首页 > Python资料 博客日记
在Java中使用XxlCrawler时防止被反爬的几种方式
2024-05-10 04:00:04Python资料围观725次
目录
前言
众所周知,在抓取别人的信息,会面临一些常见的屏蔽原则。当然,我们不建议持续不间断的获取信息,也同样呼吁正确利用获取的数据,仅做学习之用。相信大家在使用爬虫技术的同时,一定会遇到以下的场景,比如目标地址会进行IP限制,即将爬取的客户端IP限制掉。这里的限制可能是临时的,比如1天甚至半天就解封,而有一些是永久封禁。则该IP无法再次获取信息。而正常情况下我们又还需要持续的获取信息,这种情况下应该怎么去获取我们想要的数据呢。
本文以Java开发语言为例,主要讲解在采用XxlCrawler组件进行网络信息获取时,几种常见的反爬策略的应对方式。博文首先介绍了了几种常见的防止爬取技术,然后以XxlCrawer为例,针对这几种策略,在XxlCrawler中是如何进行实现,并进行应对的。
温馨提示:反爬虫技术是网站保护安全和稳定的重要手段,但也给数据采集带来了一定的挑战。在应对反爬虫技术时,需要遵循原则,选择合适的应对方法,提高技术水平和应对能力。同时,也需要注意法律法规和道德规范,遵循网站的规则和协议,保护网站的知识产权和合法权益。
一、常见的反爬措施
通常,在数据提供方为了保证数据的唯一性。随着互联网和移动互联网的发展,无论是信息爬取还是防止信息爬取,各方面的技术都在随着时间的推移而进步。本小节将介绍几种常见的反爬措施。关于反爬措施,更多的知识和策略可以到专业网站上学习。这里仅列出几种常见的。
1、User-Agent识别
User-Agent是HTTP请求头中的一个字段,用于标识客户端的类型和版本信息。很多网站通过User-Agent识别来判断访问请求是否来自于爬虫。用户代理(User Agent,简称 UA),是一个特殊字符串头,使得服务器能够识别客户使用的操作系统及版本、CPU 类型、浏览器及版本、浏览器渲染引擎、浏览器语言、浏览器插件等。这个特殊字段包含了很丰富的信息,当然,也是可以通过这个agent来初步判断当前的请求是否是来源于爬虫。如果是爬虫,则可以进行限流。
在正常的网络请求,可以看到每个网络请求中肯定会携带一些User-Agent的信息。在Chrome浏览器中,可以使用检查选项,打开网络监视器。
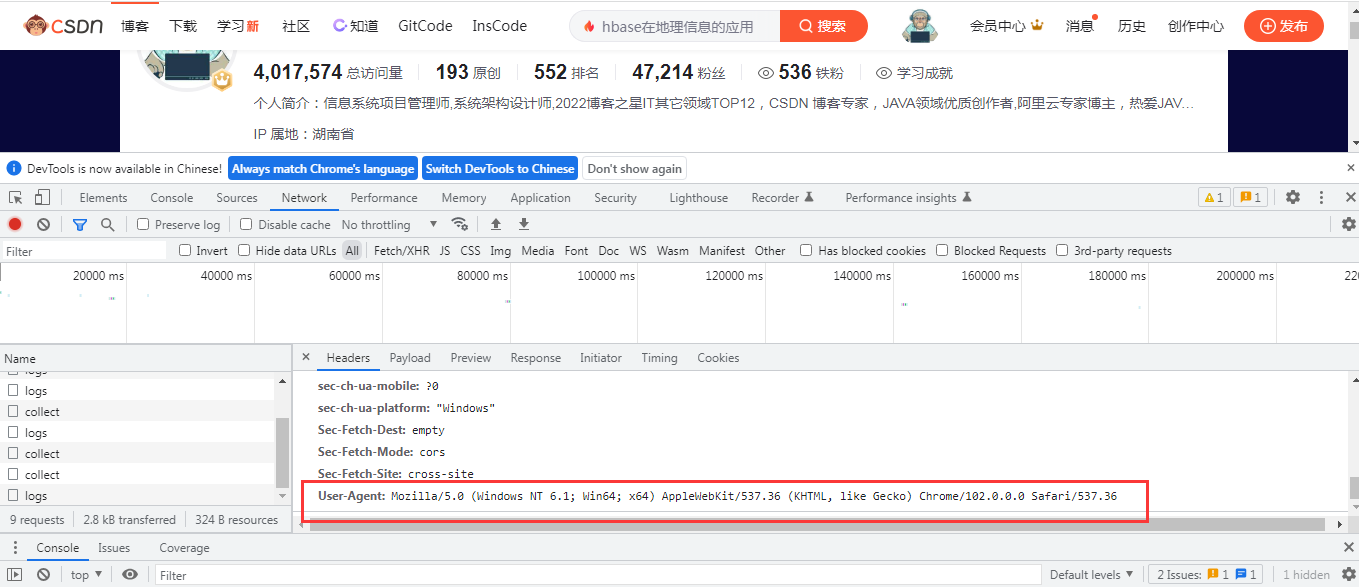
可以在Request的heads中可以看到上面的信息:
Accept: application/x-clarity-gzip
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9
Connection: keep-alive
Content-Length: 178
Cookie: MUID=2F05612551EE6C861BC173C555EE6A59
Host: d.clarity.ms
Origin: https://blog.csdn.net
Referer: https://blog.csdn.net/yelangkingwuzuhu
sec-ch-ua: " Not A;Brand";v="99", "Chromium";v="102", "Google Chrome";v="102"
sec-ch-ua-mobile: ?0
sec-ch-ua-platform: "Windows"
Sec-Fetch-Dest: empty
Sec-Fetch-Mode: cors
Sec-Fetch-Site: cross-site
User-Agent: Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.362、Referer识别
Referer识别其实和上面的User-Agent的机制差不多,也是在Request Heads中加入了识别信息。通过这个关键信息来判断当前请求是否属于爬虫,其携带载体和方式与上面的方式没有什么区别,在此不再赘述。
3、频率限制
频率限制是指限制访问请求的频率,防止爬虫过度访问网站。频率限制的实现方式包括IP限制、账号限制、访问时间限制等。根据应用开放的权限不一致,有一些信息需要登录目标系统后才能正常获取,有一些是公共的API,比如之前的博客中提到过的中国地震台网的信息。这些是不用登录就能访问的。而这种公共接口,一般就会有IP和时间的限制,假如一个IP访问接口太频繁,就极有可能会触发这个频率限制的策略。
