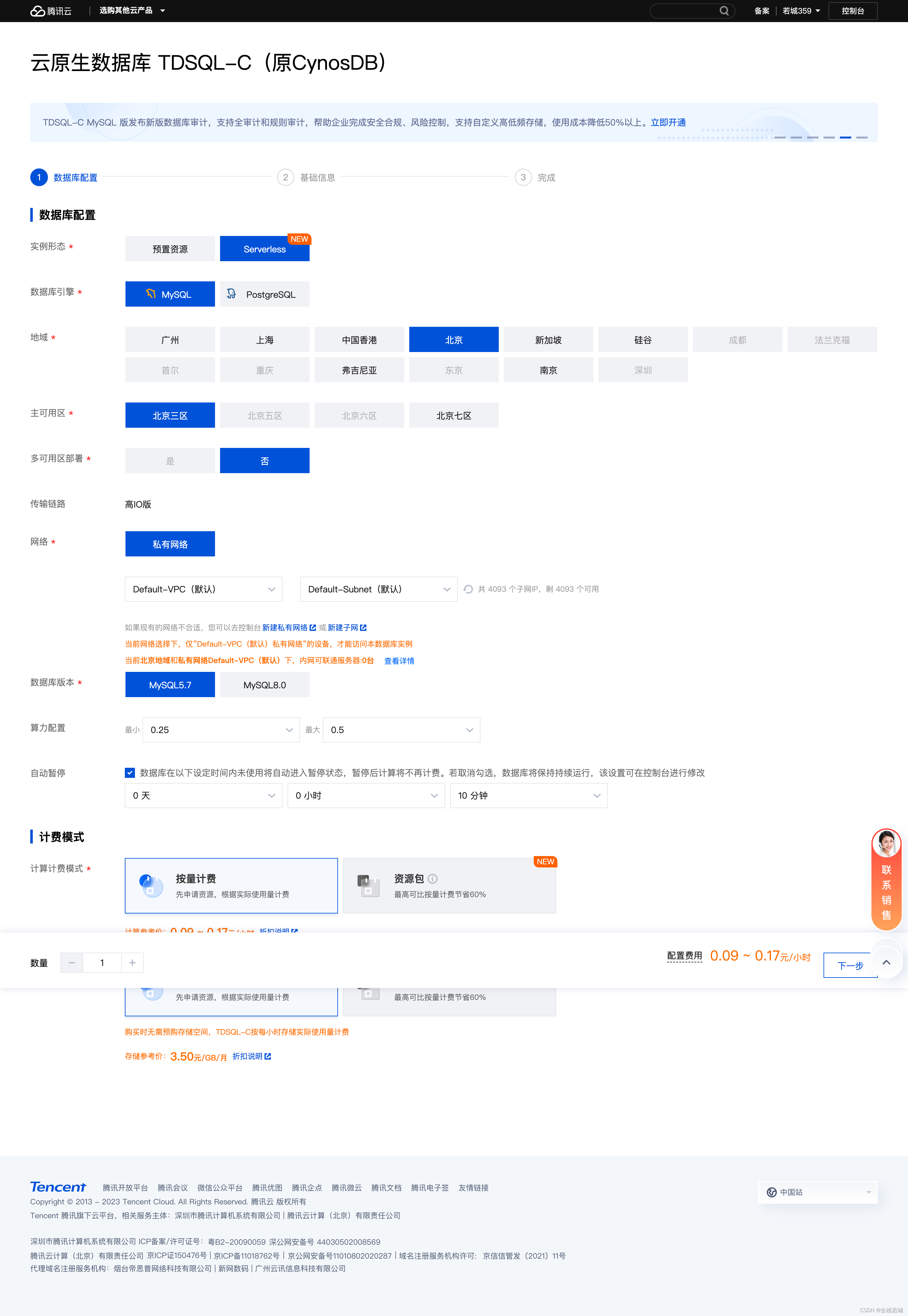
3. 选购页面中的数据库配置选项如下
**注意 **:这里的实例形态我们选择
Serverless
- 实例形态 **(Serverless)**
- 数据库引擎 **(MYSQL)**
- 地域 **(北京)** *地域这里根据自己的实际情况选择即可*
- 主可用区 **(北京三区)** *主可用区这里根据自己的实际情况选择即可*
- 多可用区部署 **(否)**
- 传输链路
- 网络
- 数据库版本 **(MySQL5.7)**
