首页 > Python资料 博客日记
【python爬虫案例】利用python爬取豆瓣音乐评分TOP250的排行数据!
2024-10-14 16:30:03Python资料围观36次
一、爬取案例-豆瓣音乐TOP250
之前给大家分享了2个豆瓣的python爬虫案例:
【python爬虫案例】利用python爬虫爬取豆瓣电影评分TOP250排行数据!
【python爬虫案例】利用python爬虫爬取豆瓣读书评分TOP250的排行数据!
今天再给大家分享一下:豆瓣音乐排行榜TOP250的python爬虫案例!
爬虫的流程和逻辑上都和之前分享过的2篇文章差不多
这次爬取的目标网址是:https://music.douban.com/top250
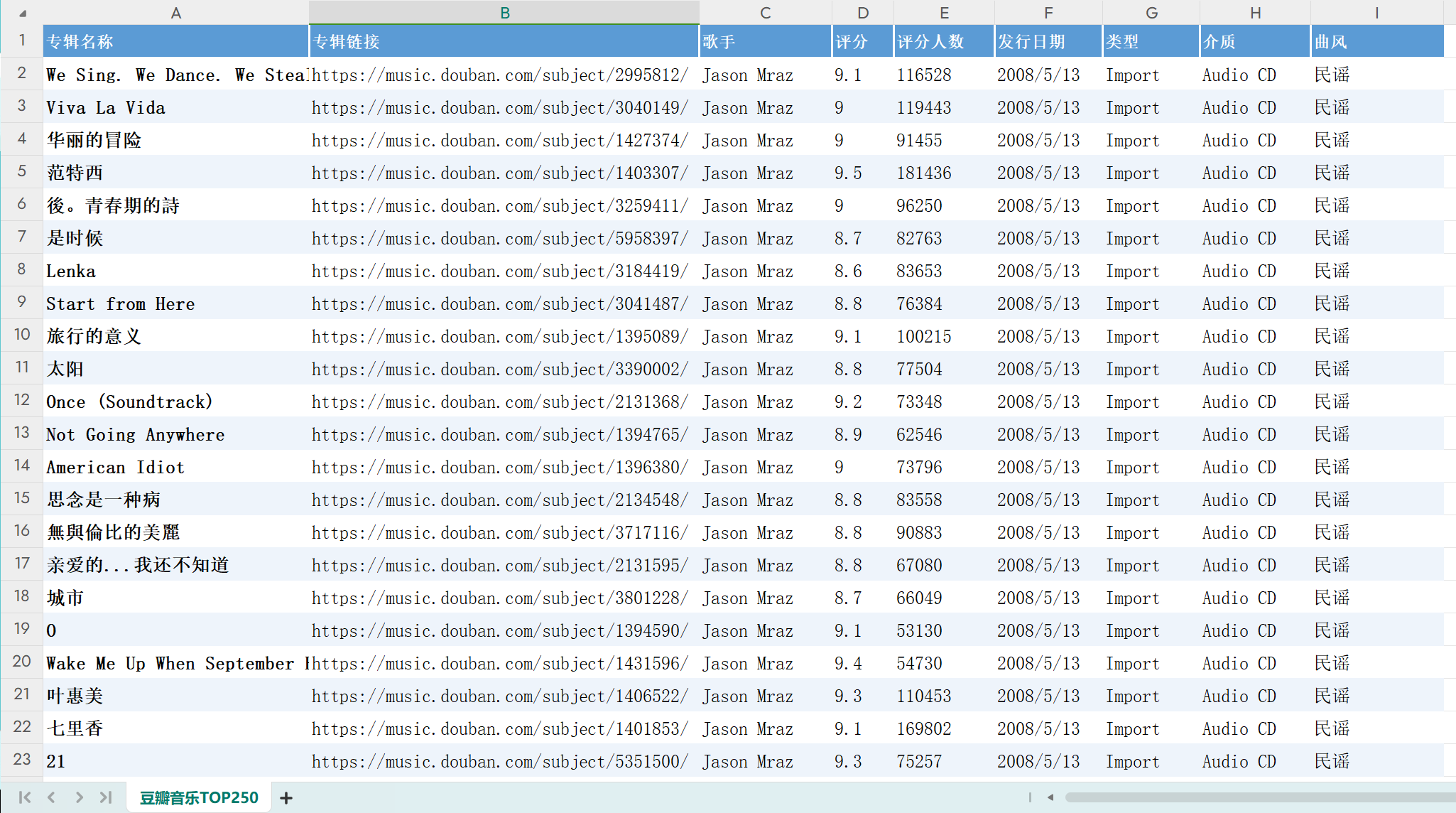
老规矩!咱们以目标为驱动,先来看下爬虫爬取成功后得到的csv文档数据
那代码是如何实现豆瓣音乐TOP250数据爬取的了?下面逐一讲解一下python实现。
二、豆瓣音乐TOP250网站分析
通过浏览器F12查看所有请求,发现他并没有发送ajax请求,那说明我们要的TOP250的排行榜数据大概率是在html页面内容上。
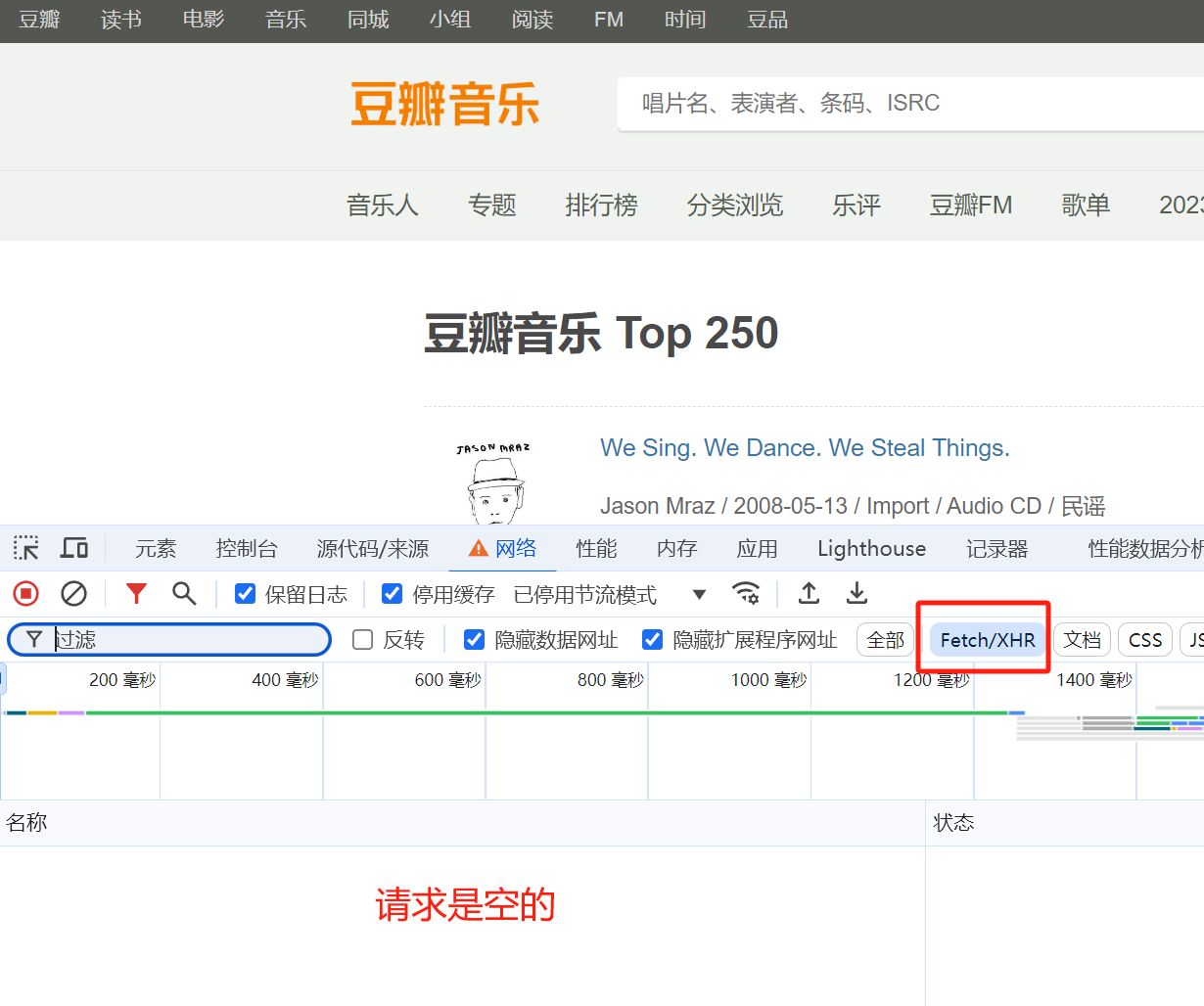
于是我们 点击右键->查看网页源代码 ,发现我们需要的豆瓣音乐评分的排行榜数据都在html页面里
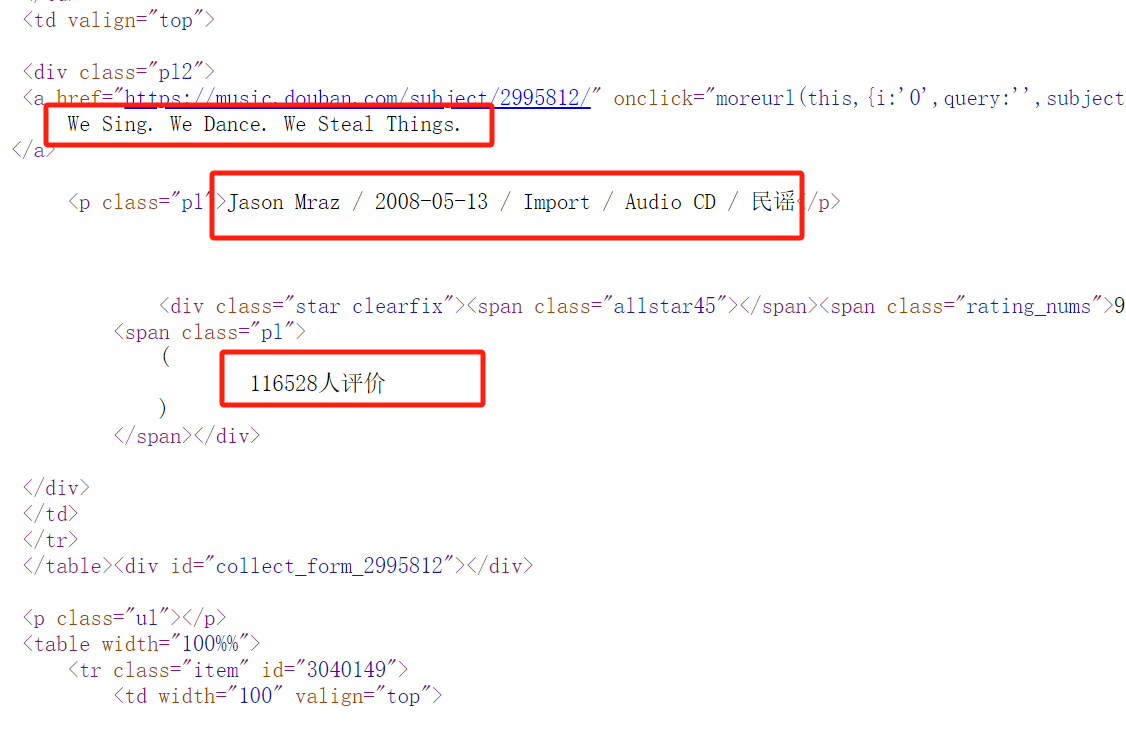
这就简单了,我们直接往下看,上代码。
三、python爬虫代码详解
首先,导入我们需要用到的库
import requests # 发请求
from lxml import etree # 解析html
import pandas as pd # 存取csv然后,向豆瓣音乐TOP250的网页发起请求,获得html页面内容