4、IP限制
很多网站会有自己的安全流量网关,一般在流量网关中,会将请求进行过滤。通过配置的一些策略对请求进行初步的拦截,比如基于频率的IP访问限制,如果不小心被服务端锁定,那么极有可能会被推送至黑名单,而自此之后恐怕都不能再正常爬取信息。
关于网站的反爬机制,决不止以上列出的这几种。而如果您也在从事相关网站的功能模块开发。那么一定要注意相关的安全设计。因为爬虫这种异常的流量,会对系统造成极大的流量冲击,假如系统的流量阈值没有进行压测。那么极有可能会压垮系统。这样就会导致系统的可用性降低,影响了用户体验和系统的可靠性。
二、XxlCrawer的应对之道
在这里在此强调,写这篇博客并非鼓励大家使用爬虫技术。反而是呼吁大家正确的使用这个技术,不要频繁访问目标系统,也不要将获取的数据用于不发目的。本小节根据上面的几种常见的反爬策略,以Java开发语言为例,讲解在XxlCrawler中使用什么策略来应对上面的几种方式。建议大家在爬取信息前,先去目标网站看一下爬虫协议。
robots协议也称爬虫协议、爬虫规则等,是指网站可建立一个robots.txt文件来告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取,而搜索引擎则通过读取robots.txt文件来识别这个页面是否允许被抓取。但是,这个robots协议不是防火墙,也没有强制执行力,搜索引擎完全可以忽视robots.txt文件去抓取网页的快照。 [5]如果想单独定义搜索引擎的漫游器访问子目录时的行为,那么可以将自定的设置合并到根目录下的robots.txt,或者使用robots元数据(Metadata,又称元数据)。
举个例子,我们来看一下知乎的协议,在知乎的访问域名后加上robots.txt即可看到。知乎爬虫协议,在浏览器中输入访问地址可以看到以下信息:

User-agent: Googlebot
Disallow: /appview/
Disallow: /login
Disallow: /logout
Disallow: /resetpassword
Disallow: /terms
Disallow: /search
Allow: /search-special
Disallow: /notifications
Disallow: /settings
Disallow: /inbox
Disallow: /admin_inbox
Disallow: /*?guide*上面就详细的规定了爬虫对象,禁止爬取的地址以及允许爬取的地址。感兴趣的朋友可以详细看看。
1、User-Agent应对
User-Agent是HTTP请求头中的一个字段,用于标识客户端的类型和版本信息。User-Agent的格式通常为“产品名称/产品版本号+操作系统名称/操作系统版本号”,例如“Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36”。网站通过检查User-Agent字段来判断访问请求是否来自于爬虫,如果User-Agent中包含爬虫相关的关键词,或者User-Agent与常见的浏览器不一致,就会被认为是爬虫。因此,User-Agent伪装是常见的反爬虫技术。
在了解了User-Agent的原理之后,我们就可以采用针对性的修复措施来进行User-Agent的修改。在XxlCrawler中采用动态设置的方式来进行修改。
XxlCrawler crawler = new XxlCrawler.Builder().setUrls(urlList).setThreadCount(3)
.setUserAgent(
"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36")Referer的应对方式跟上面的例子差不多。我们可以在请求的时候来模拟正常的请求即可。
2、频率限制
一般网站接口的访问频率可能不一定公开公布,需要在实践中来进行总结。通常来说,应对频率限制的办法可以有以下办法:1、降低抓取频率:降低抓取频率,减少对网站的访问压力。2、使用多个账号:使用多个账号进行抓取,避免单个账号被限制。
降低抓取频率是比较好处理的一种方式,实现的方式也有很多种,比如使用多线程的时候,每次抓取完数据之后,都可以将时间频率进行降低,这样保证跟人的频率几乎没什么区别。可以采用线程休眠的方式,如Thread.sleep()。而在XxlCrawler当中,也是采用时间停止的方法。关键代码如下所示:
XxlCrawler crawler = new XxlCrawler.Builder().setUrls(urlList).setThreadCount(3).setPauseMillis(2000)主要是通过setPauseMillis方法类设置暂停的时间,从而达到降低采样频率的作用。通常为了避免网络等错误,我们将请求做一个重试,比如请求出错后,再 重试3次,结合重试来保证可用性。
/**
* 失败重试次数,大于零时生效
*
* @param failRetryCount
* @return Builder
*/
public Builder setFailRetryCount(int failRetryCount){
if (failRetryCount > 0) {
crawler.runConf.setFailRetryCount(failRetryCount);
}
return this;
}3、IP限制
这是应对爬虫最有效也最容易误杀的方案。IP限制是最基本的反爬虫技术之一,通过检查访问请求的IP地址,判断是否是爬虫,如果是,则禁止其访问。IP限制的实现方式包括黑名单和白名单,黑名单是指禁止特定的IP地址访问,白名单是指只允许特定的IP地址访问。
通常来讲,为了达到避免IP被限制的情况出现,我们一般会采用如下的解决方案。1、使用代理IP:使用代理IP可以绕过IP限制,但需要注意代理IP的质量和稳定性,否则会影响抓取效果。2、分布式抓取:使用多个IP地址进行分布式抓取,避免单个IP被限制。3、更换IP地址:在被限制之后,更换IP地址重新进行抓取。
代理IP
简单的说,就是通过ip代理,从不同的ip进行访问,这样就不会被封掉ip了。可是ip代理的获取本身就是一个很麻烦的事情,网上有免费和付费的,但是质量都层次不齐。如果是企业里需要的话,可以通过自己购买集群云服务来自建代理池。如果是业务需要,建议购买付费的代理,这样代理的可靠性比免费的好太多。
设置代理处理器,关键代码如下(这里只是举个例子,下面的代理地址应该都失效了):
ProxyMaker proxyMaker = new RoundProxyMaker()
.addProxy(new Proxy(Proxy.Type.HTTP, new InetSocketAddress("39.101.65.228", 80)));
proxyMaker.addProxy(new Proxy(Proxy.Type.HTTP, new InetSocketAddress("183.164.242.102", 8089)));
proxyMaker.addProxy(new Proxy(Proxy.Type.HTTP, new InetSocketAddress("222.74.73.202", 42055)));
proxyMaker.addProxy(new Proxy(Proxy.Type.HTTP, new InetSocketAddress("114.106.135.53", 8089)));
proxyMaker.addProxy(new Proxy(Proxy.Type.HTTP, new InetSocketAddress("117.74.65.207", 80)));
proxyMaker.addProxy(new Proxy(Proxy.Type.HTTP, new InetSocketAddress("183.164.243.240", 8089)));
proxyMaker.addProxy(new Proxy(Proxy.Type.HTTP, new InetSocketAddress("114.231.82.173", 9090)));
proxyMaker.addProxy(new Proxy(Proxy.Type.HTTP, new InetSocketAddress("223.247.46.133", 8089)));
proxyMaker.addProxy(new Proxy(Proxy.Type.HTTP, new InetSocketAddress("114.231.42.16", 9002)));
然后再设置代理生成器,代码如下:
/**
* 代理生成器
*
* @param proxyMaker