- 算力配置 **最小(0.25) , 最大(0.5)**
- 自动暂停 **根据自己需求配置即可**
- 计算计费模式 **(按量计费)**
- 存储计费模式 **(按量计费)**
我的配置截图如下:
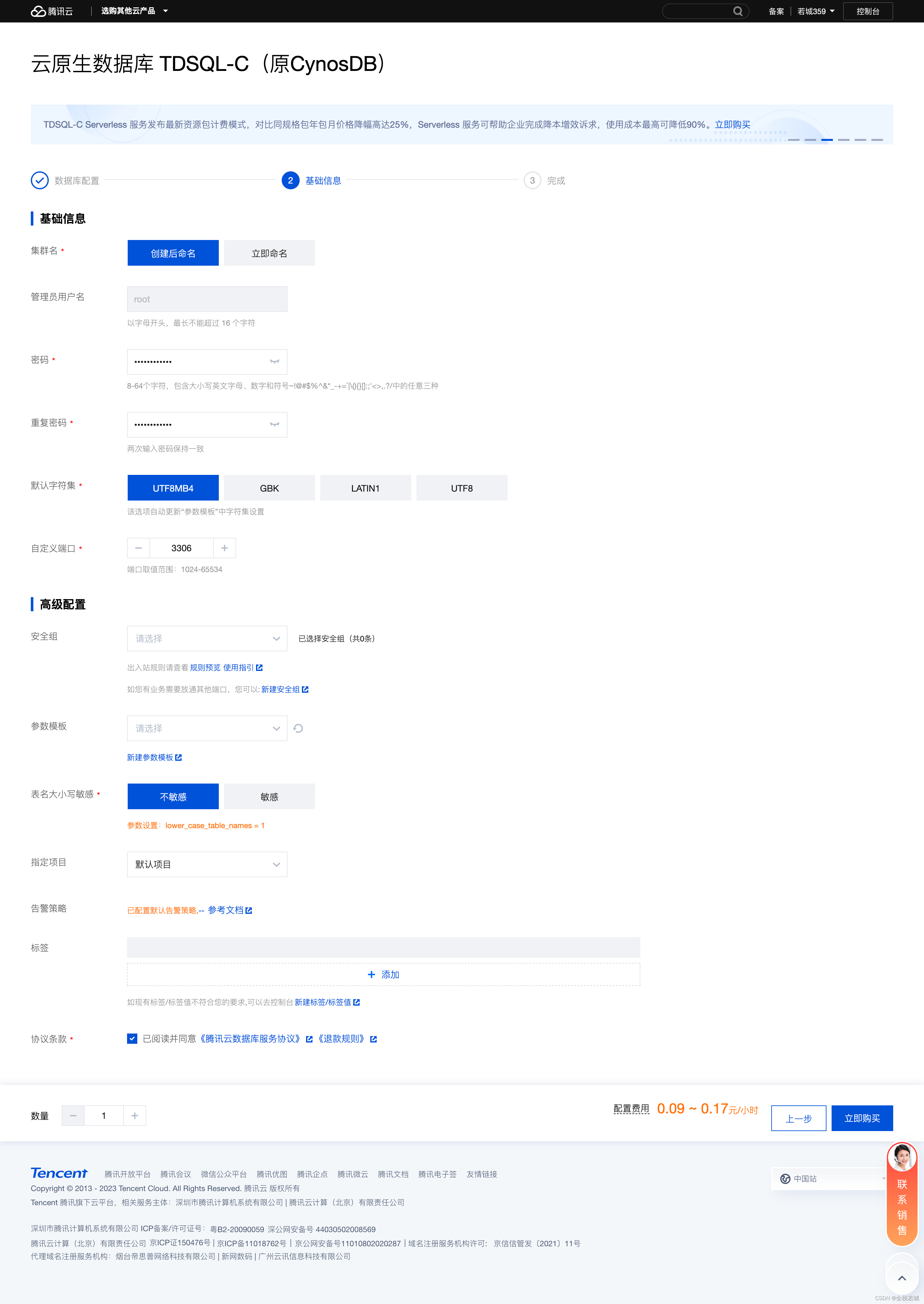
4. 基础信息
配置这里我们直接
设置自己的密码以及表名大小写不敏感即可 , 如下图所示
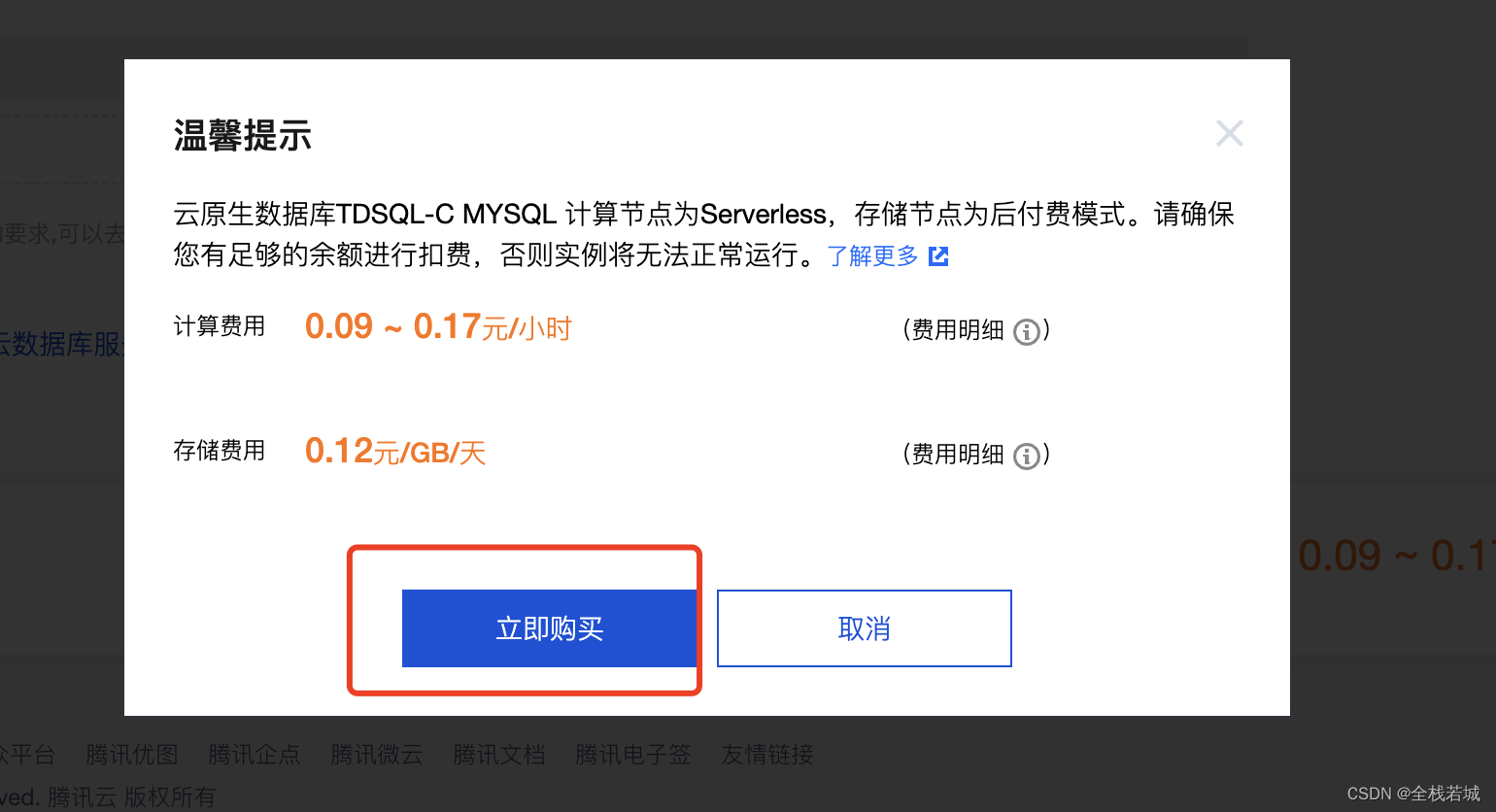
5. 配置完成后点击 右下角的立即购买即可
6. 点击立即购买后会有弹窗如下, 再次点击