page_source = requests.get(page_url, headers=headers).text用lxml库解析html页面
tree = etree.HTML(page_source)使用xpath来提取我们需要的音乐排行榜数据内容
# 获得数据所在的标签
tables = tree.xpath("//div[@class='indent']/table")
# 循环标签获得音乐信息
for table in tables:
pl2 = table.xpath(".//div[@class='pl2']")[0]
# 抓取数据
url = extract_first(pl2.xpath("./a/@href")) # 专辑链接
music_name = extract_first(pl2.xpath("./a/text()")) # 专辑名称
score = extract_first(pl2.xpath(".//span[@class='rating_nums']/text()")) # 评分
score_people_num = extract_first(pl2.xpath(".//span[@class='pl']/text()"))
score_people_num = re.search("\d+", score_people_num).group() # 评分人数
info_text = extract_first(pl2.xpath("//p[@class='pl']/text()"))
infos = info_text.split("/")
singer = infos[0].strip() # 歌手
publish_date = infos[1].strip() # 发行日期
type = infos[2].strip() # 类型
media = infos[3].strip() # 介质
style = infos[4].strip() # 曲风最后,我们将爬虫爬取的数据保存到csv文档里
def save_to_csv(csv_name):
"""
数据保存到csv
@param csv_name: csv文件名字
@return:
"""
df = pd.DataFrame() # 初始化一个DataFrame对象
df['专辑名称'] = music_names
df['专辑链接'] = urls
df['歌手'] = singers
df['评分'] = scores
df['评分人数'] = score_people_nums
df['发行日期'] = publish_dates
df['类型'] = types
df['介质'] = medias
df['曲风'] = styles
df.to_csv(csv_name, encoding='utf8', index=False) # 将数据保存到csv文件上面的music_names、urls等变量都是使用的list来进行存储的,这样才能符合pandas导出数据时的需要,然后调用to_csv()方法保存即可。
这样,爬取的豆瓣音乐排行榜数据就持久化保存到我们的文档里了。
需要注意的是!豆瓣页面上第4、5、6页只有24首(不是25首)音乐,所以总数量是247,不是250。
不是爬虫代码有问题,是豆瓣页面上就只有247条数据。
四、python爬虫源代码获取
我是@王哪跑,持续分享python干货,各类副业技巧及软件!
附完整python源码及csv表格数据:【python爬虫案例】利用python爬取豆瓣音乐评分TOP250的排行数据!
标签:
相关文章
最新发布