* @return Builder
*/
public Builder setProxyMaker(ProxyMaker proxyMaker){
crawler.runConf.setProxyMaker(proxyMaker);
return this;
}
XxlCrawler crawler = new XxlCrawler.Builder().setUrls(urlList).setThreadCount(3).setPauseMillis(2000)
.setProxyMaker(proxyMaker)通过以上的配置大体可以实现一个使用了代理模式访问目标的XxlCrawler。除了待用IP代理池的方式,还可以通过组建爬虫集群,通过分布式来进行批量抓取,这样分散了请求,也能有效应对爬虫,如果计算资源比较充足,可以采用这种方式来进行。
三、XxlCrawler执行解析
本小节将重点介绍XxlCrawler的执行流程,包括相关参数的初始化,对象创建,信息获取等。让大家对XxlCrawler的请求流程及涉及的对象有一个基本的认识。
1、XxlCrawler对象
XxlCrawler是一个比较重的对象,这里采用构建器的模式来进行创建。可以在代码中看到,在XxlCrawler中包含基本的对象和方法。
public class XxlCrawler {
private static Logger logger = LoggerFactory.getLogger(XxlCrawler.class);
// run data
private volatile RunData runData = new LocalRunData(); // 运行时数据模型
// run conf
private volatile RunConf runConf = new RunConf(); // 运行时配置
// thread
private int threadCount = 1; // 爬虫线程数量
private ExecutorService crawlers = Executors.newCachedThreadPool(); // 爬虫线程池
private List<CrawlerThread> crawlerThreads = new CopyOnWriteArrayList<CrawlerThread>(); // 爬虫线程引用镜像
}这里就包含相关的处理线程池和处理线程、数据模型、爬取URL对象。
2、启动对象
可以看到,在创建完XxlCrawler之后,需要调用start方法来进行启动。
/**
* 启动
*
* @param sync true=同步方式、false=异步方式
*/
public void start(boolean sync){
if (runData == null) {
throw new RuntimeException("xxl crawler runData can not be null.");
}
if (runData.getUrlNum() <= 0) {
throw new RuntimeException("xxl crawler indexUrl can not be empty.");
}
if (runConf == null) {
throw new RuntimeException("xxl crawler runConf can not be empty.");
}
if (threadCount<1 || threadCount>1000) {
throw new RuntimeException("xxl crawler threadCount invalid, threadCount : " + threadCount);
}
if (runConf.getPageLoader() == null) {
throw new RuntimeException("xxl crawler pageLoader can not be null.");
}
if (runConf.getPageParser() == null) {
throw new RuntimeException("xxl crawler pageParser can not be null.");
}
logger.info(">>>>>>>>>>> xxl crawler start ...");