7. 购买完成后 , 会出现弹窗 , 点击前往管理页面
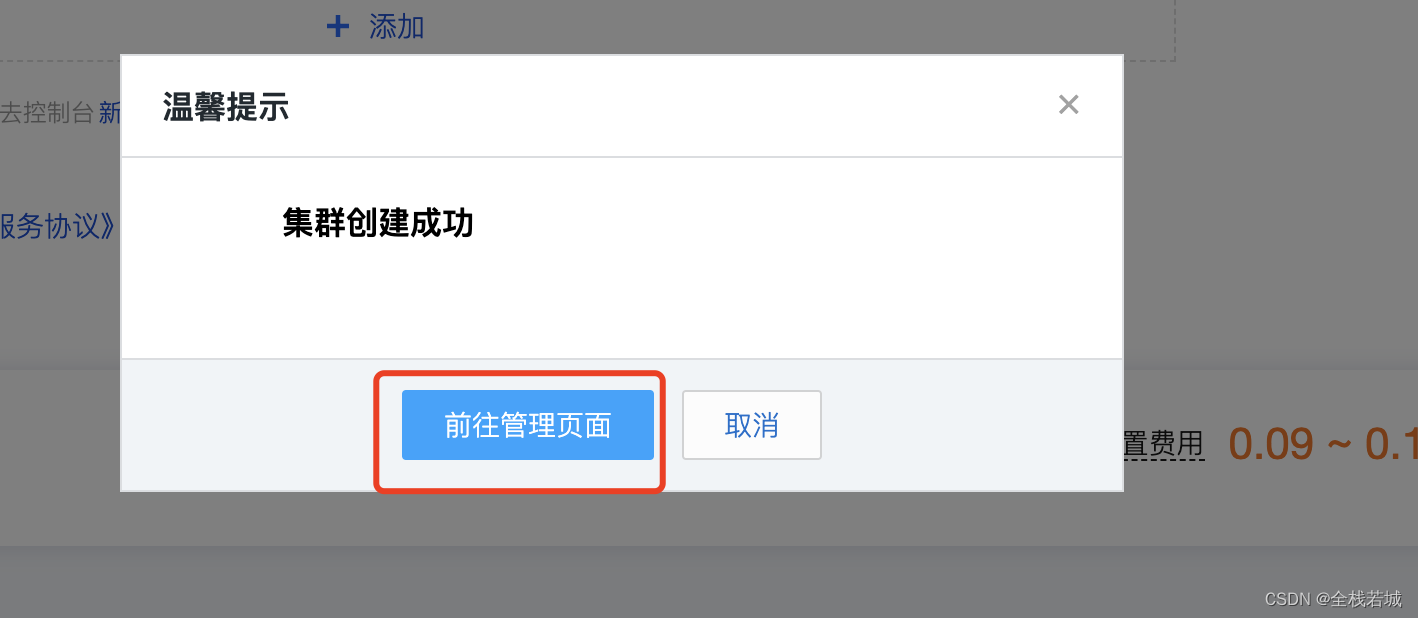
8. 读写实例这里 点击开启外部
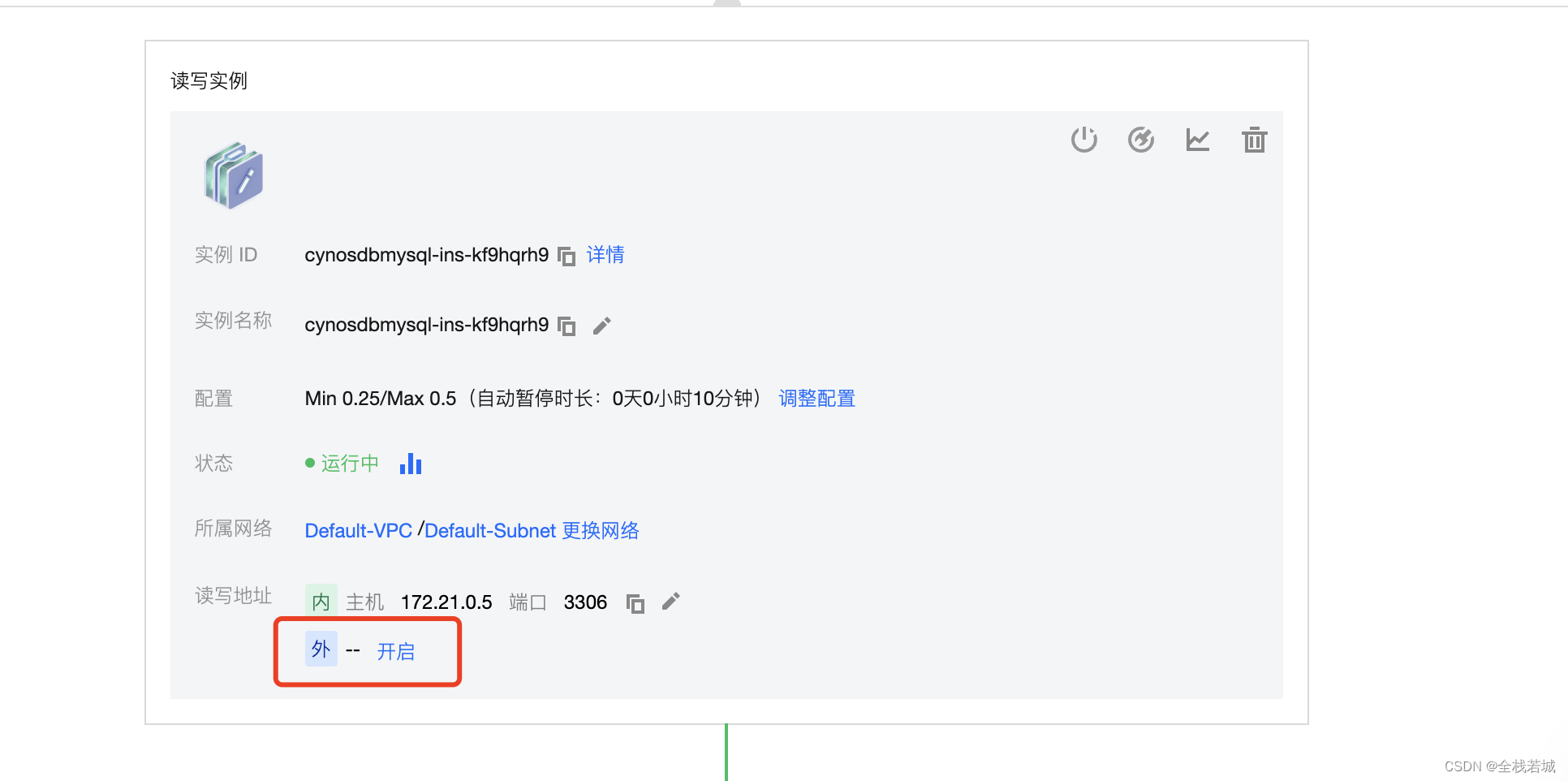
9. 创建并授权即可
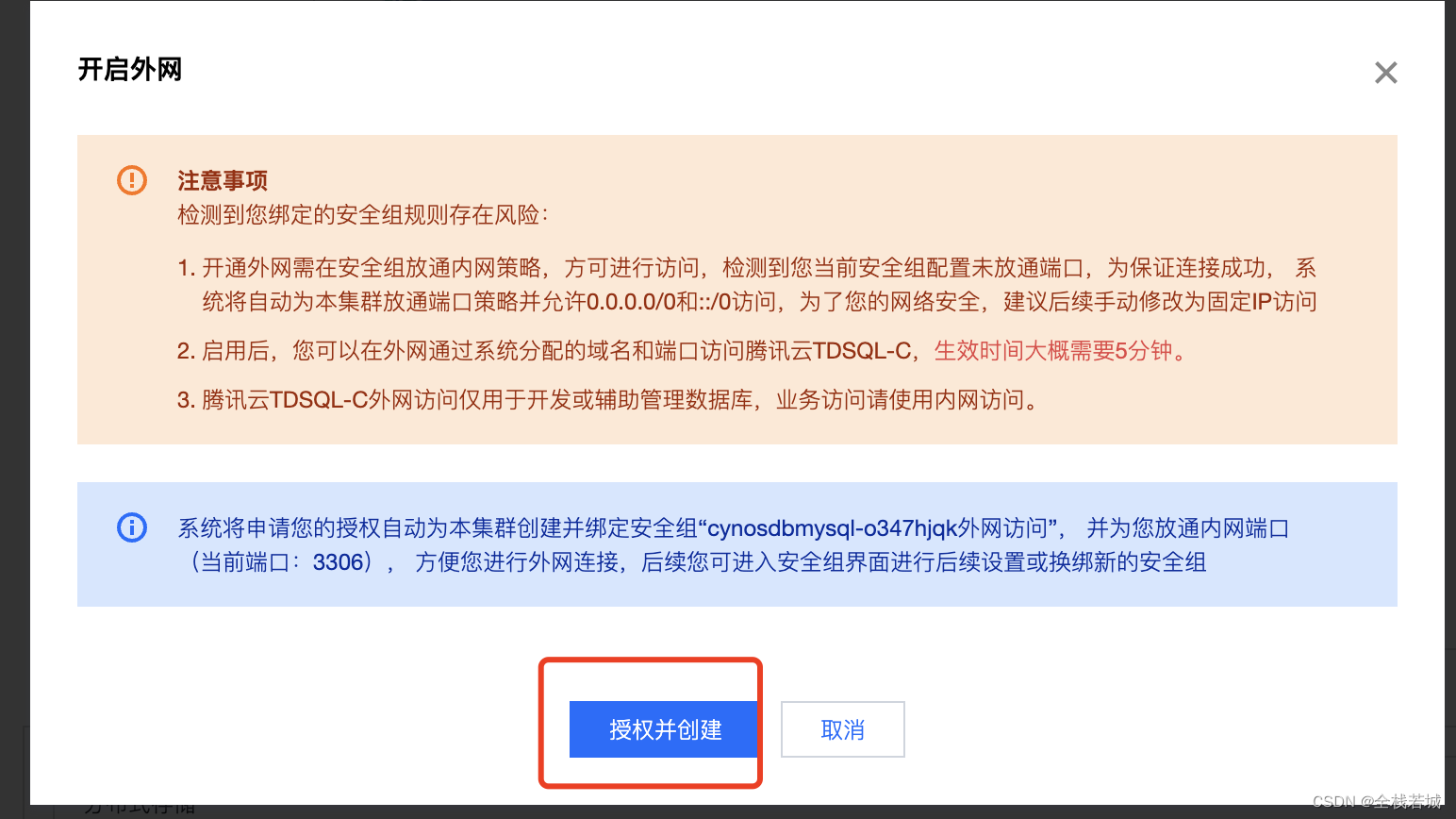
至此我们的准备工作就完成了, 其实还是蛮简单的哦!
数据准备
所需数据 如下
- 词频
- 背景图
- 字体文件
下载地址放在文末有需要的可以去下载哦!