- 【Python】selenium安装+Microsoft Edge驱动器下载配置流程
- Python 中自动打开网页并点击[自动化脚本],Selenium
- Anaconda基础使用
- 【Python】成功解决 TypeError: ‘<‘ not supported between instances of ‘str’ and ‘int’
- manim边学边做--三维的点和线
- CPython是最常用的Python解释器之一,也是Python官方实现。它是用C语言编写的,旨在提供一个高效且易于使用的Python解释器。
- Anaconda安装配置Jupyter(2024最新版)
- Python中读取Excel最快的几种方法!
- Python某城市美食商家爬虫数据可视化分析和推荐查询系统毕业设计论文开题报告
- 如何使用 Python 批量检测和转换 JSONL 文件编码为 UTF-8
点击排行
- 版本匹配指南:Numpy版本和Python版本的对应关系
- 版本匹配指南:PyTorch版本、torchvision 版本和Python版本的对应关系
- Python 可视化 web 神器:streamlit、Gradio、dash、nicegui;低代码 Python Web 框架:PyWebIO
- 相关性分析——Pearson相关系数+热力图(附data和Python完整代码)
- Python与PyTorch的版本对应
- Anaconda版本和Python版本对应关系(持续更新...)
- Python pyinstaller打包exe最完整教程
- Could not build wheels for llama-cpp-python, which is required to install pyproject.toml-based proj
本站推荐