for (int i = 0; i < threadCount; i++) {
CrawlerThread crawlerThread = new CrawlerThread(this);
crawlerThreads.add(crawlerThread);
}
for (CrawlerThread crawlerThread: crawlerThreads) {
crawlers.execute(crawlerThread);
}
crawlers.shutdown();
if (sync) {
try {
while (!crawlers.awaitTermination(5, TimeUnit.SECONDS)) {
logger.info(">>>>>>>>>>> xxl crawler still running ...");
}
} catch (InterruptedException e) {
logger.error(e.getMessage(), e);
}
}
}3、信息爬取线程
在前面已经说过,其主要是采取线程池的模式进行爬取。来看一下具体的运行方法,关键代码如下:
public void run() {
while (!toStop) {
try {
running = false;
crawler.tryFinish();
String link = crawler.getRunData().getUrl();
running = true;
logger.info(">>>>>>>>>>> xxl crawler, process link : {}", link);
if (!UrlUtil.isUrl(link)) {
continue;
}
// failover
for (int i = 0; i < (1 + crawler.getRunConf().getFailRetryCount()); i++) {
boolean ret = false;
try {
// make request
PageRequest pageRequest = makePageRequest(link);
// pre parse
crawler.getRunConf().getPageParser().preParse(pageRequest);
// parse
if (crawler.getRunConf().getPageParser() instanceof NonPageParser) {
ret = processNonPage(pageRequest);
} else {
ret = processPage(pageRequest);
}
} catch (Throwable e) {
}
if (crawler.getRunConf().getPauseMillis() > 0) {
try {TimeUnit.MILLISECONDS.sleep(crawler.getRunConf().getPauseMillis());
} catch (InterruptedException e) {
}
}
}
} catch (Throwable e) {
}
}
}可以看到,首先在程序运行前,会根据我们的配置和目标Url构建请求对象。关键代码如下:
/**
* make page request
*
* @param link
* @return PageRequest
*/
private PageRequest makePageRequest(String link){
String userAgent = crawler.getRunConf().getUserAgentList().size()>1
?crawler.getRunConf().getUserAgentList().get(new Random().nextInt(crawler.getRunConf().getUserAgentList().size()))
:crawler.getRunConf().getUserAgentList().size()==1?crawler.getRunConf().getUserAgentList().get(0):null;
Proxy proxy = null;
if (crawler.getRunConf().getProxyMaker() != null) {