创建项目工程
工程目录如下
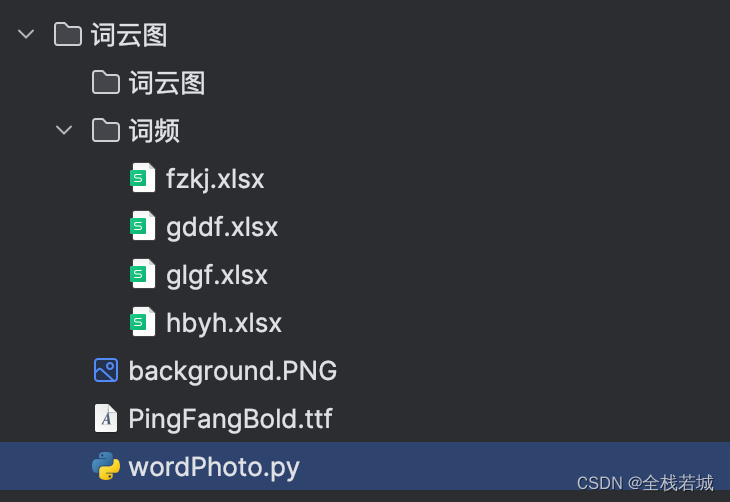
讲解说明:
- 文件中的词云图文件夹 做为生成图片的存储路径
background.png作为词云图背景图- 字体文件则是词云图的字体展示
- 词频是数据支撑
wordPhoto.py为脚本文件
链接 TDSQL
打开数据库读写实例 找到相关配置 如图
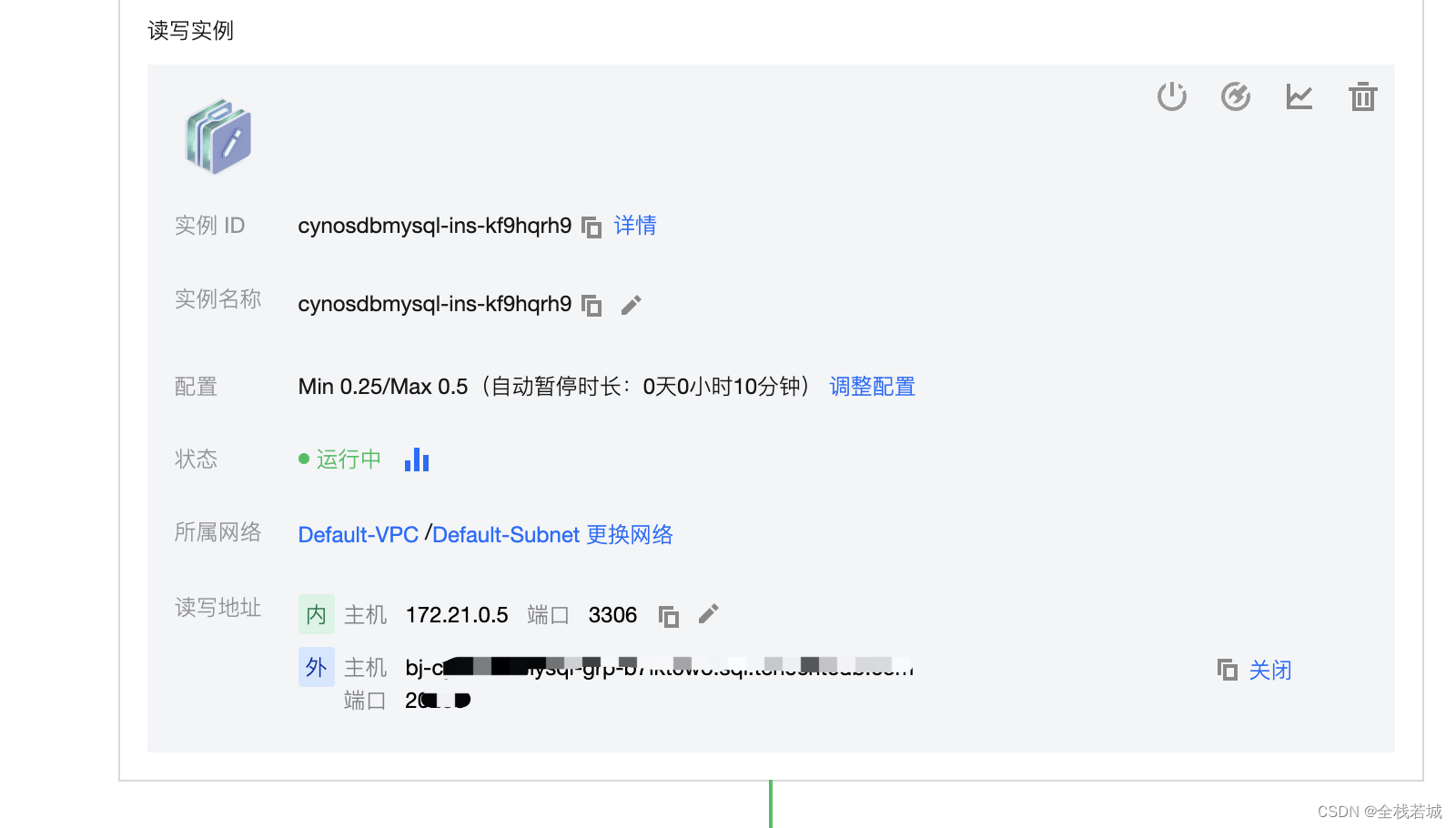
# MySQL数据库连接配置
db_config = {
'host': "XXXXXX", # 这里填写你自己申请的外部主机名
'port': xxxx, # 这里填写你自己申请的外部的端口
'user': "root", # 账户
'password': "", # 密码就是你自己创建实例时的密码
'database': 'tdsql', # 这里需要自己在自己创建的`tdsql`中创建数据库 ,
}
创建数据库
- 如图点击登录按钮 , 登录到我们创建的数据库中
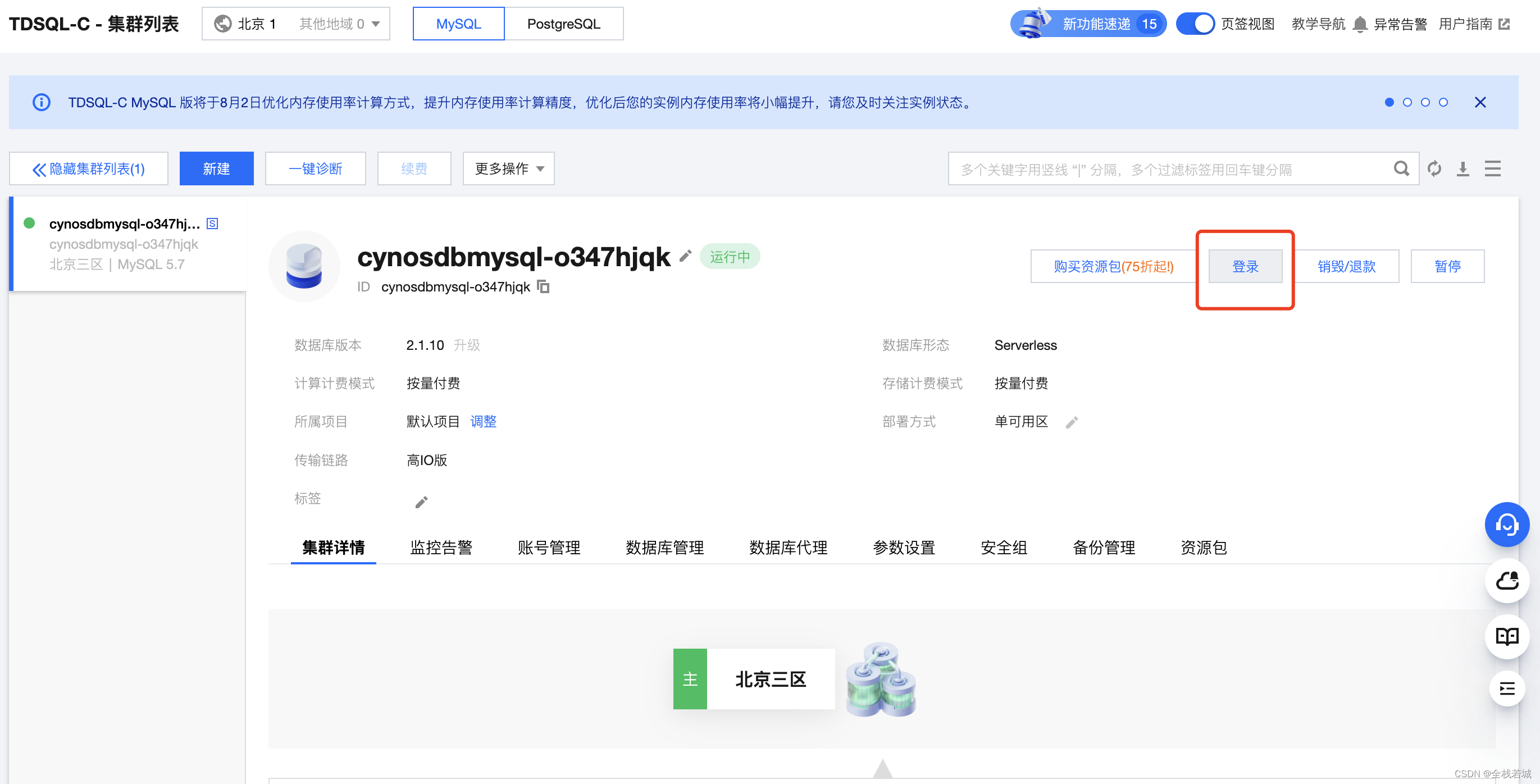
- 进入数据库点击
新建库
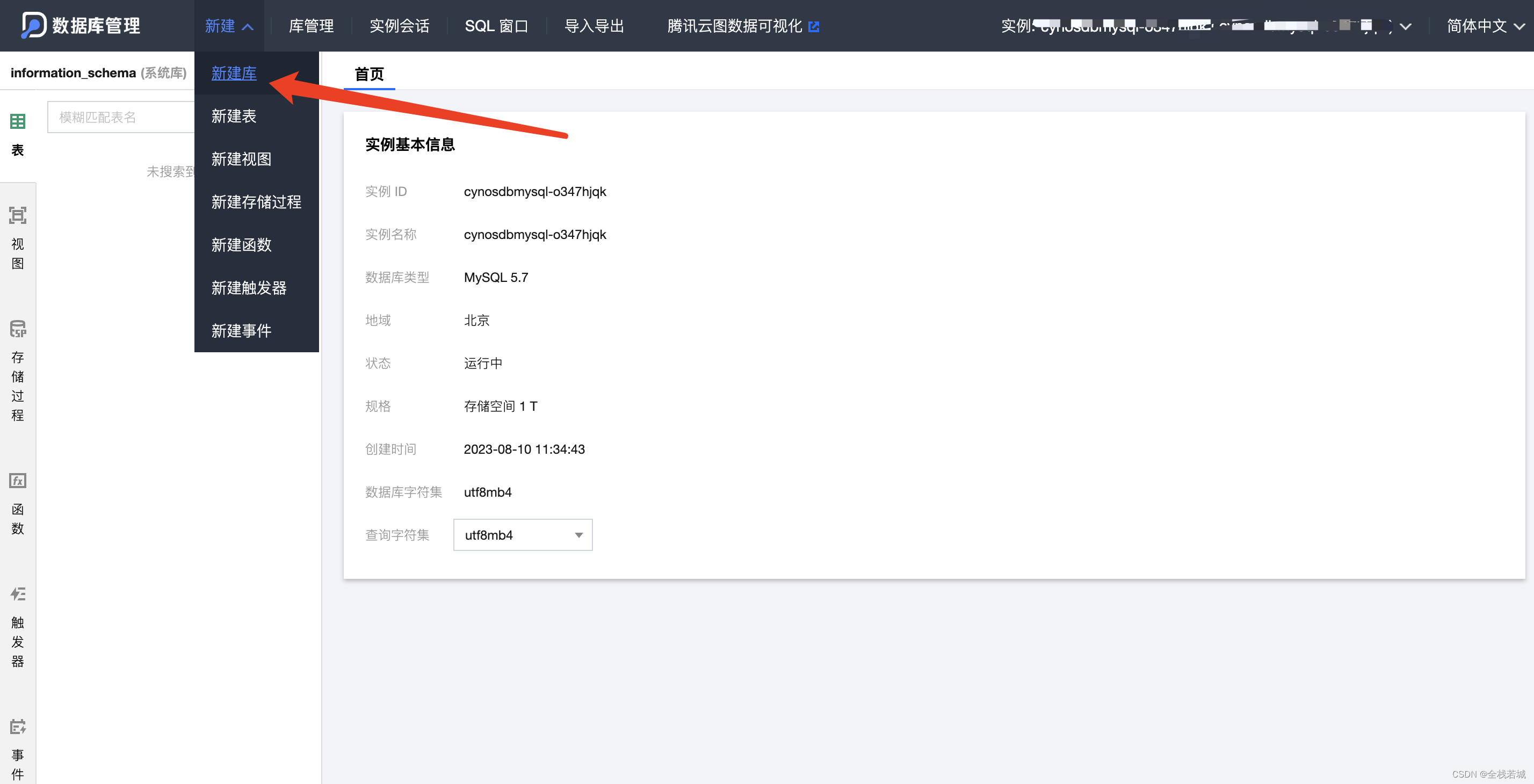
- 点击
新建数据库, 出现弹窗
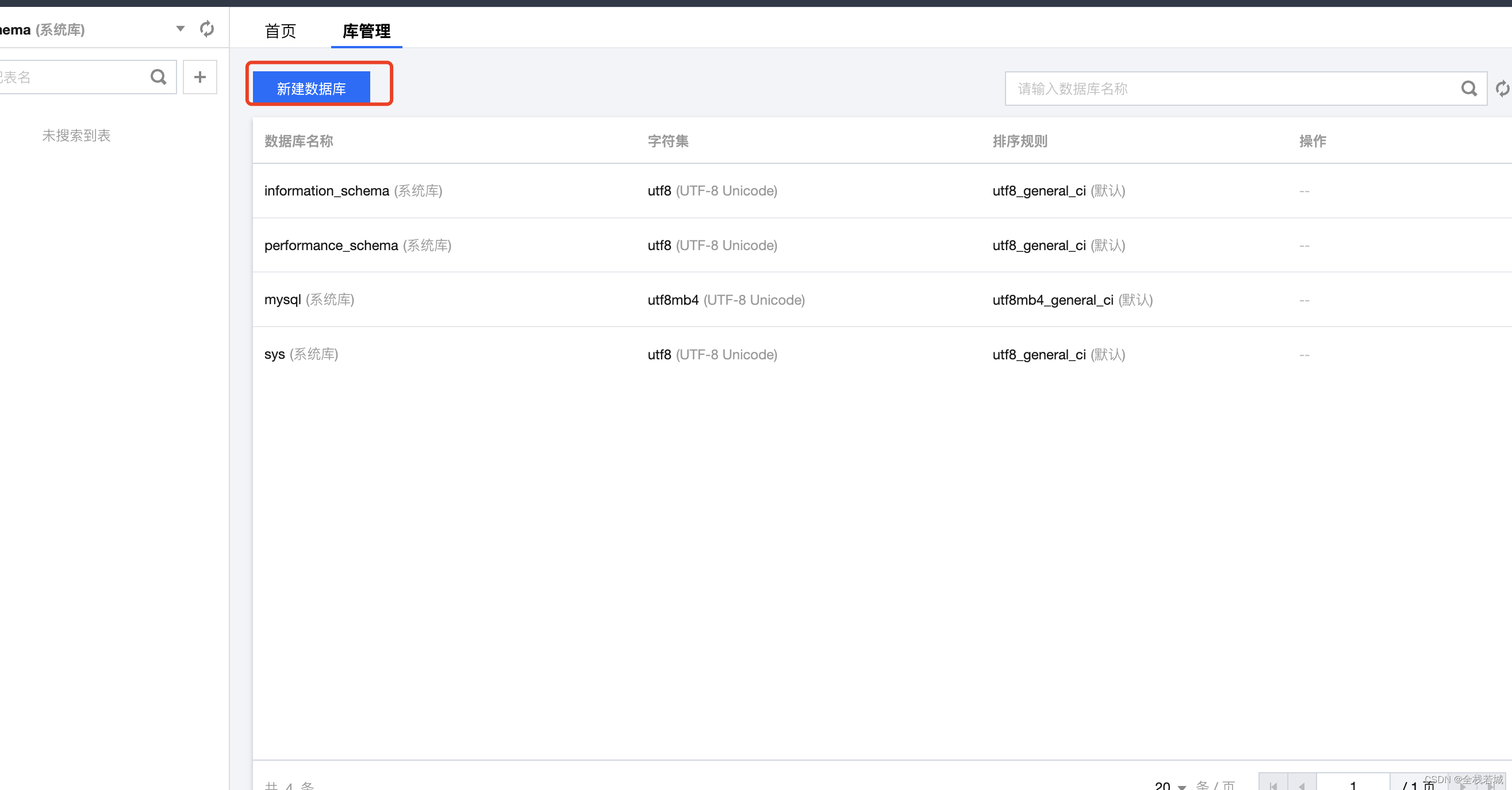
- 在弹窗中的
数据库名称中写入你喜欢的数据库名称即可 ,这里我们用的是tdsql, 作为数据库名称 , 填写好数据库名称后,点击确定创建即可
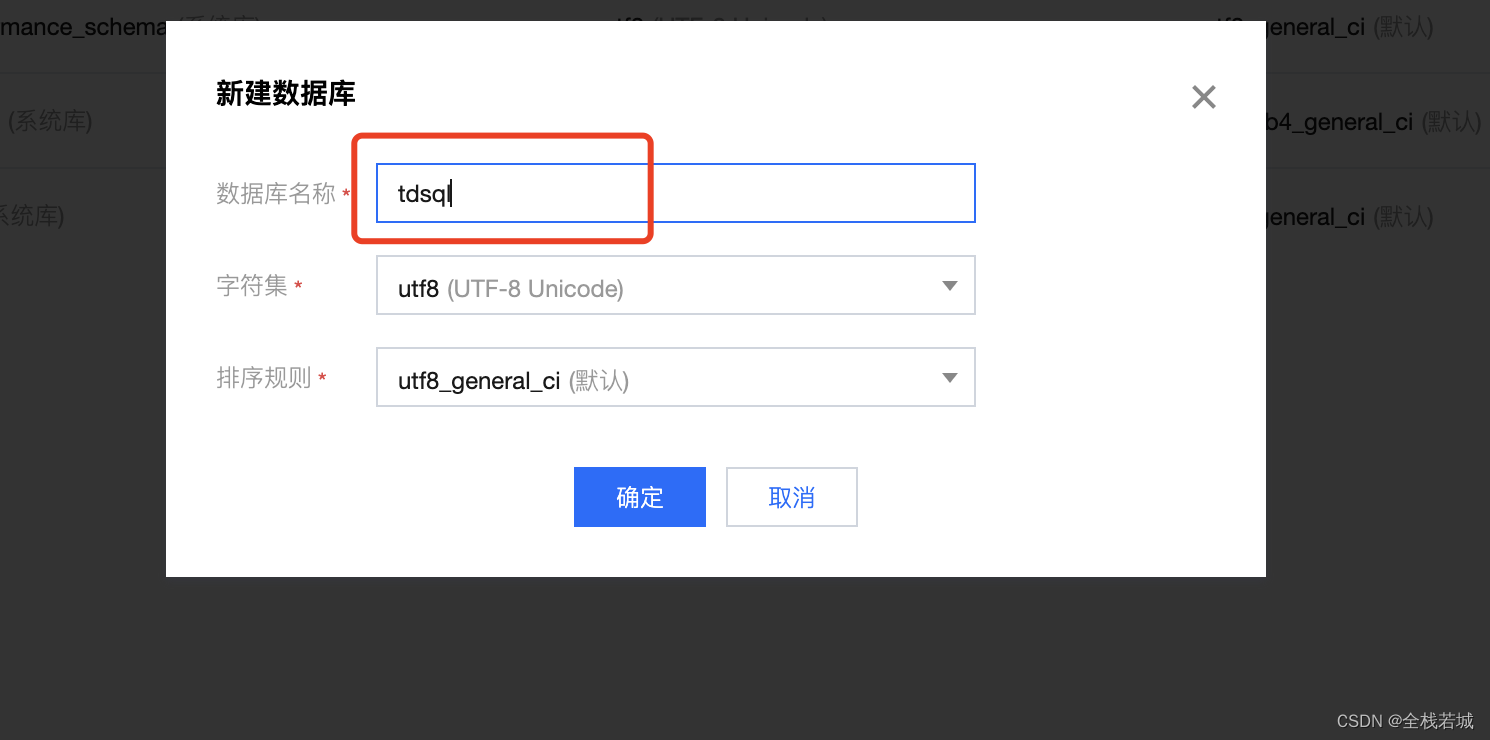
- 列表中出现我们创建的数据库名称后 , 就表示创建好了 , 我们就可以开始代码编写了哦!