proxy = crawler.getRunConf().getProxyMaker().make();
}
PageRequest pageRequest = new PageRequest();
pageRequest.setUrl(link);
pageRequest.setParamMap(crawler.getRunConf().getParamMap());
pageRequest.setCookieMap(crawler.getRunConf().getCookieMap());
pageRequest.setHeaderMap(crawler.getRunConf().getHeaderMap());
pageRequest.setUserAgent(userAgent);
pageRequest.setReferrer(crawler.getRunConf().getReferrer());
pageRequest.setIfPost(crawler.getRunConf().isIfPost());
pageRequest.setTimeoutMillis(crawler.getRunConf().getTimeoutMillis());
pageRequest.setProxy(proxy);
pageRequest.setValidateTLSCertificates(crawler.getRunConf().isValidateTLSCertificates());
return pageRequest;
}在获取到目标页面后,将进行返回值的处理,具体处理逻辑如下:

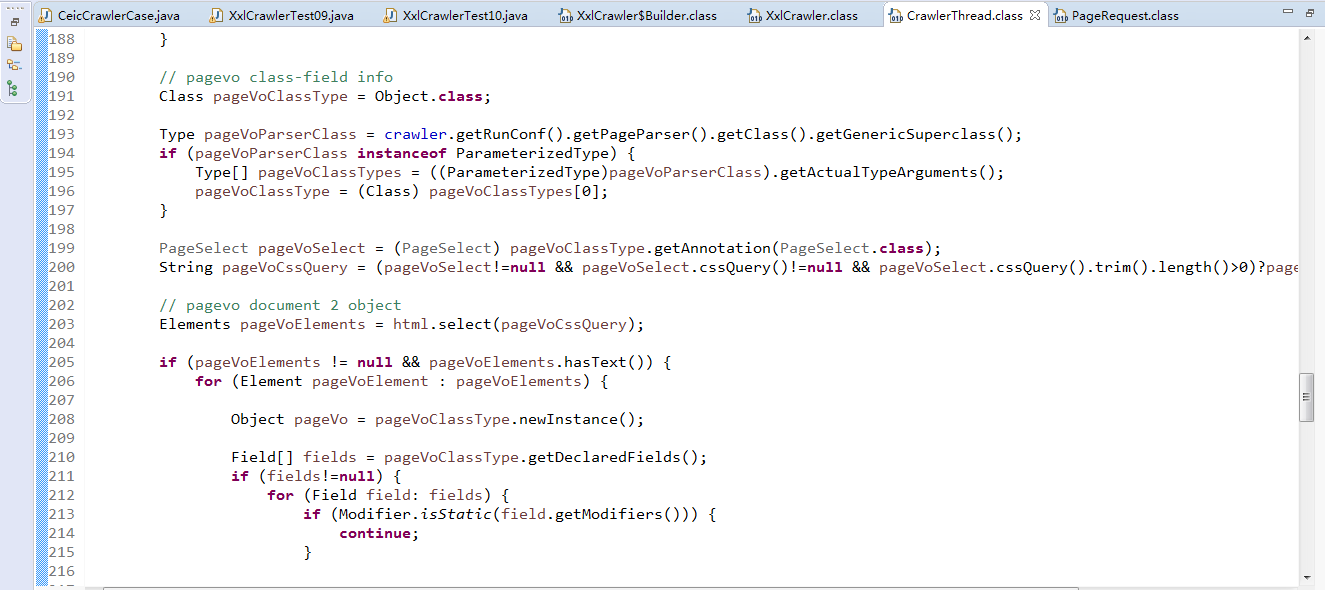
主要是将返回的对象解析到配置的pageVO对象中,并根据pageVO对象中配置的表达式来获取值。感兴趣的朋友可以自己调试这些代码。可以看到更一步的数据处理。
总结
以上就是本文的主要内容,本文以Java开发语言为例,主要讲解在采用XxlCrawler组件进行网络信息获取时,几种常见的反爬策略的应对方式。博文首先介绍了了几种常见的防止爬取技术,然后以XxlCrawer为例,针对这几种策略,在XxlCrawler中是如何进行实现,并进行应对的。行文仓促,难免有不足支持,欢迎各位朋友在评论区批评指正。
最后仍要强调:不要恶意使用爬虫,不要无节制的访问目标网站。对于数据不随便泄露,不做商业用途。
博客写作过程中参考了以下部分网站内容,主要如下:
2、反爬虫技术
标签:
相关文章
最新发布
- 【Python】selenium安装+Microsoft Edge驱动器下载配置流程
- Python 中自动打开网页并点击[自动化脚本],Selenium
- Anaconda基础使用
- 【Python】成功解决 TypeError: ‘<‘ not supported between instances of ‘str’ and ‘int’
- manim边学边做--三维的点和线
- CPython是最常用的Python解释器之一,也是Python官方实现。它是用C语言编写的,旨在提供一个高效且易于使用的Python解释器。
- Anaconda安装配置Jupyter(2024最新版)
- Python中读取Excel最快的几种方法!
- Python某城市美食商家爬虫数据可视化分析和推荐查询系统毕业设计论文开题报告
- 如何使用 Python 批量检测和转换 JSONL 文件编码为 UTF-8
点击排行
- 版本匹配指南:Numpy版本和Python版本的对应关系
- 版本匹配指南:PyTorch版本、torchvision 版本和Python版本的对应关系
- Python 可视化 web 神器:streamlit、Gradio、dash、nicegui;低代码 Python Web 框架:PyWebIO
- 相关性分析——Pearson相关系数+热力图(附data和Python完整代码)
- Python与PyTorch的版本对应
- Anaconda版本和Python版本对应关系(持续更新...)
- Python pyinstaller打包exe最完整教程
- Could not build wheels for llama-cpp-python, which is required to install pyproject.toml-based proj
本站推荐