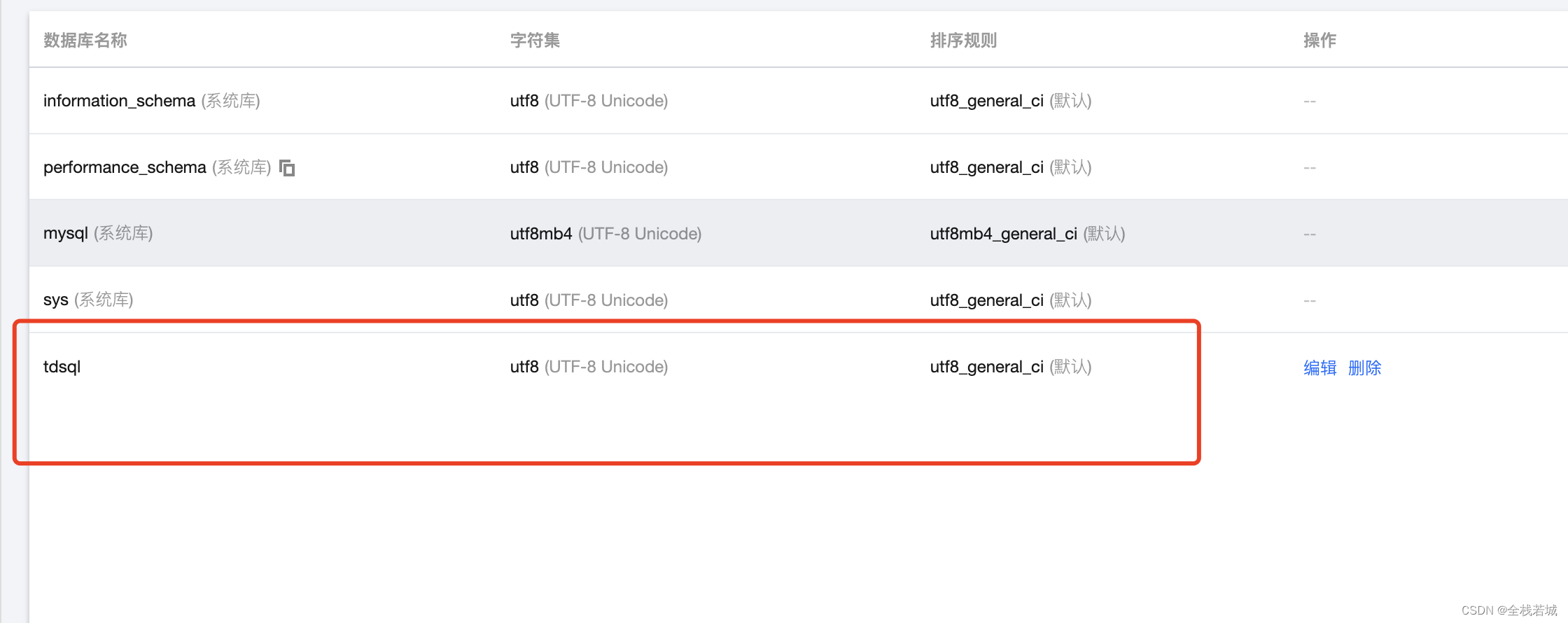
函数模块
读取词频excel
def excelTomysql():
path = '词频' # 文件所在文件夹
files = [path + "/" + i for i in os.listdir(path)] # 获取文件夹下的文件名,并拼接完整路径
for file_path in files:
print(file_path)
filename = os.path.basename(file_path)
table_name = os.path.splitext(filename)[0] # 使用文件名作为表名,去除文件扩展名
# 使用pandas库读取Excel文件
data = pd.read_excel(file_path, engine="openpyxl", header=0) # 假设第一行是列名
columns = {col: "VARCHAR(255)" for col in data.columns} # 动态生成列名和数据类型
create_table(table_name, columns) # 创建表
save_to_mysql(data, table_name) # 将数据保存到MySQL数据库中,并使用文件名作为表名
print(filename + ' uploaded and saved to MySQL successfully')
代码讲解
- 设置文件夹路径为’词频’,将该路径赋值给变量
path。 - 使用
os.listdir()函数获取文件夹下的所有文件名,并拼接完整路径,存储到列表files中。 - 使用
for循环遍历files列表中的每个文件路径,并打印出文件路径。 - 使用
os.path.basename()函数获取文件名,并将文件名赋值给变量filename。 - 使用
os.path.splitext()函数获取文件名的扩展名,并通过索引操作去除扩展名部分,得到表名,并将表名赋值给变量table_name。 - 使用
pandas库的read_excel()函数读取 Excel 文件,并将数据存储到变量data中。在读取过程中,使用openpyxl引擎,并假设第一行是列名。 - 使用字典推导式生成一个字典
columns,其中字典的键为数据的列名,值为 “VARCHAR(255)” 数据类型。 - 调用
create_table()函数,以table_name和columns作为参数,创建一个对应的表。 - 调用
save_to_mysql()函数,以data和table_name作为参数,将数据保存到 MySQL 数据库中,并使用文件名作为表名。 - 打印出文件名加上 ’ uploaded and saved to MySQL successfully’ 的提示信息。
创建表
def create_table(table_name, columns):
# 建立MySQL数据库连接
conn = pymysql.connect(**db_config)
cursor = conn.cursor()
# 组装创建表的 SQL 查询语句
query = f"CREATE TABLE IF NOT EXISTS {table_name} ("
for col_name, col_type in columns.items():
query += f"{col_name} {col_type}, "
query = query.rstrip(", ") # 去除最后一个逗号和空格
query += ")"
# 执行创建表的操作
cursor.execute(query)
# 提交事务并关闭连接
conn.commit()
cursor.close()
conn.close()
代码讲解
- 建立与MySQL数据库的连接,连接参数通过变量
db_config提供。 - 创建一个光标对象
cursor,用于执行SQL语句。 - 组装创建表的SQL查询语句。首先,在SQL查询语句中插入表名
table_name。然后,通过for循环遍历columns字典中的每个键值对,分别将列名和数据类型添加到SQL查询语句中。 - 去除SQL查询语句末尾的最后一个逗号和空格。
- 添加右括号,完成SQL查询语句的组装。
- 使用光标对象
cursor执行创建表的操作,执行的SQL语句为组装好的查询语句。 - 提交事务,将对数据库的修改持久化。
- 关闭光标和数据库连接。
代码中使用了 pymysql 模块来建立MySQL数据库连接,并通过编写SQL语句来执行创建表的操作。具体的数据库连接参数在 db_config 变量中提供,而 columns 参数则是由之前的代码生成的一个字典,包含了表的列名和数据类型。
保存数据到tdsql
def save_to_mysql(data, table_name):
# 建立MySQL数据库连接
conn = pymysql.connect(**db_config)
cursor = conn.cursor()
# 将数据写入MySQL表中(假设数据只有一个Sheet)
for index, row in data.iterrows():
query = f"INSERT INTO {table_name} ("
for col_name in data.columns:
query += f"{col_name}, "
query = query.rstrip(", ") # 去除最后一个逗号和空格
query += ") VALUES ("
values = tuple(row)
query += ("%s, " * len(values)).rstrip(", ") # 动态生成值的占位符
query += ")"
cursor.execute(query, values)
# 提交事务并关闭连接
conn.commit()
cursor.close()
conn.close()
代码讲解
- 建立与MySQL数据库的连接,连接参数通过变量
db_config提供。 - 创建一个光标对象
cursor,用于执行SQL语句。 - 对于数据中的每一行,使用
for循环迭代,获取索引和行数据。 - 组装插入数据的SQL查询语句。首先,在SQL查询语句中插入表名
table_name。然后,通过for循环遍历数据的列名,将列名添加到SQL查询语句中。 - 去除SQL查询语句末尾的最后一个逗号和空格。
- 添加右括号,完成SQL查询语句的组装。
- 使用
tuple(row)将行数据转换为元组类型,并将值占位符%s动态生成相应数量的占位符。 - 将值的占位符添加到SQL查询语句中。
- 使用光标对象
cursor.execute()执行SQL查询语句,将查询语句中的占位符替换为实际的行数据。 - 提交事务,将对数据库的修改持久化。
- 关闭光标和数据库连接。
读取tdsql 数据
def query_data():
# 建立MySQL数据库连接
conn = pymysql.connect(**db_config)
cursor = conn.cursor()
# 查询所有表名
cursor.execute("SHOW TABLES")
tables = cursor.fetchall()
data = []
dic_list = []
table_name_list = []
for table in tables:
# for table in [tables[-1]]:
table_name = table[0]
table_name_list.append(table_name)
query = f"SELECT * FROM {table_name}"
# # 执行查询并获取结果
cursor.execute(query)
result = cursor.fetchall()
if len(result) > 0:
columns = [desc[0] for desc in cursor.description]
table_data = [{columns[i]: row[i] for i in range(len(columns))} for row in result]
data.extend(table_data)
dic = {}
for i in data:
dic[i['word']] = float(i['count'])
dic_list.append(dic)
conn.commit()
cursor.close()
conn.close()
return dic_list, table_name_list
代码讲解
- 建立与MySQL数据库的连接,连接参数通过变量
db_config提供。 - 创建一个光标对象
cursor,用于执行SQL语句。 - 使用
cursor.execute()执行SQL查询语句"SHOW TABLES",获取所有表名。 - 使用
cursor.fetchall()获取查询结果,将结果存储在变量tables中。 - 创建空列表
data、dic_list和table_name_list,用于存储查询结果的数据、字典和表名。 - 对于每个表名
table,通过for循环迭代,获取表名并添加到table_name_list中。 - 构建查询该表所有数据的SQL语句,并使用
cursor.execute()执行该查询语句。 - 使用
cursor.fetchall()获取查询结果,将结果存储在变量result中。 - 如果查询结果
result的长度大于0,则说明有数据,进行以下操作:- 使用
cursor.description获取查询结果的列名列表,并将列名存储在变量columns中。 - 使用列表推导式和字典推导式,将查询结果的每一行转换为字典,并将字典存储在变量
table_data中。 - 将
table_data添加到data列表中。
- 使用
- 根据
data中的结果构建字典,并将字典存储在变量dic中。 - 将
dic添加到dic_list列表中。 - 提交事务,将对数据库的修改持久化。
- 关闭光标和数据库连接。
- 返回
dic_list和table_name_list。
代码调用
if __name__ == '__main__':
excelTomysql()
result_list, table_name_list = query_data()
for i in range(len(result_list)):
maskImage = np.array(Image.open('background.PNG')) # 定义词频背景图
# 定义词云样式
wc = wordcloud.WordCloud(
font_path='PingFangBold.ttf', # 设置字体
mask=maskImage, # 设置背景图
max_words=800, # 最多显示词数
max_font_size=200) # 字号最大值
# 生成词云图
wc.generate_from_frequencies(result_list[i]) # 从字典生成词云
# 保存图片到指定文件夹
wc.to_file("词云图/{}.png".format(table_name_list[i]))
print("生成的词云图【{}】已经保存成功!".format(table_name_list[i] + '.png'))
plt.imshow(wc) # 显示词云
plt.axis('off') # 关闭坐标轴
plt.show() # 显示图像
代码讲解
- 使用
Image.open()打开名为 ‘background.PNG’ 的背景图,并将其转换为NumPy数组,存储在变量maskImage中,作为词云的背景图。 - 创建一个
WordCloud对象wc,设置字体路径、背景图、最多显示词数和字号最大值等参数。 - 使用
wc.generate_from_frequencies()从result_list[i]的字典数据生成词云图。 - 使用
wc.to_file()将生成的词云图保存为文件,文件名为 “词云图/{}.png”,其中{}表示对应的表名。 - 打印输出生成的词云图文件名。
- 使用
plt.imshow()显示词云图。 - 使用
plt.axis('off')关闭坐标轴的显示。 - 使用
plt.show()显示图像。
完整代码
import pymysql
import pandas as pd
import os
import wordcloud
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
# MySQL数据库连接配置
db_config = {
'host': "XXXXXX", # 这里填写你自己申请的外部主机名
'port': xxxx, # 这里填写你自己申请的外部的端口
'user': "root", # 账户
'password': "", # 密码就是你自己创建实例时的密码
'database': 'tdsql', # 这里需要自己在自己创建的`tdsql`中创建数据库 ,
}
def create_table(table_name, columns):
# 建立MySQL数据库连接
conn = pymysql.connect(**db_config)
cursor = conn.cursor()
# 组装创建表的 SQL 查询语句
query = f"CREATE TABLE IF NOT EXISTS {table_name} ("
for col_name, col_type in columns.items():
query += f"{col_name} {col_type}, "
query = query.rstrip(", ") # 去除最后一个逗号和空格
query += ")"
# 执行创建表的操作
cursor.execute(query)
# 提交事务并关闭连接
conn.commit()
cursor.close()
conn.close()
def excelTomysql():
path = '词频' # 文件所在文件夹
files = [path + "/" + i for i in os.listdir(path)] # 获取文件夹下的文件名,并拼接完整路径
for file_path in files:
print(file_path)
filename = os.path.basename(file_path)
table_name = os.path.splitext(filename)[0] # 使用文件名作为表名,去除文件扩展名
# 使用pandas库读取Excel文件
data = pd.read_excel(file_path, engine="openpyxl", header=0) # 假设第一行是列名
columns = {col: "VARCHAR(255)" for col in data.columns} # 动态生成列名和数据类型
create_table(table_name, columns) # 创建表
save_to_mysql(data, table_name) # 将数据保存到MySQL数据库中,并使用文件名作为表名
print(filename + ' uploaded and saved to MySQL successfully')
def save_to_mysql(data, table_name):
# 建立MySQL数据库连接
conn = pymysql.connect(**db_config)
cursor = conn.cursor()
# 将数据写入MySQL表中(假设数据只有一个Sheet)
for index, row in data.iterrows():
query = f"INSERT INTO {table_name} ("
for col_name in data.columns:
query += f"{col_name}, "
query = query.rstrip(", ") # 去除最后一个逗号和空格
query += ") VALUES ("
values = tuple(row)
query += ("%s, " * len(values)).rstrip(", ") # 动态生成值的占位符
query += ")"
cursor.execute(query, values)
# 提交事务并关闭连接
conn.commit()
cursor.close()
conn.close()
def query_data():
# 建立MySQL数据库连接
conn = pymysql.connect(**db_config)
cursor = conn.cursor()
# 查询所有表名
cursor.execute("SHOW TABLES")
tables = cursor.fetchall()
data = []
dic_list = []
table_name_list = []
for table in tables:
# for table in [tables[-1]]:
table_name = table[0]
table_name_list.append(table_name)
query = f"SELECT * FROM {table_name}"
# # 执行查询并获取结果
cursor.execute(query)
result = cursor.fetchall()
if len(result) > 0:
columns = [desc[0] for desc in cursor.description]
table_data = [{columns[i]: row[i] for i in range(len(columns))} for row in result]
data.extend(table_data)
dic = {}
for i in data:
dic[i['word']] = float(i['count'])
dic_list.append(dic)
conn.commit()
cursor.close()
conn.close()
return dic_list, table_name_list
if __name__ == '__main__':
excelTomysql()
result_list, table_name_list = query_data()
for i in range(len(result_list)):
maskImage = np.array(Image.open('background.PNG')) # 定义词频背景图
# 定义词云样式
wc = wordcloud.WordCloud(
font_path='PingFangBold.ttf', # 设置字体
mask=maskImage, # 设置背景图
max_words=800, # 最多显示词数
max_font_size=200) # 字号最大值
# 生成词云图
wc.generate_from_frequencies(result_list[i]) # 从字典生成词云
# 保存图片到指定文件夹
wc.to_file("词云图/{}.png".format(table_name_list[i]))
print("生成的词云图【{}】已经保存成功!".format(table_name_list[i] + '.png'))
plt.imshow(wc) # 显示词云
plt.axis('off') # 关闭坐标轴
plt.show() # 显示图像
注意
运行代码前 引入相关的包哦!
pip install pymysql
pip install pandas
pip install wordcloud
pip install numpy
pip install pillow
pip install matplotlib
运行代码
写入截图
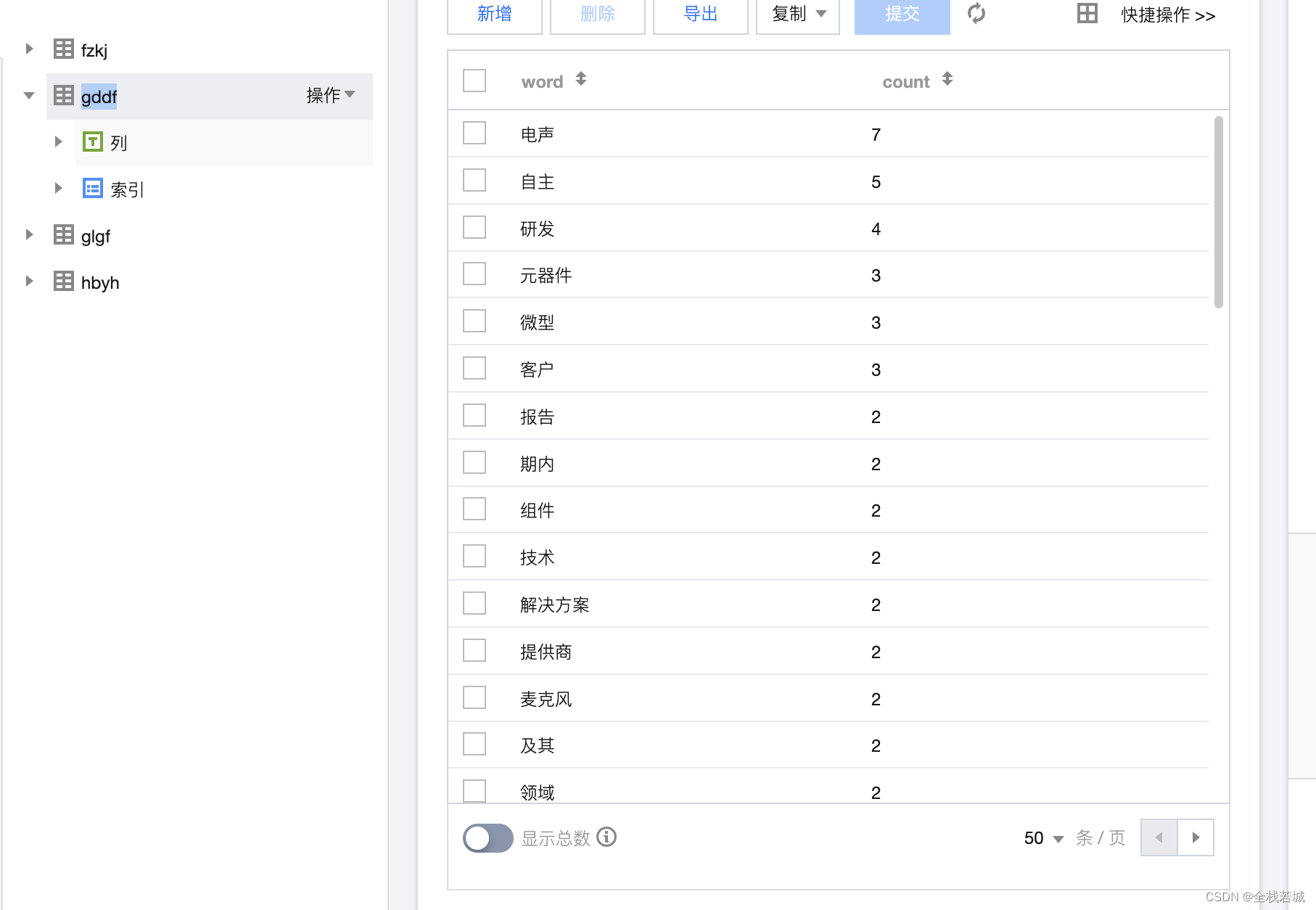
数据库数据截图
生成词云图

将词云图存入到文件夹

删除TDSQL
体验完成, 考虑到当前这个业务没必要继续开启数据库了, 防止无效计费, 所以删除一下
如图点击销毁按钮

出现销毁实例的弹窗, 点击确定即可

资源下载
资源在百度盘里 自取哦 !
链接: https://pan.baidu.com/s/1hClOJI07HUuGBQ2SwZfWjw 提取码: 5mm9
–来自百度网盘超级会员v7的分享
总结
使用
TDSQL时你会发现, 真的是无缝接入, 非常的丝滑, 当然也有些不足,希望可以改进哦!!
优点
- 腾讯云数据库 TDSQL整体使用和感受还是很好的,操作比较简单,通过简单的官方文档就是搭建成功,其次性价比很高,尤其对于初学者新手 ,
- 与传统的数据库相比,TD-SQL Serverless的计费方式更为灵活,按照实际使用的资源进行付费,避免了长期运行服务器的成本。同时,它也可以在空闲时自动休眠,减少不必要的费用。
缺点
- 由于TD-SQL Serverless会在请求到达时才进行资源的分配和启动,因此在首次请求时可能会有一定的延迟。对于一些对实时性要求较高的应用场景,延迟可能会影响用户体验。
- 相比于传统的数据库,TD-SQL Serverless提供的配置和优化选项较少,用户对底层资源的控制能力有限。这可能会导致一些特定的需求无法满足。
- 虽然TD-SQL Serverless可以根据需求自动扩展计算资源,但高并发流量可能会导致较高的成本。如果在短时间内存在大量的并发请求,可能需要支付额外费用。
注意 这个三个缺点我只是根据经验进行猜想, 如有错误还请及时指正哦!!
标签:
相关文章
最新发布
- 【Python】selenium安装+Microsoft Edge驱动器下载配置流程
- Python 中自动打开网页并点击[自动化脚本],Selenium
- Anaconda基础使用
- 【Python】成功解决 TypeError: ‘<‘ not supported between instances of ‘str’ and ‘int’
- manim边学边做--三维的点和线
- CPython是最常用的Python解释器之一,也是Python官方实现。它是用C语言编写的,旨在提供一个高效且易于使用的Python解释器。
- Anaconda安装配置Jupyter(2024最新版)
- Python中读取Excel最快的几种方法!
- Python某城市美食商家爬虫数据可视化分析和推荐查询系统毕业设计论文开题报告
- 如何使用 Python 批量检测和转换 JSONL 文件编码为 UTF-8
点击排行
- 版本匹配指南:Numpy版本和Python版本的对应关系
- 版本匹配指南:PyTorch版本、torchvision 版本和Python版本的对应关系
- Python 可视化 web 神器:streamlit、Gradio、dash、nicegui;低代码 Python Web 框架:PyWebIO
- 相关性分析——Pearson相关系数+热力图(附data和Python完整代码)
- Anaconda版本和Python版本对应关系(持续更新...)
- Python与PyTorch的版本对应
- Windows上安装 Python 环境并配置环境变量 (超详细教程)
- Python pyinstaller打包exe最完整教程
本站推荐
